






1.前言
许多金融工作者在从事金融数据分析挖掘时,苦于没有更多维的数据要素,依赖传统的官方渠道或第三方数据源api,sdk接口只能在现有源数据提供的要素基础上进行数据分析挖掘。大大降低了工作效率及更深层次的研究,我们迫切需要一种更为数据个性化的获取,本文旨在如何使用scrapy框架获取我们个性化的数据要素,并以采集个股行情数据为例为大家示范爬虫获得标的数据。
Scrapy是一个高级Web 爬虫框架,用于爬取网站并从其页面中提取结构化数据。它可以应用于数据挖掘、数据监控和自动化测试等多个方面。与 Requests 库和 Selenium库不同, Scrapy 更适合进行大批量的数据采集(类似百度搜索引擎),其内容相对复杂。面对海量的金融行情数据,scrapy分布式的性能特点使得信息获取更为高效。
2.实验前期准备
本次任务是在pycharm平台上进行编码及安装了anaconda的python3.9环境下进行,同时需要安装MySQL数据库,如果小伙伴们电脑上没有配置好环境,请参考其他博主文章进行配置。
1、scrapy和pymysql的安装:
如果已经安装了anaconda,我们打开命令窗口,使用“pip install scrapy”等待片刻即可安装scrapy,同样的使用“pip install pymysql”等待片刻安装pymysql。
pip install scrapy
pip install pymysql2、创建爬虫框架项目:
scrapy的爬虫项目并不是单个python文件,而是一个个相互关联的py文件组成,各司其职,发挥各自作用,在这里不详细一一讲解,感兴趣可以自行学习。
我们桌面新建一个命名为“scrapy爬虫”的空文件夹,进入文件夹在该文件夹路径栏中输入cmd打开命令窗口。
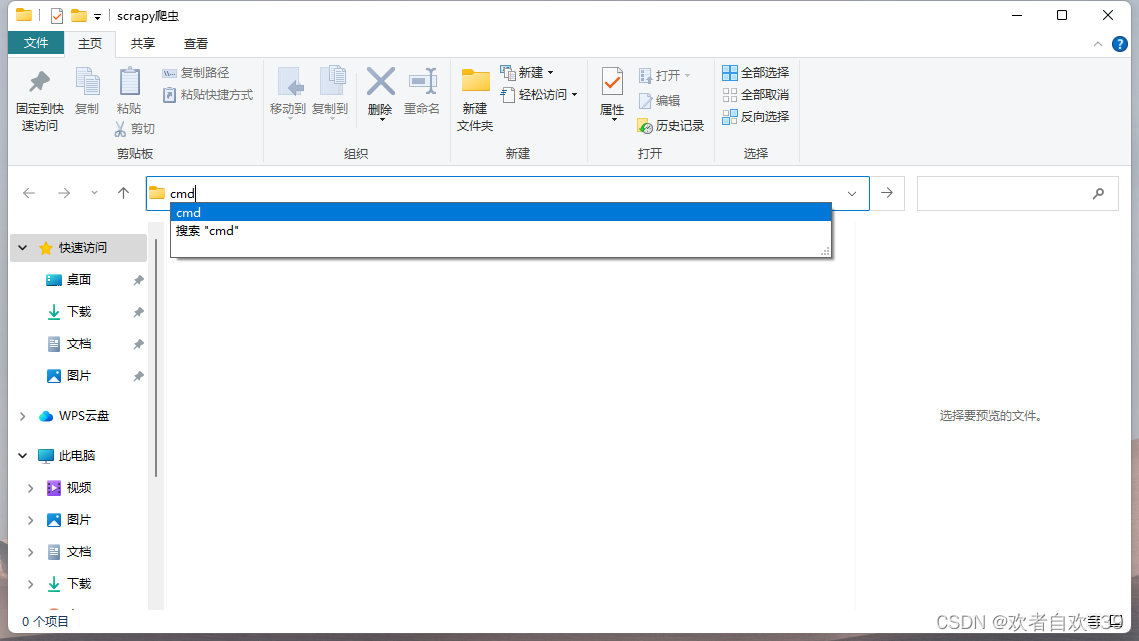
