







 本文介绍了一种使用Python爬取东方财富网股吧信息的方法,包括如何解析网页结构、提取股票数据及实现定时任务。通过分析网页源码,利用XPath抓取关键信息,并解析异步加载的数据,最终实现了自动化爬取股票热度、成交量等指标。
本文介绍了一种使用Python爬取东方财富网股吧信息的方法,包括如何解析网页结构、提取股票数据及实现定时任务。通过分析网页源码,利用XPath抓取关键信息,并解析异步加载的数据,最终实现了自动化爬取股票热度、成交量等指标。
打开http://guba.eastmoney. om/点击 热门个股吧 里面的更多
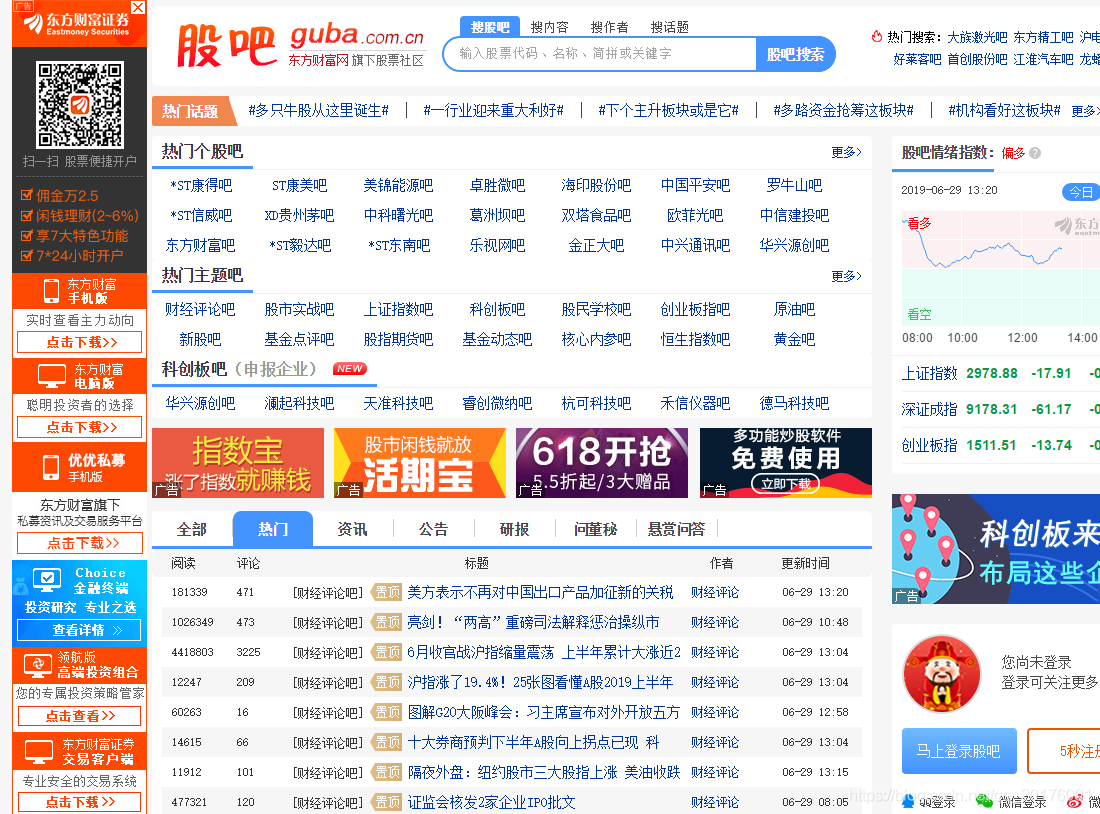
进入到这个界面,可以看到股票基本上有了,然后点击F12,打开网页源码
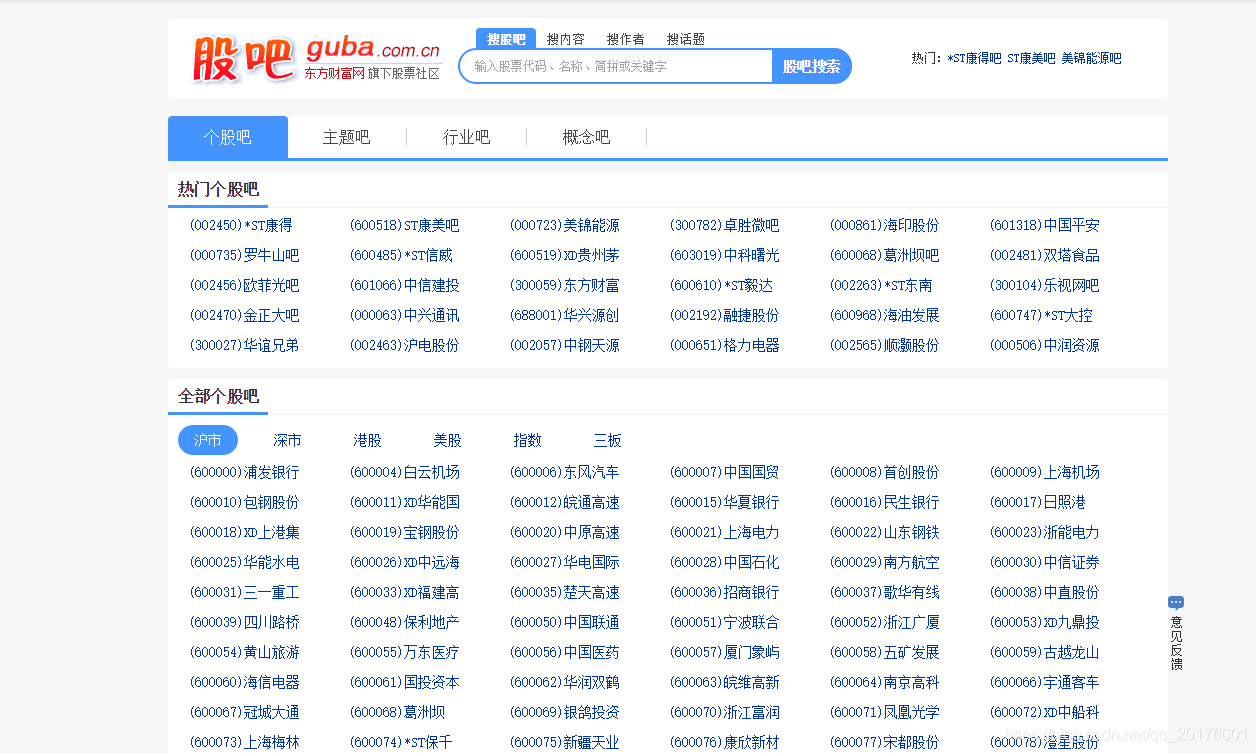
首先可以查看菜单也就是泸市,深市那一块

