









378. 有序矩阵中第 K 小的元素 ●●
描述
给你一个 n x n 矩阵 matrix ,其中每行和每列元素均按升序排序,找到矩阵中第 k 小的元素。
请注意,它是 排序后 的第 k 小元素,而不是第 k 个 不同 的元素。
你必须找到一个内存复杂度优于 O(n^2) 的解决方案。
示例
输入:matrix = [[1,5,9],[10,11,13],[12,13,15]], k = 8
输出:13
解释:矩阵中的元素为 [1,5,9,10,11,12,13,13,15],第 8 小元素是 13
题解
1. 堆排序 / 优先队列
从左往右、从上往下遍历矩阵元素,并维护一个大小为 k 的大顶堆,直到遍历结束,返回堆顶元素。
- 时间复杂度: O ( n 2 log k ) O(n^2\log{k}) O(n2logk),进行 n 2 n^2 n2 次堆结构调整。
- 空间复杂度: O ( k ) O(k) O(k),大小为 k 的大顶堆。
class Solution {
public:
int kthSmallest(vector<vector<int>>& matrix, int k) {
int n = matrix.size();
priority_queue<int> pque; // 优先队列
for(int x = 0; x < n; ++x){
for(int y = 0; y < n; ++y){
if(pque.size() < k){
pque.push(matrix[x][y]);
}else{
if(matrix[x][y] < pque.top()){ // 维护大小k的大顶堆
pque.push(matrix[x][y]);
pque.pop();
}
}
}
}
return pque.top();
}
};
2. 归并排序
由题目给出的性质可知,这个矩阵的每一列均为一个有序数组。
问题即转化为从这 n 个有序数组中找第 k 大的数,可以想到利用归并排序的做法,归并到第 k 个数即可停止。
一般归并排序是两个数组归并,而本题是 n 个数组归并,所以需要用小根堆维护,以优化时间复杂度。
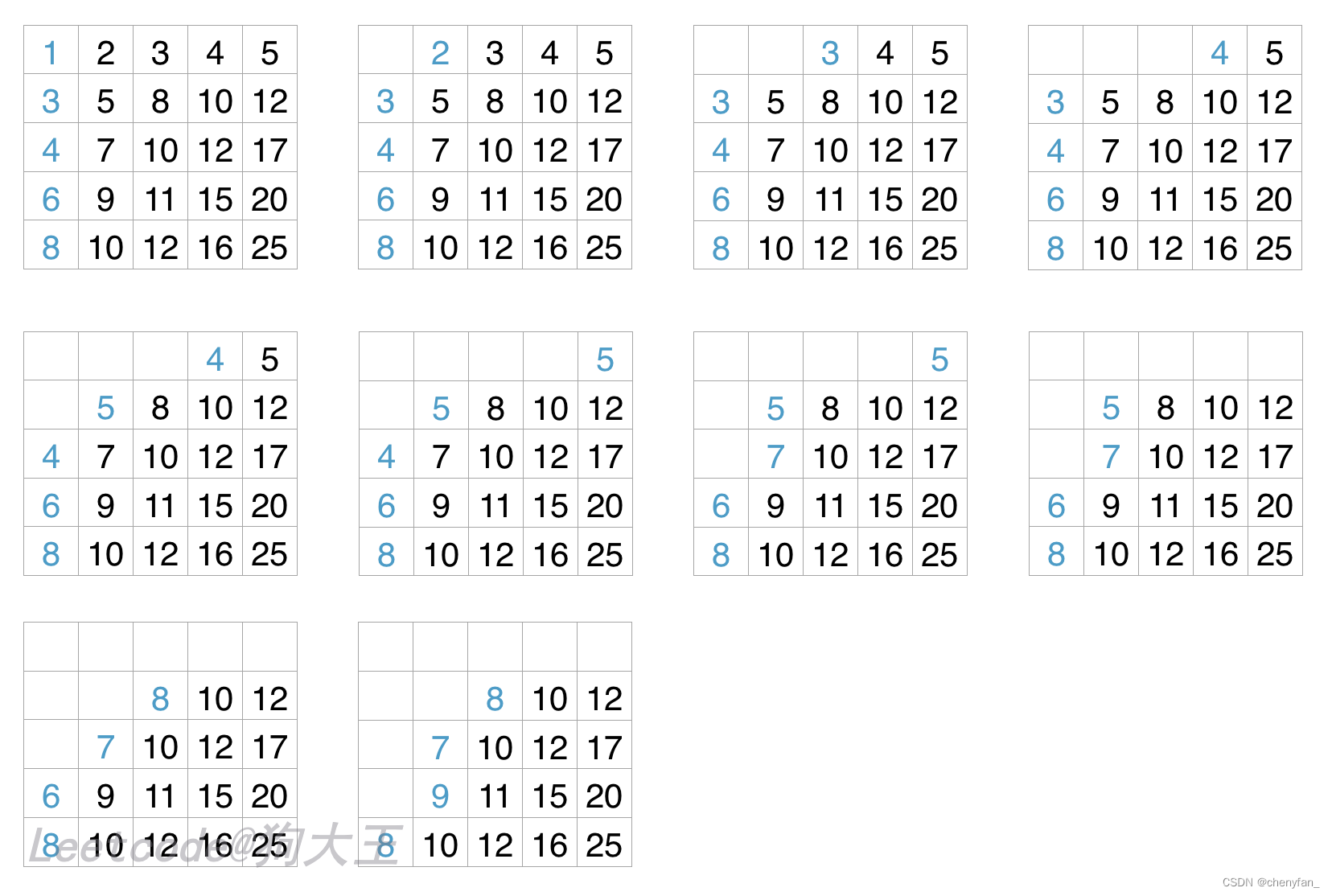
直观思路:
在整个矩阵中,每次弹出矩阵中最小的值,第 k 个被弹出的就是我们需要的数字。
左上角的数字是整个矩阵最小的,
但弹出它后我们如何保证接下来每一次都还能找到全矩阵最小的值呢?