打开命令窗口后,创建爬虫项目dfcf,进入项目,进项目后,我们可以创建具体的爬虫文件。以爬取东方财富网为例,如下图所示,输入并执行指令“scrapy genspidereastmoney eastmoney.com”,创建具体的爬虫文件。“genspider”后的“eastmoney”为爬虫文件名,也可以换成其他名称,而“eastmoney.com”中的“eastmoney”则是东方财富的域名,不能换成其他内容。并且注意这里的爬虫文件名不能和项目名相同。,具体三个命令如下:
scrapy startproject dfcf
cd dfcf
scrapy genspider eastmoney eastmoney.com如图流程:
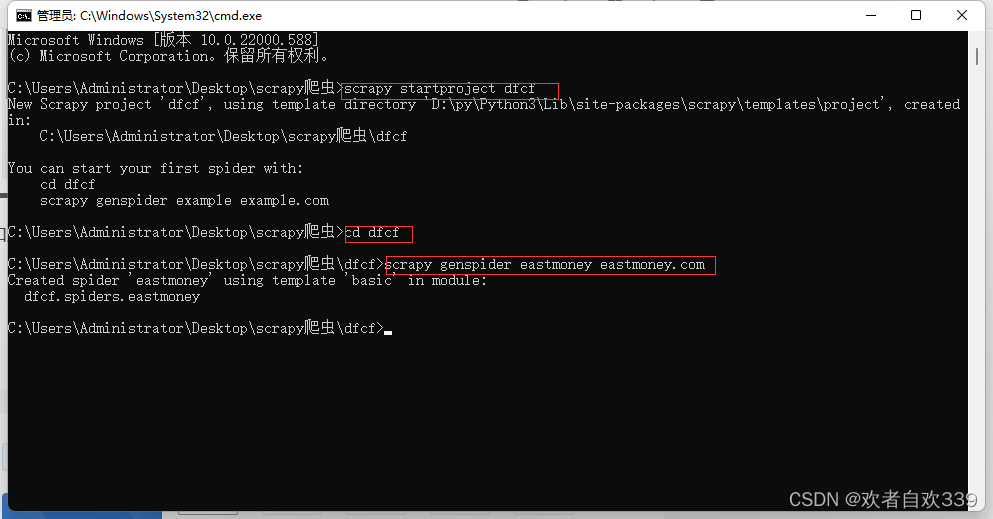
做完上述,可以看到dfcf文件夹里创建好了许多scrapy框架的py文件,文件夹下还生成了一个名为“eastmoney”的python文件,稍后我们将在这些文件中进行我们的爬虫部分的编码。

3、项目编码实现
1、我们先来到目标东方财富的官网,打开个股信息详情页,这里以“东方财富”个股为例。
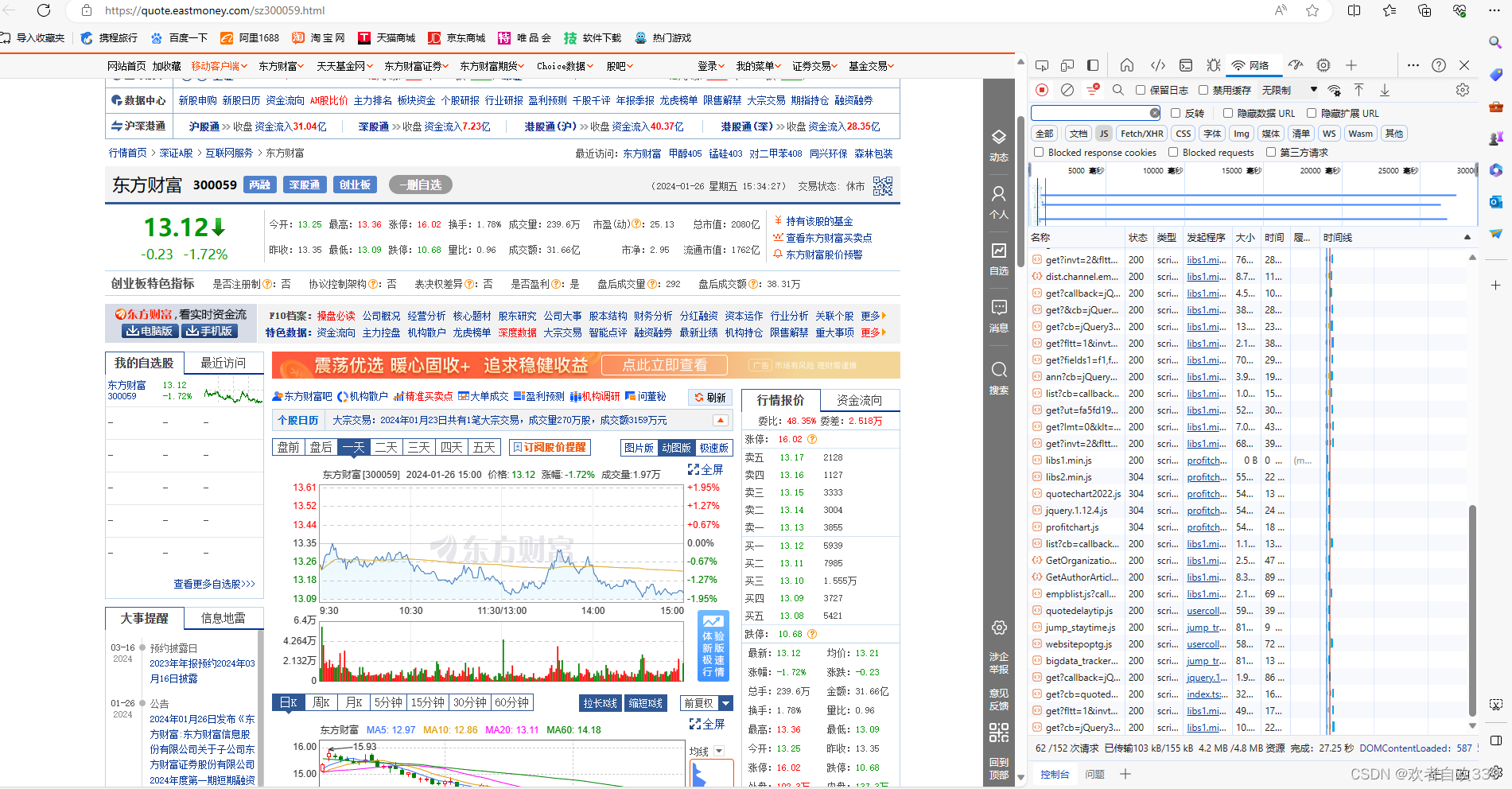
按下F12打开开发者工具,点击网络按钮,然后刷新网页。可以看到右边窗口显示了许多与服务器响应的数据文件,通过一一打开检查预览可以发现,个股的行情数据存放在一个网页文件夹中。
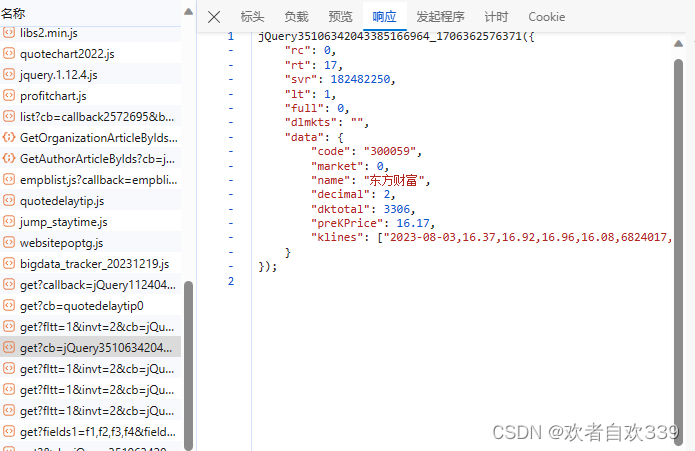
打开这个网页文件夹链接标头跳转到详情网页,可以看到如图该个股日行情数据,最早可以追溯到最近5个月的数据,此时我们记下该网页网址,通过更换不同的个股数据网址进行比对,其只有在‘&secid=0.300059’这部分发生变化,因此我们可以利用这个规律获取更多个股的数据。