然后 为了方便,干脆就直接列出如下的起始地址
'http://guba.eastmoney.com/remenba.aspx?type=1&tab=1'
"http://guba.eastmoney.com/remenba.aspx?type=1&tab=2",
"http://guba.eastmoney.com/remenba.aspx?type=1&tab=3",
"http://guba.eastmoney.com/remenba.aspx?type=1&tab=4",
"http://guba.eastmoney.com/remenba.aspx?type=1&tab=5",
"http://guba.eastmoney.com/remenba.aspx?type=1&tab=6"接着看每一个菜单对应下面的具体股吧的信息

可以 看出,网页市分成 两块进行展示的,也就是ngblistul2和 ngblistul2 hide 对应的ul下
如下

以及点击 查看更多 之后的其他的股吧

我们点开其中一个之后查看下面的网页结构
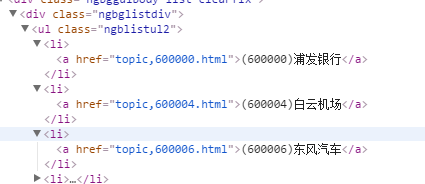
也就是<a>标签里面的href就是我们想要的信息
记得将 ngblistul2和 ngblistul2 hide下的href拼接起来
list = response.xpath('/html/body/div[1]/div[5]/div[2]/div[1]/div/ul[1]/li')
list2 = response.xpath('/html/body/div[1]/div[5]/div[2]/div[1]/div/ul[2]/li')
list.extend(list2)获取到股吧的对应的网址之后,我们点开其中一个网页http://guba.eastmoney.com/list,600000.html
有这样一些信息
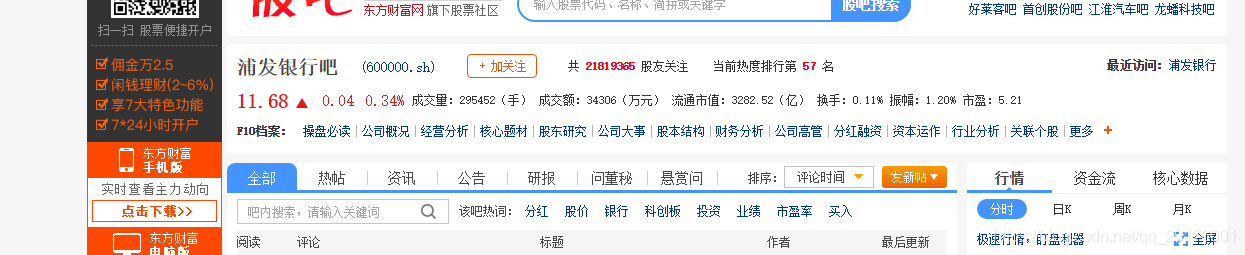
也就是我们要爬去到的信息

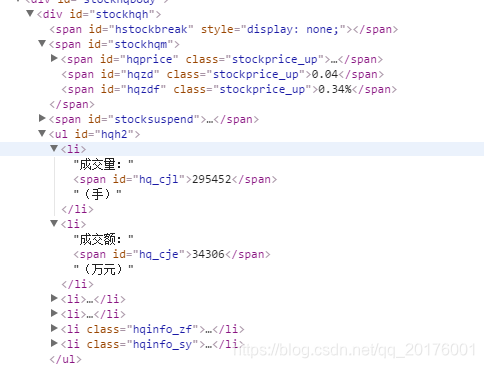
打开网页源码
可以很容易看到我们要获取的信息,但这里那就是个坑
那就是能直接获取的只有股吧 名,像成交量涨幅 什么的并不能直接爬去到,后来 我重新加载了一下网页之后
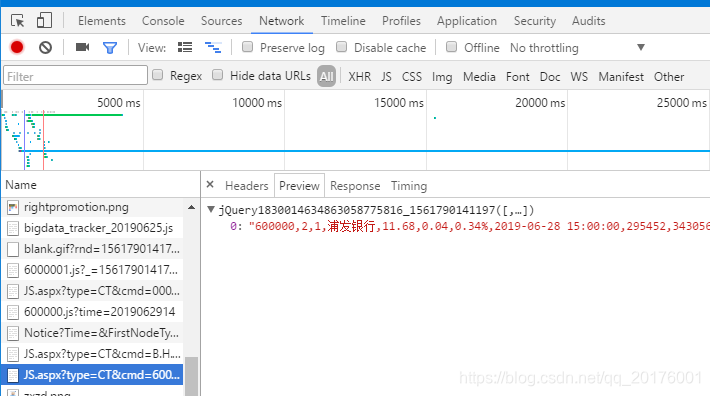
找到了他异步获取数据的请求

