







本来早就该发了,一直以为上周发过了。。。
事前吐槽下把,不知道是校网的原因还是服务器的原因,我用校园网连不上比赛服务器,
挂上代理之后能够连上但是又很不方便做题,加上vps有点问题什么的,也就瞬间没了欲望。
整理下一些题的思路把。
由于连不上服务器,python脚本也写不了,所以有些题就只有思路,也不算wp。
加上我个人对题目的理解和分析,由于没有实际做题,如果有问题希望大家指正
web 50
源码里面拿到flag
web 200-1
一个什么流量监控系统,在响应头里面拿到base64编码的tips,如下:
$query="SELECT * FROM admin WHERE uname='".$uname."'";
if ($row['passwd']===$passwd)
{
$_SESSION['flag'] = 1;
过滤了很多,空格、#、*、union、、and、or、|、+,–、&、%0a、%0b、%0c、%0d等等,也就没法用联合查询来绕过什么的,也就直接转想盲注把。
这里我们很容易发现问题所在,并且可以利用来进行盲注
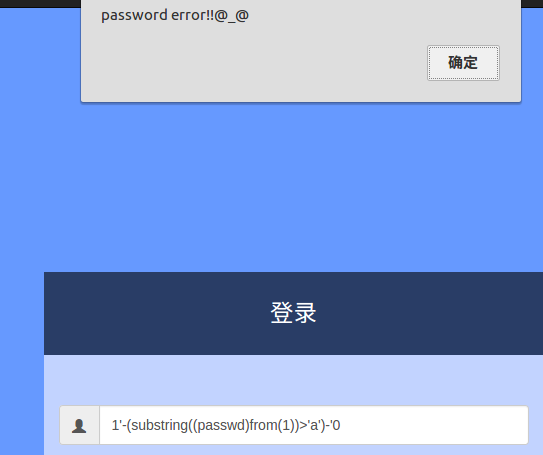
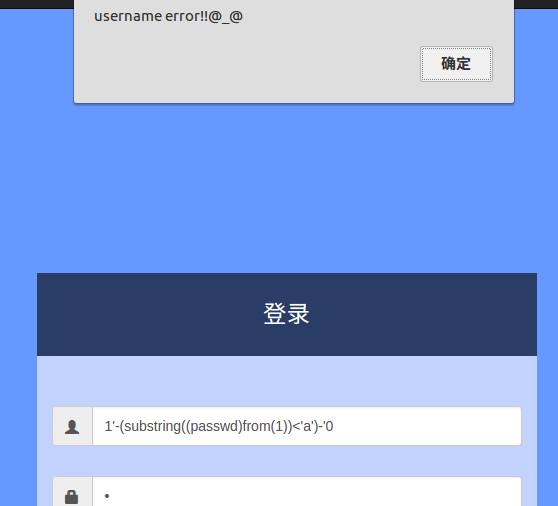
观察上面两张图返回完全不一样的答案,所以写个脚本就能猜解出passwd了
这里脚本我就懒得写了。没有VPS懒得代理了。
web 200-2
也是懒得解决代理问题,
简单扫一下发现存在备份文件。index.php.bak如下:
if(isset($_COOKIE['user']))
{ $login = @unserialize(base64_decode($_COOKIE['user']));
if(!empty($login->pass)){
$status = $login->check_login();
if($status == 1){
$_SESSION['login'] = 1;
var_dump("login by cookie!!!");
}
}
}
感觉少了些什么,不过肯定是个反序列化漏洞,肯定还有其他文件,换个再扫一下发现了一个function.php,而且也是有备份文件的function.php.bak,太多不贴代码了。
就是一个反序列化构造,绕过checksql()函数,然后还是因为网络原因暂时没法儿用burp,也懒得下其他浏览器插件来改cookie,也就没有实际做这道题。
由于最近恰好在做代码审计,发现这个过滤感觉挺像80sec-ids的过滤,刚看完不久
附链接:http://www.cheery.win/?p=119可以用单撇号来bypass。
PS:正常的80sec-ids最初的匹配是
if(preg_match('/[^0-9a-z@._-]{1,}(union|sleep|benchmark|load_file|outfile)[^0-9a-z@.-]{1,}/', $sql))
{
$this->DisplayError("$sql||SelectBreak",1);
}
但是本题的是:
if ($querytype == 'select') {
$notallow1 = "[^0-9a-z@\._-]{1,}(load_file|outfile)[^0-9a-z@\.-]{1,}";
if (preg_match("/".$notallow1."/i", $db_string)) {
exit("Error");
}
}
所以猜测这里多半会用sleep、benchmark什么的把。
接下来这里我结合自己分析下这个改版的80sec-ids把。
首先第一部分
if ($querytype == 'select') {
$notallow1 = "[^0-9a-z@\._-]{1,}(load_file|outfile)[^0-9a-z@\.-]{1,}";
if (preg_match("/".$notallow1."/i", $db_string)) {
exit("Error");
}
}
这里过滤select语句的一些特殊语法,不过这里没有直接过滤sleep和benchmark,所以就有机会bypass。
接下来就是关键部分
while (TRUE) {
$pos = strpos($db_string, '\'', $pos + 1);
if ($pos === FALSE) {
break;
}
$clean.= substr($db_string, $old_pos, $pos - $old_pos);
while (TRUE) {
$pos1 = strpos($db_string, '\'', $pos + 1);
$pos2 = strpos($db_string, '\\', $pos + 1);
if ($pos1 === FALSE) {
break;
}
elseif($pos2 == FALSE || $pos2 > $pos1) {
$pos = $pos1;
break;
}
$pos = $pos2 + 1;
}
$clean.= '$s$';
$old_pos = $pos + 1;
}
这里通过匹配 ‘确定提取出每两个单引号直接的内容,并且将其中的内容通过 substr()函数截断下来,再将剩下来的语句进行匹配,所以只要我们将我们需要的语句藏在 两个单引号之间就OK了
简单的说就是如下图所示,我输入第一行,然后被一通操作搞成第二行的样子然后进行接下来的过滤。

也就是说,下述的过滤代码都是对第二行这样子的进行过滤,所以我们就可以把我们的东西藏在单引号里面来bypass
if (strpos($clean, '@') !== FALSE OR strpos($clean, 'char(') !== FALSE OR strpos($clean, '"') !== FALSE OR strpos($clean, '$s$$s$') !== FALSE) {
$fail = TRUE;
if (preg_match("#^create table#i", $clean)) $fail = FALSE;
$error = "unusual character";
}
elseif(strpos($clean, '/*') !== FALSE || strpos($clean, '-- ') !== FALSE || strpos($clean,  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3547
3547

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