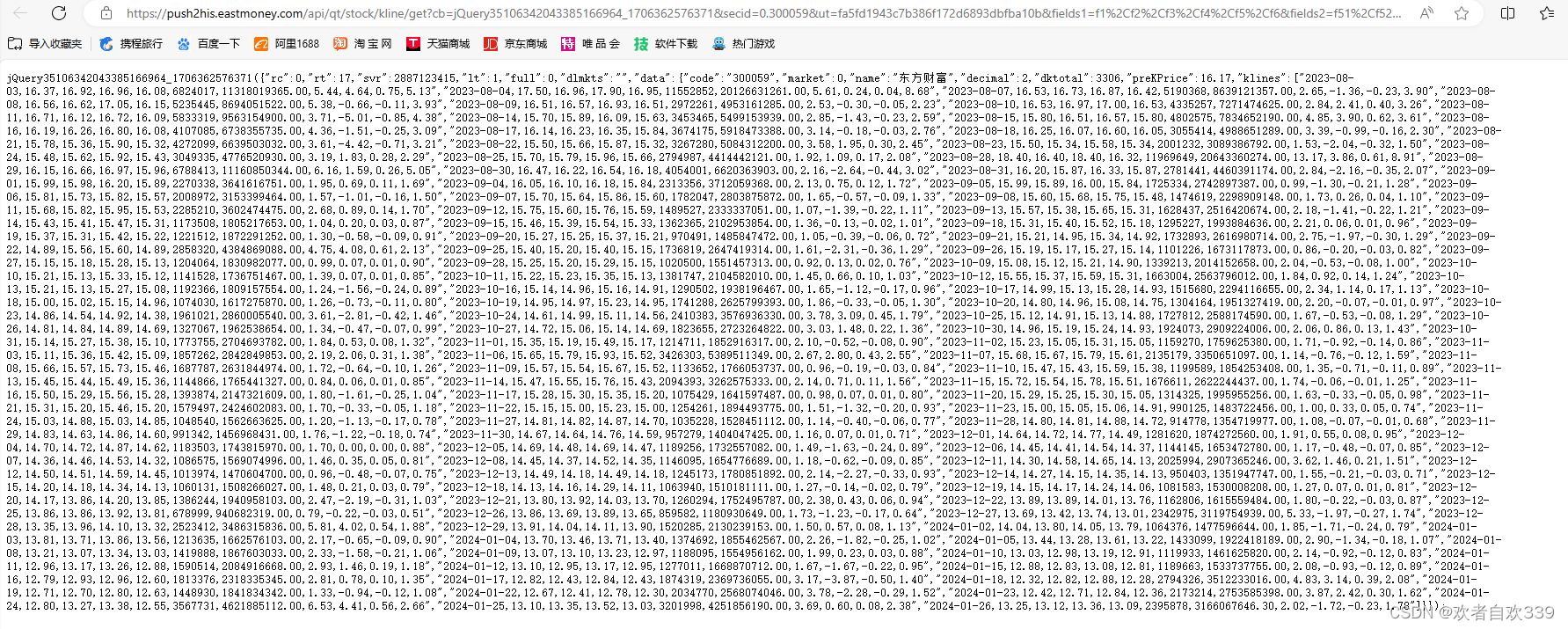
2、找到了数据源网页,我们就可以开始进行编码工作了,我们用pycharm打开之前创建的dfcf项目文件。首先打开中间件文件“middlewares.py”,因为会使用到selenium,time,HtmlResponse,所以文件开头还需要如下代码导入相关库。
from scrapy import signals
from selenium import webdriver
import time
from scrapy.http import HtmlResponse找到下载器中间件DfcfDownloaderMiddleware,我们在这个类下编写代码如下:
def __init__(self):
self.browser = webdriver.Edge()
def process_request(self, request, spider):
self.browser.get(request.url)
time.sleep(0.5)
body = self.browser.page_source
return HtmlResponse(self.browser.current_url, body=body, encoding='utf-8', request=request)看不懂小伙伴可以看下图:
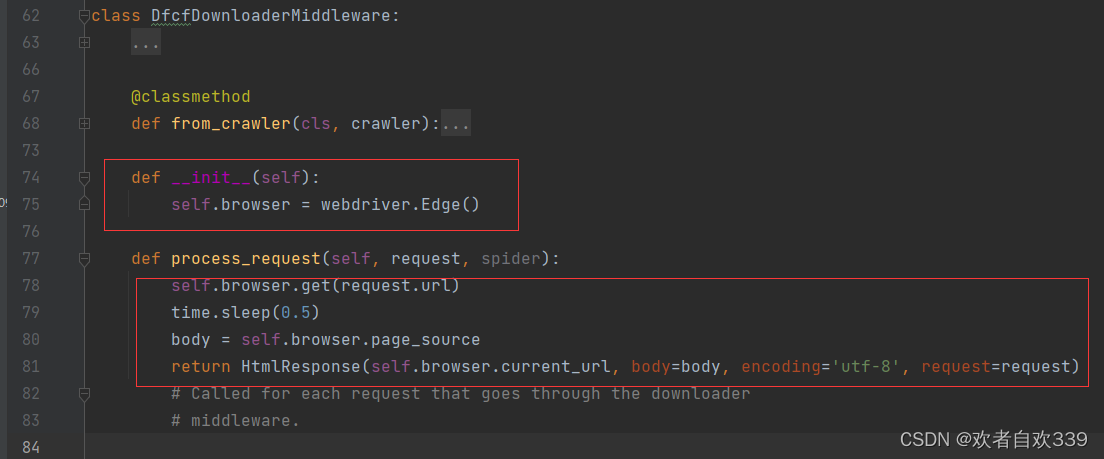
第74行和第75行代码用于定义 DfcfDownloaderMiddleware类的初始化方法,其功能是构造了类的一个属性browser,属性的值webdriver.Chrome()就是 Selenium 库构造的模拟浏览器。browser 只是一个名称代号,也可以写成driver 等其他名称,只要和后续内容保持一致即可。