









目录
前言
在进行数据库投产的时候,会经常遇到这几个指令,对于他们的用法,在这里进行一个详细的说明,以供大家参考学习。
1、Runstats的用法
1.1 什么是Runstats?
RUNSTATS 是 DB2® Universal Database™中的实用程序,它更新优化器为确定存取数据的最快路径所使用的目录统计信息。DB2 优化器使用目录统计信息来确定最佳的访问路径,而更新这些目录统计信息所采用的主要方法就是运行 RUNSTATS 实用程序。当用户表中发生数据修改时,目录统计信息表不会自动被修改。必须在表和索引上执行 RUNSTATS 命令,用最新的信息更新目录表中的列。runstats命令就是用来收集数据库对象的状态信息,这对优化器生成最优的执行计划至关重要。
1.2 用法
runstats on table [模式名].[表名] with distribution and detailed indexes all注意:你可以在所有列上,或者仅仅在某些列或列组(除了LONG和LOB列)上执行RUNSTATS。如果没有指定特定列的子句,系统则会使用默认的ON ALL COLUMNS子句。当已确定表中包含不是统一分布的数据时,可以运行包含WITH DISTRIBUTION子句的RUNSTATS。使用WITH DISTRIBUTION子句还可以帮助查询处理没有参数标志符(parameter marker)或主机变量的谓词,因为优化器仍然不知道运行时的值是有许多行,还是只有少数行。
如果为单一索引进行runstats,可以使用:
runstats on table [模式名].[表名] for indexes [索引名]1.3 存在的问题
在第一次将数据载入到表中之后,就无法避免地要对表进行更新、删除和插入等形式的修改。可以添加或删除索引。特定列中的数据分布可能随时间发生改变。目录中不会反映这些修改,除非在这些表和索引上执行 RUNSTATS。一段时间之后,随着表和数据发生更改,目录统计信息可能会过时。
执行 RUNSTATS 是很重要的,但是频繁地运行可能会带来问题。对于较小的表,发出 RUNSTATS 命令将是一项普通任务。然而,随着表的增长,完成 RUNSTATS 命令将占用更多时间、CPU 和内存资源。最终,您必须考虑分配更多时间和资源来运行 RUNSTATS 与不执行该命令的潜在性能下降之间的平衡。通常只在关键查询的速度开始减慢时,管理员才会对 RUNSTATS 给予适当的注意。您可以通过制定高效、有效收集统计信息的策略,避免未经思考就调优查询和执行 RUNSTATS。
1.4 使用情况
理论上,应该在下列情况下对表和索引执行 RUNSTATS:
- 将数据载入表中并创建了合适的索引之后。不过,最好是在创建索引之后再执行 LOAD 命令,并在 LOAD 期间收集统计信息。
- 创建了一个新的索引之后。
- 使用 REORG 实用程序重新组织表之后。
- 通过数据更新、删除和插入大量更新表及其索引之后。
- 更改了预取(prefetch)大小之后。
- 运行 REDISTRIBUTE DATABASE PARTITION GROUP 实用程序之后。
注意:在 RUNSTATS 语法中,必须使用全限定的表名 schema.table-name 和全限定的索引名 schema.index-name。您可以在所有列上,或者仅仅在某些列或列组(除了 LONG 和 LOB 列)上执行 RUNSTATS。如果没有指定特定列的子句,系统则会使用默认的 ON ALL COLUMNS 子句。
1.5 运用策略
您可以使用下列策略来帮助减小 RUNSTATS 对于系统的性能影响:
- 一次仅在少数表和索引上运行 RUNSTATS,在整组表中循环运行。
- 仅指定将收集其数据分布统计信息的那些列。仅指定那些谓词中所使用的列。
- 对于不同的表,在不同的分区上实现多个并发的 RUNSTATS。
- 仅在那些影响当前工作负载的关键表上执行 RUNSTATS。避免在不需要它的表上运行 RUNSTATS。
- 根据表中数据发生改变的速度,调整 RUNSTATS 的频率。
- 根据 RUNSTATS 在该表上完成运行的速度,调整 RUNSTATS 的频率和细节。