由于不清楚这些参数有啥用,所以 只能 去看一下js源码
最后发现参数只需要更改 cmd 的 就可以了
那么 问题来了,cmd的 参数如何设置才合理了,因为股票编号和cmd的貌似不太一样
于是直接查找了一下网页源码中 6000001 所在的位置,发现存在于一个script就 存在了我们需要的信息

也就是里面的 quotecode就是 我们需要的cmd 参数,用如下进行提取
quoteCode = response.xpath('//*/script').re(r"var QuoteCode = \"(.*)\";")[0]提取之后就是模拟发送请求了
quoteURL = "http://nufm.dfcfw.com/EM_Finance2014NumericApplication/JS.aspx?type=CT&cmd=" + quoteCode + "&sty=FDFGBTB&st=z&sr=&p=&ps=&lvl=&cb=?&js=&token=5c46f660fab8722944521b8807de07c0";
getres = self.send(quoteURL)
tt=str(getres.decode('utf8')[4:-3]).split(",")
print(tt)def send(self,url):
req = request.Request(url=url, headers=self.headers)
res = request.urlopen(req)
res = res.read()
return res
# 输出内容(python3默认获取到的是16进制'bytes'类型数据 Unicode编码,如果如需可读输出则需decode解码成对应编码):b'\xe7\x99\xbb\xe5\xbd\x95\xe6\x88\x90\xe5\x8a\x9f'
print(res.decode(encoding='utf-8'))
# 输出内容:登录成功
好了,基本上就是这些了
接下来 直接给代码把
首先是一个start.py脚本,用来定时启动爬虫,在指定时间点运行
import datetime
import time
from scrapy import cmdline
def doSth(hour,min):
# 把爬虫程序放在这个类里 zhilian_spider 是爬虫的name
straa = 'scrapy crawl eastmoney -o ' + str(hour)+str(min)+".csv"
cmdline.execute(straa.split())
# 想几点更新,定时到几点
def time_ti():
while True:
now = datetime.datetime.now()
# print(now.hour, now.minute)
if now.hour == 9 and now.minute == 30:
doSth(9,30)
if now.hour == 14 and now.minute == 30:
doSth(14,30)
if now.hour == 22 and now.minute == 0:
doSth(22,00)
# 每隔60秒检测一次
time.sleep(60)
if __name__ == '__main__':
time_ti()
然后是item.py
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class EastmoneyspiderItem(scrapy.Item):
# define the fields for your item here like:
# 股票名字
name = scrapy.Field()
# 股票编码
id = scrapy.Field()
# 关注量
man_number = scrapy.Field()
# 当前热度排行
now_hot = scrapy.Field()
# 最新
latest = scrapy.Field()
# 涨跌
zhangdie = scrapy.Field()
# 涨幅
zhangfu = scrapy.Field()
# 成交量
chengjiaoliang = scrapy.Field()
# 成交额
chengjiaoe = scrapy.Field()
# 流通市值
shizhi = scrapy.Field()
# 换手
huanshou = scrapy.Field()
# 振幅
zhenfu = scrapy.Field()
# 市盈
shiying = scrapy.Field()
pass
eastmoneyspider\spiders\eastmoney.py,也就是爬取流程
# -*- coding: utf-8 -*-
import re
import time
import scrapy
from urllib import parse,request
from eastmoneyspider.items import EastmoneyspiderItem
class eastmoneySpider(scrapy.Spider):
name = 'eastmoney'
allowed_domains = ['guba.eastmoney.com']
data = []
# 浏览器用户代理
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3704.400 QQBrowser/10.4.3587.400'
}
# 指定cookies
cookies = {
'qgqp_b_id': 'c6fbd3a403db8993b4dd3eb2a320ccb6',
'st_si': '73594088022242',
'em_hq_fls': 'js',
'st_asi': 'delete',
'HAList': 'a-sh-600000-%u6D66%u53D1%u94F6%u884C%2Ca-sh-601388-%u6021%u7403%u8D44%u6E90%2Ca-sh-603019-%u4E2D%u79D1%u66D9%u5149',