第78行代码通过构造的模拟浏览器来访问请求的网址,这样每次请求一个新的网址,都是通过 Selenium 库构造的这个模拟浏览器进行访问的。第79行代码等待0.5秒,让页面加载完毕,这样可以尽量保证后续获取的网页源代码是我们所需要的。第80行代码通过 self.browser.page_source 获取网页源代码,这个其实和使用 Selenium库时所写的 browser.page_ source 含义相同,只不过在类里应用类属性时得加一个self.,第81行代码用 scrapy.http模块中的HtmlResponse()函数将获得的网页源代码传递给 Scrapy,方便其他组件调用。
3、设置实体文件(建立要获取的字段)
打开实体文件“items.py”,建立相关变量,这里我们设立了股票代码,时间,名称 ,开盘,收盘等12个常用的日线行情字段。
import scrapy
class DfcfItem(scrapy.Item):
code = scrapy.Field()
times = scrapy.Field()
name = scrapy.Field()
open = scrapy.Field()
high = scrapy.Field()
low = scrapy.Field()
close = scrapy.Field()
change = scrapy.Field()
chg = scrapy.Field()
vol = scrapy.Field()
amo = scrapy.Field()
turnover = scrapy.Field()
pass
4、修改设置文件(设置反扒,激活管道文件和启用中间件)
打开设置文件“setting.py”。
先设置不遵守Robots协议,防止触发可能存在的反爬机制。在20行左右,通过取消注释,将True改为False.