- 仅在系统活动量少的时候,安排执行 RUNSTATS。
- 调整(Throttle)RUNSTATS,以便最大程度地减少它对系统的需求。
仅在系统活动量少的时候安排执行 RUNSTATS,这是最大程度地减少系统影响的一个好方法。然而,对于一个 24 x 7 的系统,系统中可能没有可用的窗口或活动量少的时候。处理该情形的一种方法就是使用 RUNSTATS 的 throttling 选项。throttling 选项将根据当前的数据库活动级别,来限制实用程序所占有的资源数量。
2、数据移动Export、Import和Load的用法
2.1 数据移动的手段
DB2的数据移动手段,可以分为逻辑结构层面的数据移动和物理结构层面的数据移动:逻辑结构层面的数据移动主要是指数据库对象的变化,和业务关联性很大;物理结构层面的数据移动主要在于数据底层存储位置的变化,比如表空间路径的变化,或数据库整体被物理地搬到另一台机器上。
逻辑结构层面数据移动方法:
| 级别 | 名称 | 方式 |
|---|---|---|
| 单表级别 | 导出(EXPORT) | 使用SELECT语句或XQuery语句抽取数据,并将其放到文件中 |
| 单表级别 | 导入(IMPORT) | 使用INSERT语句向表、类型表(使用用户自定义类型而建立的表)或试图 填充数据 |
| 单表级别 | LOAD导入 | 能够高效地将大量数据导入到表中。LOAD导入速度快于IMPORT |
| 单表级别 | 表移动存储过程(ADMIN_MOVE_TABLE) | DB2 V9.7中新出现的存储过程。它能够在不影响系统可用性的情况下把表从一个空间移动到另一个表空间 |
| 多表级别 | DB2MOVE | 通常用于跨平台迁移数据库 |
| 复制模式存储过程(ADMIN_COPY_SCHEMA) | 将同一个数据库中某模式(SCHEMA)中的队形和数据复制到另外一个模式中 |
物理结构层面数据移动方法:
| 名称 | 方式 |
|---|---|
| 数据库备份与恢复 | 如果两个平台是二进制兼容的,那么可以使用一个平台的备份,在另外一个平台恢复,从而实现数据库在平台间的移动。另外,可以将低版本的数据库备份恢复到高版本实例中,比如可以将DB2 V9.1的数据库备份恢复到DB2 V9.5的实例中,这实现了恢复过程中数据库的升级 |
| 重定向恢复 | 在使用数据库备份恢复的时候,可以改变目标数据库的物理存储位置 |
| 重定位数据库(db2relocatedb) | 通过修改数据库控制文件,来重命名数据库或者改变数据库的存储路径,从而实现数据移动的目标。不过,数据库对象的变化需要手动完成。执行这个实用程序时,数据库实例必须处于停止状态 |
2.2 导入导出文件类型
DEL:界定的ASCII文件,行分隔符与列分隔符将数据分开
ASC:定长的ASCII文件,行按照行分隔符分开,列定长
PC/IXF:只能用在DB2之间导数据,根据类型数字值被打包成十进制或者二进制,字符被保存为ASCII,只保存变量已经使用的长度,文件中包括表的定义和表的数据
WSF:工作表方式导入导出,这种格式的文件类型用的比较少
DB2中对不同的数据导入导出方式,支持不同的文件类型:
| 文件类型 | Import | Export | Load |
| 定界 | 支持 | 支持 | 支持 |
| 非定界 | 支持 | 不支持 | 支持 |
| ixf | 支持 | 支持 | 支持 |
| wsf工作表 | 支持 | 支持 | 不支持 |
关于3种导入导出操作进行简单的介绍:
export:导出数据,支持IXF,DEL或WSF
import:导入数据,可以向表中导入数据,支持上面提到的4种文件类型。
load:导入数据,功能和import基本相同。如上表。
2.3 Export、Import和Load的用法
2.3.1 Export
语法格式如下:
EXPORT TO file_name OF file_type
MODIFIED BY file_type_modifiers
MESSAGES message_file
selet_statement释义:
file_type 包含的格式有:DEL、IXF、WSF等
message_file用于保存export过程中输出的信息
