







前言
前面我们讲了传统的神经网络,如MLP、CNN,这些网络中的输入都被单独处理,没有上下文之间的信息传递机制,这在处理序列数据(如语音、文本、时间序列)时很鸡肋:
- 如何理解一句话中“前后文”的含义?
- 如何预测下一个时刻的股价?
- 如何让模型记住历史信息?
为了解决现实世界中的序列建模问题,循环神经网络应运而生。
一、什么是RNN?
其实RNN就是一种带有“记忆功能”的神经网络架构,它能够处理长输入序列,在每个时刻都利用前一时刻的隐藏转态作为“上下文信息”。也可以说,RNN就是一个隐变量模型,隐变量转态是一个向量,RNN做的就是如何更新这个向量。
假设现在有一条文本:“你好,明天!”,使用RNN预测下一个词,则RNN中隐变量的更新如下如所示:
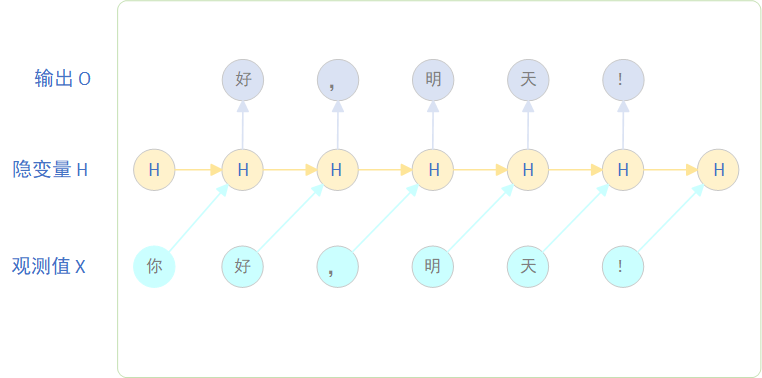
其中,前一个隐藏转态:,需要当前输入:
,当前隐藏转态为:
二、RNN的数学原理
其实RNN的核心公式很简单,前面我已经说过,RNN其实就是一个隐变量模型,隐变量转态是一个向量,RNN就是如何更新这个隐变量向量。
具体隐状态更新公式如下:
其中:
:输入到隐藏的权重
:隐藏到隐藏的权重
:隐藏到输出的权重
三、手写一个简单的RNN
我们已经知道了RNN隐转态具体的更新流程,接下来,我来手写一个最简单的RNN:
1. 初始化参数
我先初始化所需要更新的参数:
import torch
def params(input_size, output_size, hidden_size):
W_xh = torch.randn((input_size, hidden_size)) * 0.1
W_hh = torch.randn((hidden_size, hidden_size)) * 0.1
b_h = torch.zeros(hidden_size)
W_ho = torch.randn((hidden_size, output_size)) * 0.1
b_o = torch.zeros(output_size)
params = [W_xh, W_hh, b_h, W_ho, b_o]
for param in params:
param.requires_grad=True
return params2. 初始化隐藏转态
因为在0时刻时,没有隐藏转态,因此我们需要初始化一个隐藏状态:
def init_state(batch_size, hidden_size):
return (torch.zeros((batch_size, hidden_size))3. 隐状态更新
import torch
def rnn(X, state, params):
W_xh, W_hh, b_h, W_ho, b_o = params
H = state
outputs = []
for x in X:
H = torch.tanh(torch.mm(x, W_xh) + torch.mm(H, W_hh) + b_h)
O = torch.mm(H, W_ho) + b_o
outputs.append(O)
return torch.cat(outputs, dim=1), (H, )4. 总的架构
接下来,将所有的模块整合在一起:
import torch
import torch.nn as nn
import torch.nn.functional as F
def params(input_size, output_size, hidden_size):
W_xh = torch.randn((input_size, hidden_size)) * 0.1
W_hh = torch.randn((hidden_size, hidden_size)) * 0.1
b_h = torch.zeros(hidden_size)
W_ho = torch.randn((hidden_size, output_size)) * 0.1
b_o = torch.zeros(output_size)
params = [W_xh, W_hh, b_h, W_ho, b_o]
for param in params:
param.requires_grad(True)
return params
def init_state(batch_size, hidden_size):
return (torch.zeros((batch_size, hidden_size))
def rnn(X, state, params):
W_xh, W_hh, b_h, W_ho, b_o = params
H = state
outputs = []
for x in X:
H = torch.tanh(torch.mm(x, W_xh) + torch.mm(H, W_hh) + b_h)
O = torch.mm(H, W_ho) + b_o
outputs.append(O)
return torch.cat(outputs, dim=1), (H, )
class myrnn(nn.Module):
def __init__(self, input_size=None, output_size=None, hidden_size=None, params=None, init_state=None, fn=None):
self.input_size = input_size
self.output_size = output_size
self.hidden_size = hidden_size
self.params = params(self.input_size, self.output_size, self.hidden_size)
self.init_state = init_state
self.fn = fn
def __call__(self, X, state):
X = F.one_hot(X.T, self.input_size).type(torch.float32)
return self.fn(X, state, self.params)
def state(self, batch_size):
return self.init_state(batch_size, self.hidden_size)
# 示例
hidden_size = 256
input_size = output_size = 10
X = torch.arange(10).reshape(2,5)
model = myrnn(input_size=input_size, output_size=output_size, hidden_size=hidden_size, params=params, init_state=init_state, fn=rnn)
state = model.state(X.shape[0])
output, new_state = model(X, state)
print(output.shape)
四、使用Pytorch实现
Pytroch中已经内置了RNN模块,在实际应用中,我们只需要调用相应的RNN即可,接下来我简单演示一下:
import torch
import torch.nn as nn
class Rnn(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(Rnn, self).__init__()
self.rnn = nn.RNN(input_size, hidden_size, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x, h0):
out, hn = self.rnn(x, h0)
out = self.fc(out)
return out, hn
# 示例
model = Rnn(input_size=10, hidden_size=256, output_size=10)
x = torch.randn(1,5,10)
h0 = torch.zeros(1,1,256)
output, hn = model(x, h0)
print(output.shape, hn.shape)五、RNN的优缺点
RNN相比与MLP与CNN来说,能够更好的处理序列类型数据,能够捕捉时间序列的上下文信息,并且结构简答,但是缺点也很明显:
- 梯度消失/爆炸:难以捕捉长距离依赖
- 训练速度慢:时间步多时训练不稳定
RNN的缺点限制了它的使用环境,为了解决RNN所具有的问题,LSTM和GRU相继被提出,我将在下一篇内容中详细解释LSTM。
六、总结
以上就是本文的全部内容,相信小伙伴们读到这里已经对RNN的原理十分了解了:RNN为序列建模打开了新纪元,它通过隐藏转态在时间维度上传递“记忆”,成为自然语言处理与时间序列建模的基础架构。尽管其在长序列建模上容易造成梯度爆炸等问题,但仍在很多场景中大方光彩。
如果小伙伴们觉得本文对各位有帮助,欢迎:👍点赞 | ⭐ 收藏 | 🔔 关注。我将持续在专栏《人工智能》中更新人工智能知识,帮助各位小伙伴们打好扎实的理论与操作基础,欢迎🔔订阅本专栏,向AI工程师进阶!

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