设置user-agent,模拟浏览器访问,在40行左右取消字典DEFAULT_REQUEST_HEADERS的注释,然后在其中添加user-agent,代码如下。
DEFAULT_REQUEST_HEADERS = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Language": "en",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36 Edg/120.0.0.0"
}激活管道文件和启用中间件,方便后续通过管道文件进行爬取后的信息存储处理和中间件启用,其实就是在65行和54代码左右取消注释即可
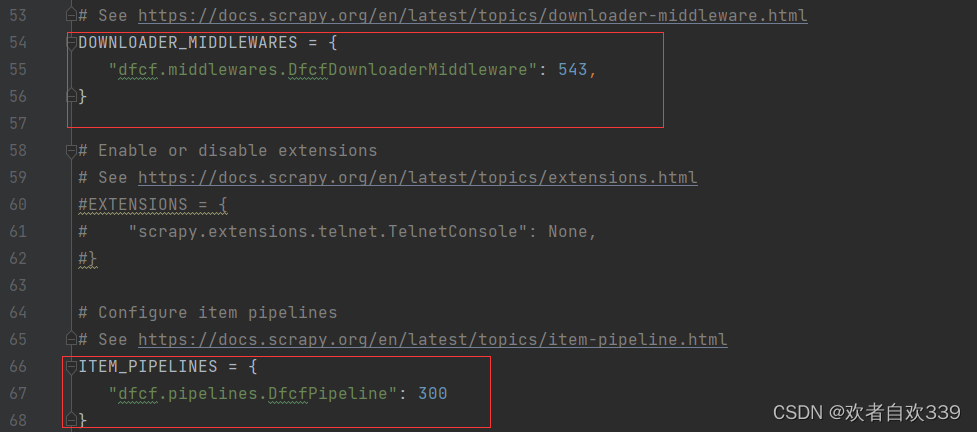
其他设置,在22行到35行这里我们还可以取消修改相关注释和添加相关代码启用scrapy的控制并发请求数量和请求时间间隔在大规模的爬取时提高爬取效率,同时设置不记录COOKIES防止反扒,取消命令窗口的日志显示等设置:
# Configure maximum concurrent requests performed by Scrapy (default: 16)
CONCURRENT_REQUESTS = 100
LOG_ENABLED = False
# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
DOWNLOAD_DELAY = 2
# The download delay setting will honor only one of:
CONCURRENT_REQUESTS_PER_DOMAIN = 100
CONCURRENT_REQUESTS_PER_IP = 100
# Disable cookies (enabled by default)
COOKIES_ENABLED = False
5、在文件夹“spiders”中编写爬虫逻辑(核心爬虫代码)
完成前面步骤后,就可以打开文件夹“spiders”中的爬虫文件“eastmoney.py”,编写核心的爬虫代码了,完整代码如下:
import scrapy
import re
from dfcf.items import DfcfItem
import time
import pandas as pd
import datetime
# 个股日线行情
class EastmoneySpider(scrapy.Spider):
name = "eastmoney"
allowed_domains = ["eastmoney.com"]
start_urls = []
a = pd.read_csv('tushare_stock_basic_20240109214644.csv')
c = a['ts_code'].tolist()
# c = c[1450:]
for i in range(len(c)):
t = (c[i][0:6])
if t[0] == '6':
t = '1.' + t
else:
t = '0.' + t
url = 'https://push2his.eastmoney.com/api/qt/stock/kline/get?cb=jQuery35108551412679670602_1705319455367&secid=' + t + '&ut=fa5fd1943c7b386f172d6893dbfba10b&fields1=f1%2Cf2%2Cf3%2Cf4%2Cf5%2Cf6&fields2=f51%2Cf52%2Cf53%2Cf54%2Cf55%2Cf56%2Cf57%2Cf58%2Cf59%2Cf60%2Cf61&klt=101&fqt=1&end=20500101&lmt=120&_=1705319455403'
start_urls.append(url)
def parse(self, response):
data = response.text
p_d = '"klines":.*?"(.*?)"]'