select_statement表示选择导出数据语句
file_type_modifiers是指文件类型修饰符,常见的文件类型修饰符如下:
- CHARDELx:x表示用来指定的字符串定界符。默认值是双引号(“”)。
- COLDELx :x表示的列定界符。默认值是双引号(,)。
- CODEPAGE=x:x用来表示将字符串导入文本数据时使用的编码。
- Timestampformat=”x”:x是源表中时间戳记的格式。(YYYY/MM/DD HH:MM:SS.UUUUUU、YYYY/MM/DD HH、YYYY-MM-DD HH:MM:SS TT、MMM DD YYYY HH:MM:SS:UUUTT、MMM DD YYYY HH:MM:SSTT)
在EXPORT中使用文件修饰符的方法如下:MODIFIED BY chardel! Coldel# codepage=1208 timestampformat=\"yyyy.mm.dd hh:mm\"
示例:
db2 "EXPORT TO /file_path/test.del OF DEL MESSAGES msg.out SELECT * from test"- select后面是可以加各种条件的,如select c3 from test where c1='100'
- EXPORT不支持ASC文件格式
- file_name所在文件夹应该具有写和读的权限
- file_name不用事先建立,会自动生成
- file _name的格式 由 of del 选项决定,而不是file_name的后缀名。如,可以写成:test.txt of del、test.csv of del、test.ixf ofixf等
2.3.2 Import
语法格式如下:
IMPORT FORM file_name OF { IXF | ASC | DEL | WSF}
MODIFIED BY file_type_modifiers
[ METHOD {
L (col-start col-end ) [null indicators (col-position ] |
N (col-name ) |
p (col-position)
}]
ALLOW { NO | WRITE } ACCESS
COMMITCOUNT { n | AUTOMATIC}
RESTARTCOUNT | SKIPCONT
ROWCONT n
MESSAGES message_file
[ INSERT | INSERT_UPDATE | REPLACE | REPLACE_CREATE | CREATE]
INTO target_table_name释义:字段过滤
在导入的时候可以选择只导入部分字段的数据,这需要在IMPORT中使用METHOD选项。METHOD选项有三种:METHOD L、METHOD N、METHOD P。下表是三种方式的区别
| 名称 | 适用的文件格式 | 带的参数 |
|---|---|---|
| METHOD L | ASC文件 | 起始位置和终止位置 |
| METHOD N | IXF文件 | 字段名称 |
| METHOD P | DEL文件和IXF文件 | 字段位置(从1开始) |
示例:字段过滤示例语句如下
* 使用METHOD L 进行导入
db2 "IMPORT from /data/xin/loadtest/test.asc of ASC METHOD L(1 5,10 12,20 30) messages msg.out insert into mytab1(c1,c2,c4)"* 使用METHOD N 进行导入
db2 "load from /data/xin/loadtest/test.ixf of ixf method N(C2,C1,C3) insert into mytab1(c1,c2,c4)"* 使用METHOD P 进行导入
db2 "load from /data/xin/loadtest/test.del of del method P(2,1,3) insert into mytab1(c2,c1,c4)"2.3.3 Load
用法与Import相似。
3、Reorg的用法
3.1 什么是Reorg?