'_adsame_fullscreen_17590': '1',
'st_pvi': '70133729415159',
'st_sp': '2019-06-23%2013%3A22%3A52',
'st_inirUrl': 'https%3A%2F%2Fwww.sogou.com%2Flink',
'st_psi': '20190623160613932-117001300421-1256798903',
'st_sn': '46'
}
urls = [
'http://guba.eastmoney.com/remenba.aspx?type=1&tab=1'
"http://guba.eastmoney.com/remenba.aspx?type=1&tab=2",
"http://guba.eastmoney.com/remenba.aspx?type=1&tab=3",
"http://guba.eastmoney.com/remenba.aspx?type=1&tab=4",
"http://guba.eastmoney.com/remenba.aspx?type=1&tab=5",
"http://guba.eastmoney.com/remenba.aspx?type=1&tab=6"
]
# 重写start_requests方法
def start_requests(self):
for url in self.urls:
time.sleep(0.2)
yield scrapy.Request(url=url, headers=self.headers, cookies=self.cookies, callback=self.parse)
def parse(self, response):
#这里是选择一中股票类型,列出他下面的所有的选项
list = response.xpath('/html/body/div[1]/div[5]/div[2]/div[1]/div/ul[1]/li')
list2 = response.xpath('/html/body/div[1]/div[5]/div[2]/div[1]/div/ul[2]/li')
list.extend(list2)
for i in list:
#if True:
#i = list[1]
url = i.css('a::attr("href")').extract_first()
detail = response.urljoin(url)
yield scrapy.Request(url=detail, headers=self.headers, cookies=self.cookies, callback=self.parse2)
def parse2(self,response):
item = EastmoneyspiderItem()
item['name'] = response.xpath('//*[@id="stockname"]/a/text()').extract_first()
# 关注量
item['man_number'] = response.xpath('//*[@id="stockheader"]/div[1]/span[1]/em/text()').extract_first()
# 当前热度排行
item['now_hot'] = response.xpath('//*[@id="stockheader"]/div[1]/span[2]/em/text()').extract_first()
quoteCode = response.xpath('//*/script').re(r"var QuoteCode = \"(.*)\";")[0]
quoteURL = "http://nufm.dfcfw.com/EM_Finance2014NumericApplication/JS.aspx?type=CT&cmd=" + quoteCode + "&sty=FDFGBTB&st=z&sr=&p=&ps=&lvl=&cb=?&js=&token=5c46f660fab8722944521b8807de07c0";
getres = self.send(quoteURL)
tt=str(getres.decode('utf8')[4:-3]).split(",")
print(tt)
item["id"]=tt[0]
item['name'] = tt[3]
# 最新
item['latest'] = tt[4]
# 涨跌
item['zhangdie'] = tt[5]
# 涨幅
item['zhangfu'] = tt[6]
# 成交量
item['chengjiaoliang'] = tt[8]
# 成交额
item['chengjiaoe'] = tt[9]
# 流通市值
item['shizhi'] = tt[13]
# 换手
item['huanshou'] = tt[10]
# 振幅
item['zhenfu'] = tt[12]
# 市盈
item['shiying'] = tt[11]
yield item
def send(self,url):
req = request.Request(url=url, headers=self.headers)
res = request.urlopen(req)
res = res.read()
return res
# 输出内容(python3默认获取到的是16进制'bytes'类型数据 Unicode编码,如果如需可读输出则需decode解码成对应编码):b'\xe7\x99\xbb\xe5\xbd\x95\xe6\x88\x90\xe5\x8a\x9f'
print(res.decode(encoding='utf-8'))
# 输出内容:登录成功基本要写的代码如上,其他都是默认配置就好了,如果有需要可以再进行修改
对了,记得修改header和cookie

















 835
835

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