p_code = '"code":"(.*?)",'
p_name = '"name":"(.*?)",'
p_df = re.findall(p_d, data,re.S)
code = re.findall(p_code, data,re.S)
name = re.findall(p_name, data,re.S)
#print(p_df)
p_df = p_df[0].split('","')
times = []
opens = []
highs = []
lows = []
closes = []
volumes = []
amounts = []
chas = []
chgs = []
turnovers = []
for i in range(len(p_df)):
a = p_df[i].split(',')
times.append(a[0])
opens.append(a[1])
highs.append(a[3])
lows.append(a[4])
closes.append(a[2])
volumes.append(a[5])
amounts.append(a[6])
chgs.append(a[8])
chas.append(a[9])
turnovers.append(a[10])
item = DfcfItem()
item['name'] = name
item['code'] = code
item['times'] = times
item['open'] = opens
item['high'] = highs
item['low'] = lows
item['close'] = closes
item['change'] = chas
item['chg'] = chgs
item['vol'] = volumes
item['amo'] = amounts
item['turnover'] = turnovers
yield item
pass
这里我们首先将源框架代码的start_urls列表清空,然后我们读入我们事先准备好的股票个股代码“tushare_stock_basic_20240109214644.csv”表格文件,里面是目前(2024.1.9)A股市场上的所有股票的代码,用于构建我们的个股数据网址,实现多个股票数据采集。有需要的小伙伴也可以到主页资源获取。随后使用切片和tolist()方法获取文件中的ts_code字段内容形成个股代码列表。我们使用之前在浏览器上获取到的数据网页代码对其字符串拼接,利用遍历的方法将代码列表自动生成一个个相对应的个股url。需要注意的是,经过笔者的多次爬取时发现,东方财富的数据源网页url存在这么的一个规律,6开头的股票代码其url网址的“&secid=”参数为“1.+股票代码”的形式,而其他数字开头的股票url网址中“&secid=”参数为“0.+股票代码”的形式,这是一个非常关键的点,因此我们可以使用一个判断条件进行构建“&secid=”参数,将生成好的url用append()方法添加进start_urls列表中,以便实现多个数据源爬取。
class EastmoneySpider(scrapy.Spider):
name = "eastmoney"
allowed_domains = ["eastmoney.com"]
start_urls = []
a = pd.read_csv('tushare_stock_basic_20240109214644.csv')
c = a['ts_code'].tolist()
# c = c[1450:]
for i in range(len(c)):
t = (c[i][0:6])
if t[0] == '6':
t = '1.' + t
else:
t = '0.' + t
url = 'https://push2his.eastmoney.com/api/qt/stock/kline/get?cb=jQuery35108551412679670602_1705319455367&secid=' + t + '&ut=fa5fd1943c7b386f172d6893dbfba10b&fields1=f1%2Cf2%2Cf3%2Cf4%2Cf5%2Cf6&fields2=f51%2Cf52%2Cf53%2Cf54%2Cf55%2Cf56%2Cf57%2Cf58%2Cf59%2Cf60%2Cf61&klt=101&fqt=1&end=20500101&lmt=120&_=1705319455403'
start_urls.append(url)
构建好了url列表,接下来在parse函数中编写数据采集代码。先是将获取到的网页源码转化成字符串赋值data,通过观察获取到的源码,可以发现数据网页的个股代码,名字和数据分别在一个大字典的“code”,"name","klines"中。其中"klines"键下以字符串的形式存放了每一个交易日的行情数据,以逗号分隔。

于是我们就可以使用正则表达式将其提取股票代码和名字,数据等信息,然后通过.split()的方法对"klines"键下字符串进行分隔每日行情。随后定义好相关的字段列表以存储字段信息,使用遍历的方法,将每一个交易日的字符串以逗号分隔成列表,用切片的方法将每一个元素位置上对应的字段信息进行添加到相应的字段列表中,具体代码如下:
def parse(self, response):
data = response.text
p_d = '"klines":.*?"(.*?)"]'