当数据库里某个表中的记录变化量很大时,需要在表上做REORG操作来优化数据库性能。简单地说就是运行ALTER TABLE时要注意当前运行的语句是否需要执行REORG操作,对于有些ALTER TABLE语句,如果不执行REORG操作的话,基本上目标表就不再可用。
3.2 语法
值得注意的是,针对数据库对象的大量操作,如反复地删除表,存储过程,会引起系统表中数据的频繁改变,在这种情况下,也要考虑对系统表进行REORG操作。一个完整的REORG表的过程应该是由下面的步骤组成的:
RUNSTATS -> REORGCHK -> REORG -> RUNSTATS -> BIND或REBIND
REORG TABLE table-name3.3 示例
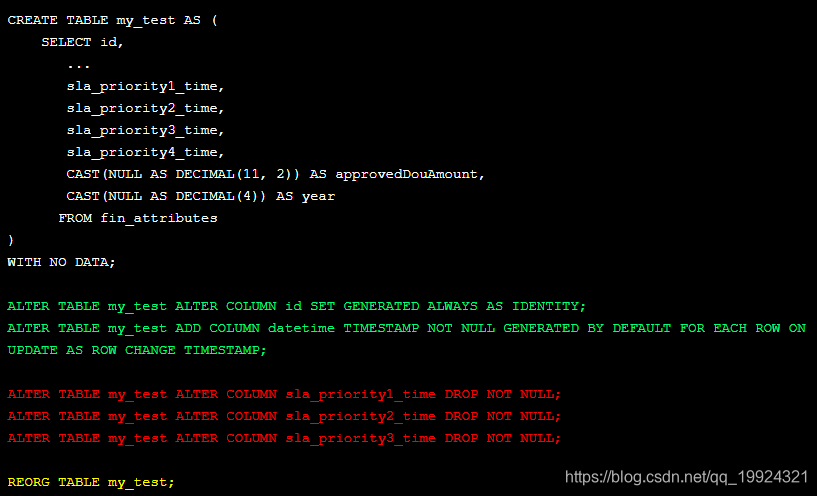
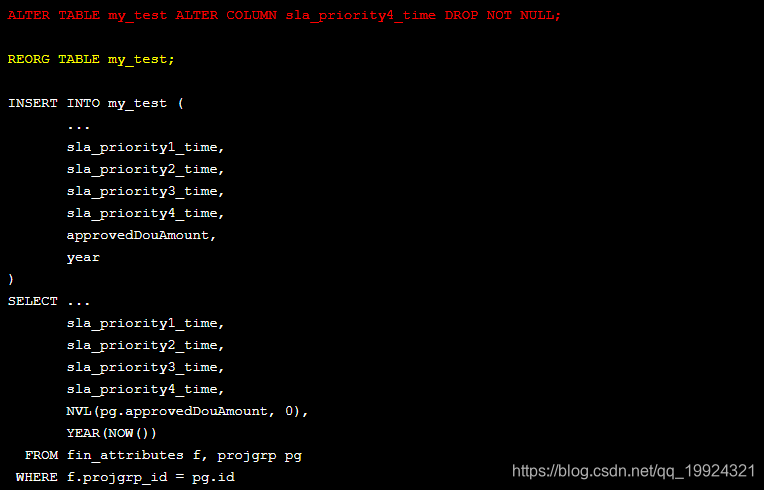
以上代码有四种颜色,绿色代表不需要执行REORG的语句,红色代表需要执行REORG的语句,黄色是REORG语句。从代码上可以看出,红色高亮语句虽然要求使用REORG,但不及时运行REORG还可以让后续的几个语句继续执行。原因是DB2允许最多三条语句处于Reorg Pending状态,假如去除第一个REORG,语句“ALTER TABLE my_test ALTER COLUMN sla_priority4_time DROP NOT NULL;”就会执行失败。
结论:如果不确定那个是需要REORG哪个是不需要REORG,索性都用上REORG;虽然在允许有三条语句处于Reorg Pending状态,但最好每条ALTER TABLE对应一个REORG,因为处于Reorg Pending状态的表有可能会阻碍后续操作。
4、Comment的用法
给表和列增加注释,用法如下:
表注释的添加
comment on table [表名] is '注释内容';列注释的添加
comment on column [表名].[字段名] is '注释内容';例如:comment on column g_toba.my_sex is ' 01-男,02-女';
说明:列注释如果修改修改的话,改变注释内容,重新执行这个语句就行了

















 3540
3540

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