此处,我们用优先队列进行维护一组“最小候选值”,同时优先队列能够帮我们定位此时的最小值。
我们来选择第一组候选人,在这里可以选择第一列,因为每一个数字都是其对应行的最小值,全局最小值也必然在其中。
每次弹出最小值后,将其右边的元素加入到优先队列中,这样能保证候选人列表中每一个数字是每一行的最小值,那全局最小值必然在其中!
为此,我们自定义一个 point 结构体,包含元素值及其所在的坐标;然后利用优先队列进行维护大小为 n 的小顶堆。
- 时间复杂度:
O
(
k
log
n
)
O(k\log{n})
O(klogn),归并 k 次,每次堆中插入和弹出的操作时间复杂度均为
log
n
\log{n}
logn。
需要注意的是,k 在最坏情况下是 n 2 n^2 n2,因此该解法最坏时间复杂度为 O ( n 2 log n ) O(n^2\log{n}) O(n2logn)。 - 空间复杂度: O ( n ) O(n) O(n),堆的大小始终为 n。
class Solution {
private:
struct point{
int x, y, val;
point(int x, int y, int val) : x(x), y(y), val(val) {}
// 重载 operator>
bool operator> (const point& other) const { // 重载方式 1
return this->val > other.val;
}
// friend bool operator> (point p1, point p2) { // 重载方式 2
// return p1.val > p2.val;
// }
};
struct cmp{
bool operator()(point& p1, point& p2) { // 重载方式 3
return p1.val > p2.val;
}
};
public:
int kthSmallest(vector<vector<int>>& matrix, int k) {
int n = matrix.size();
// 在 point 中重载 operator>,然后用内置的std::greater
// priority_queue<point, vector<point>, greater<point>> que; // 小顶堆
priority_queue<point, vector<point>, cmp> que; // 小顶堆
// 初始化:将 matrix 的第一列加入 que 作为初始的「最小候选值」列表
for(int i = 0; i < n; ++i){
point p(0, i, matrix[i][0]);
que.push(p);
}
// 弹出前 k-1 小的值
for(int i = 0; i < k-1; ++i){
point top = que.top();
que.pop();
if(top.x != n-1){ // 当前 (top.x, top.y) 的右边还有数字,将它右边的数 push 到优先队列中
point p(top.x+1, top.y, matrix[top.y][top.x+1]);
que.push(p);
}
}
return que.top().val;
}
};
3. 二分法
前两种方法没有利用矩阵 行 与 列 的有序性。
由题目给出的性质可知,这个矩阵内的元素是从左上到右下递增的(假设矩阵左上角为 m a t r i x [ 0 ] [ 0 ] matrix[0][0] matrix[0][0])。以下图为例:
整个二维数组中 m a t r i x [ 0 ] [ 0 ] matrix[0][0] matrix[0][0] 为最小值, m a t r i x [ n − 1 ] [ n − 1 ] matrix[n - 1][n - 1] matrix[n−1][n−1] 为最大值,现在我们将其分别记作 l 和 r。
可以发现一个性质:任取一个数 mid 满足 l ≤ m i d ≤ r l≤mid≤r l≤mid≤r,那么矩阵中不大于 mid 的数,肯定全部分布在矩阵的左上角。
矩阵中大于 mid 的数就和不大于 mid 的数分别形成了两个板块,沿着一条锯齿线将这个矩形分开。
其中左上角板块的大小即为矩阵中不大于 mid 的数的数量。
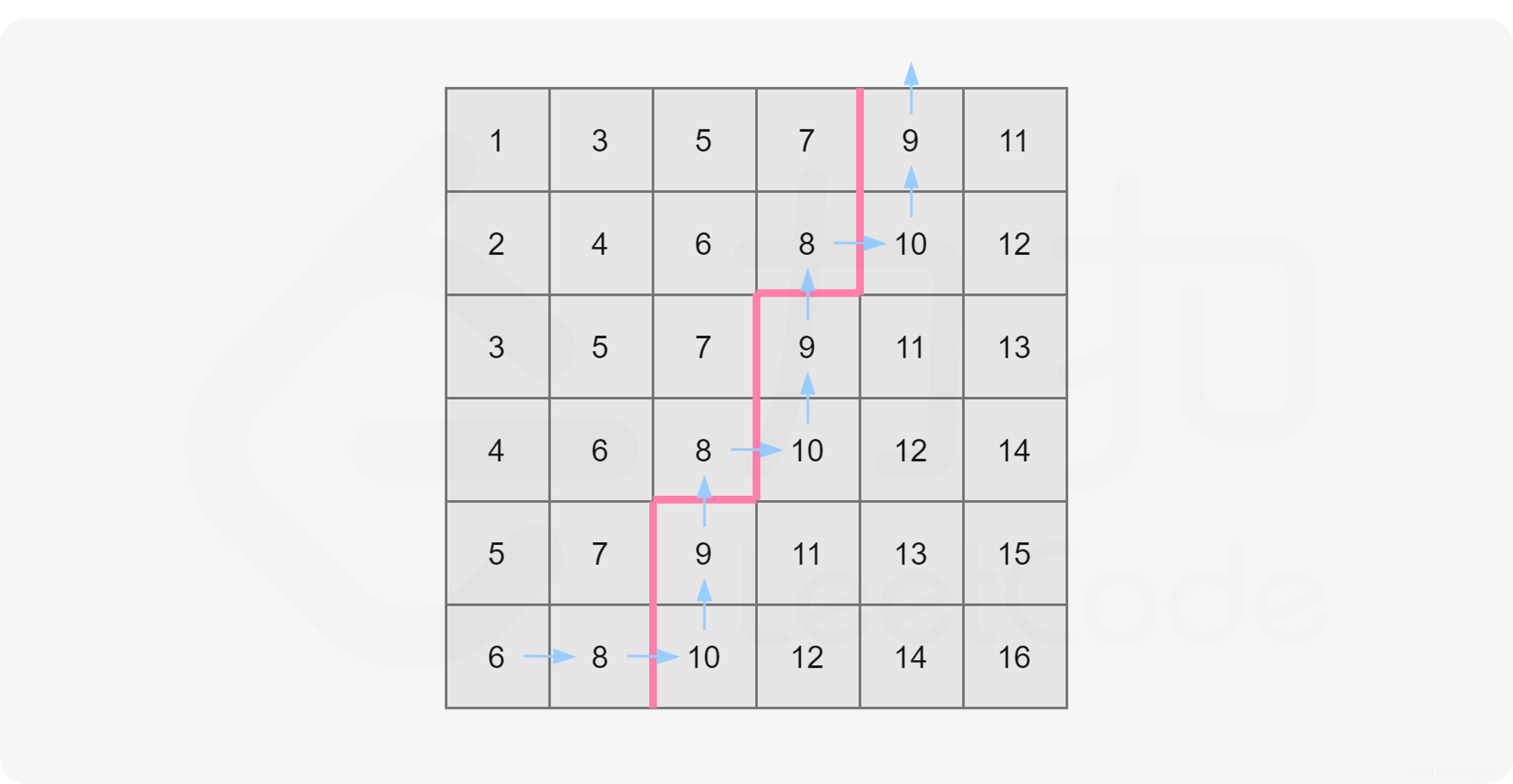
我们只要从左下角出发,沿着这条锯齿线走一遍即可计算出这两个板块的大小,也自然就统计出了这个矩阵中不大于 mid 的数的个数了。
这样的走法时间复杂度为 O(n),即我们可以线性计算对于任意一个 mid,矩阵中有多少数不大于它。这满足了二分查找的性质。
不妨假设答案为 x,那么可以知道 l ≤ x ≤ r l≤x≤r l≤x≤r,这样就确定了二分查找的上下界。
每次对于「猜测」的答案 mid,计算矩阵中有多少数不大于 mid :
- 如果数量不少于 k,那么说明最终答案 x 不大于 mid;
- 如果数量少于 k,那么说明最终答案 x 大于 mid。
这样我们就可以计算出最终的结果 x 了。
- 时间复杂度: O ( n log ( r − l ) ) O(n\log(r-l)) O(nlog(r−l)),二分查找进行次数为 O ( log ( r − l ) ) O(\log(r-l)) O(log(r−l)),每次操作时间复杂度为 O ( n ) O(n) O(n)。
- 空间复杂度:O(1)。
class Solution {
public:
int check(vector<vector<int>>& matrix, int mid){
int n = matrix.size();
int x = 0, y = n-1;
int num = 0;
while(x < n && y >= 0){
if(matrix[y][x] <= mid){
num += y+1; // 当前列的个数
++x; // 下一列
}else{
--y; // 缩小当前列
}
}
return num; // 矩阵中不大于 mid 的元素个数
}
int kthSmallest(vector<vector<int>>& matrix, int k) {
int n = matrix.size();
int l = matrix[0][0], r = matrix[n-1][n-1]; // 左右边界 [l, r]
while(l <= r){
int mid = (l + r) >> 1;
if(check(matrix, mid) >= k){ // 矩阵中不大于 mid 的元素个数 大于等于 k 个,缩小右边界
r = mid - 1;
}else{
l = mid + 1;
}
}
return l; // 第一个大于等于 k 的数,即第 k 小的元素
}
};














 760
760











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