p_code = '"code":"(.*?)",'
p_name = '"name":"(.*?)",'
p_df = re.findall(p_d, data,re.S)
code = re.findall(p_code, data,re.S)
name = re.findall(p_name, data,re.S)
p_df = p_df[0].split('","')
times = []
opens = []
highs = []
lows = []
closes = []
volumes = []
amounts = []
chas = []
chgs = []
turnovers = []
for i in range(len(p_df)):
a = p_df[i].split(',')
times.append(a[0])
opens.append(a[1])
highs.append(a[3])
lows.append(a[4])
closes.append(a[2])
volumes.append(a[5])
amounts.append(a[6])
chgs.append(a[8])
chas.append(a[9])
turnovers.append(a[10])
激活实体文件,将获取到的12个字段信息一一对应赋值给之前在实体文件构建好的12个字段,方便后续的管道文件进行数据存储操作:
item = DfcfItem()
item['name'] = name
item['code'] = code
item['times'] = times
item['open'] = opens
item['high'] = highs
item['low'] = lows
item['close'] = closes
item['change'] = chas
item['chg'] = chgs
item['vol'] = volumes
item['amo'] = amounts
item['turnover'] = turnovers
yield item
pass6、设置管道文件编码(爬后数据存储处理)
编写好爬虫核心代码文件后,在“pipelines.py”中进行数据爬后处理(即存储本地金融数据库),在此之前需要小伙伴们先安装好MySQL数据库并在MySQL中建立一个命名为“股票日线数据”的数据库。完整代码如下:
import pymysql
from dfcf.items import DfcfItem
class DfcfPipeline:
def process_item(self, item, spider):
code = item['code']
name = item['name']
time = item['times']
open = item['open']
high = item['high']
low = item['low']
close = item['close']
vol = item['vol']
amo = item['amo']
cha = item['change']
chg = item['chg']
turnover = item['turnover']
for i in range(len(time)):
db = pymysql.connect(host='localhost',port=3306, user='root', password='', database='股票日线数据', charset='utf8mb4')
cursor = db.cursor()
sql1 = 'create table if not exists stock_%s'%code[0] + '(code varchar(20),name varchar(20),time text ,open double(16,2) ,high double(16,2),low double(16,2),close double(16,2),volume double(16,2),amount double(16,2),cha double(16,2),chg double(16,2),turnover double(16,2))'
cursor.execute(sql1)
sql2 = 'select * from stock_%s where code = %s'%(code[0],code[0])
cursor.execute(sql2)
df = cursor.fetchall()
# print(df)
df1 = []
for j in range(len(df)):
df1.append(df[j][2])
# print(df1)
if time[i] not in df1:
# print(time)
sql3 = 'insert into stock_%s'%code[0] + '(code,name,time,open,high,low,close,volume,amount,cha,chg,turnover) values (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)'
cursor.execute(sql3,(code[0],name[0],time[i],open[i],high[i],low[i],close[i],vol[i],amo[i],cha[i],chg[i],turnover[i]))
db.commit()
cursor.close()
db.close()
print('股票' + str(code[0]) + '录入成功!')
return item这里我们导入相关的库,从实体文件的相应字段获取之前我们存储的字段信息数据,我们还是使用遍历的方法对字段信息进行一一对应提取存入数据库中,连接好我们的数据库(具体的连接参数实小伙伴的数据库信息而定,这里的参数为笔者的本地数据库信息)。这里我们为每一个个股创建一个数据表,命名为“stock_股票代码”。sql1语句执行的是先检查数据库中是否存在“stock_股票代码”的数据表,如存在则直接进行下一步,不存在则创建数据表以及数据表内字段结构相关设置。sql2部分是提取检查对应数据表内信息,用于后续判断防止重复存储交易日信息。我们使用判断语句将该日的时间与sql2提取的日期列表df1中进行对比,如果不存在则使用sql3语句进行存入,如果存在则不再录入。
7、运行scrapy爬虫项目
因为 Scrapy 爬虫项目是由多个Python 文件组成的,这里的“eastmoney.py”其实和其他Python文件有关联。如果只运行这一个文件,并不能真正启动爬虫项目。在Scrapy中,应该使用指令“scrapy crawl XXX (爬虫名)”来执行爬虫项目。这里的爬虫名为“eastmoney”,那么对应的指令为“scrapy crawl eastmoney”.指令可以通过打开pycharm的终端或者打开爬虫文件路径下的cmd命令窗口执行,如下是在pycharm的终端运行命令。
执行命令结果如下:
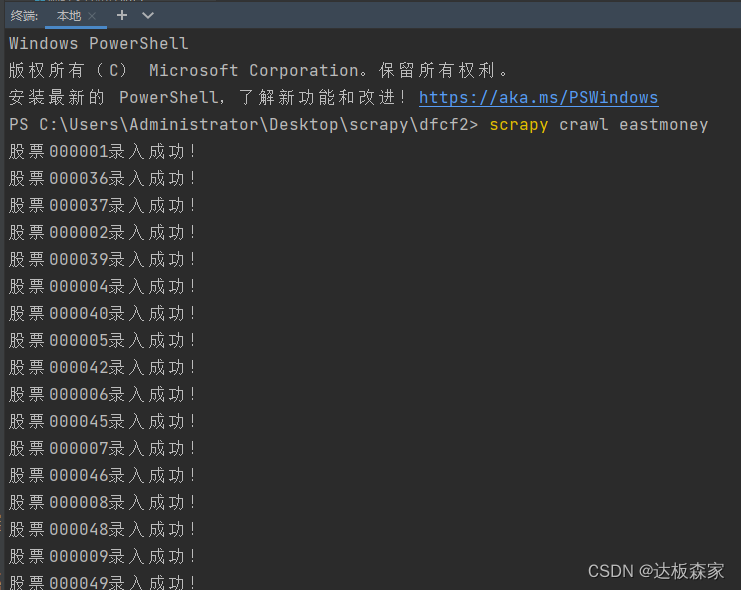
我们通过wampserver(一款Apache Web 服务器、PHP解释器及 MySQL数据库的整合软件包。它会自动将一些设置配置好,不需要像传统的数据库安装方法那样配置环境变量,有需要的可以主页资源获取安装包)查看数据库中相关情况,可以看到以及创建好了一些个股数据表
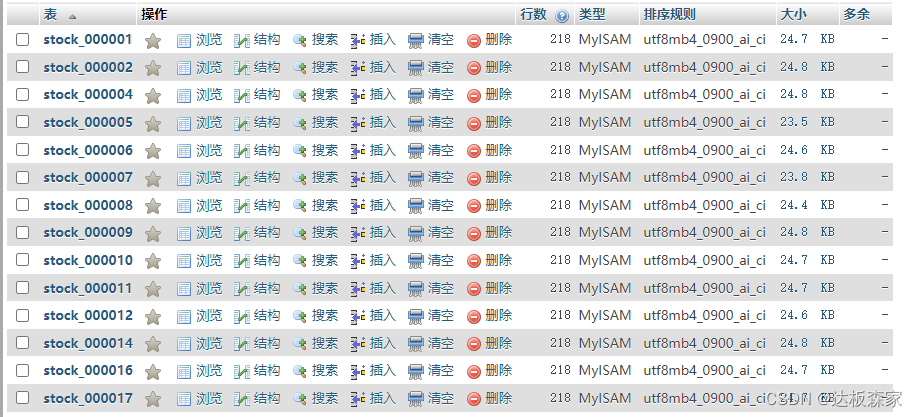
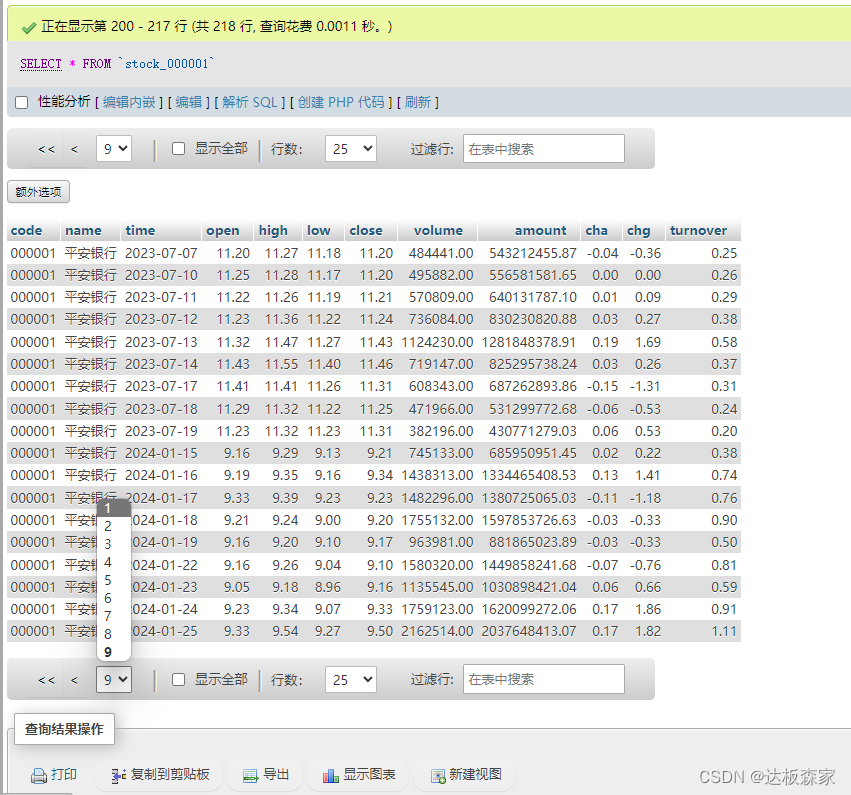
我们点击平安银行个股查看,已经录入了218行数据。
4、总结
至此,整个利用scrapy框架爬取金融数据,以东方财富个股日线行情并存入本地MySQL数据库项目到这里就全部完成了。日常数据挖掘中,我们需要各种各样的数据要素,本文讲解了如何使用scrapy获取日线行情数据,同样的我们也可以在此方法上进行个性化编码实现不同数据标的来源获取到更多自己想要的数据,需要注意的是,越来越多的数据网站建立了更严格的反扒措施,我们需要不断地提升反爬取技术以不断应对未来数据信息不对称获取的困难。金融市场向来不缺乏数据,缺乏的是更具有信息价值的数据,或许这样的信息普通参与者更难以获取和挖掘。爬虫或许是一个突破的途径,但同样注意保护知识产权及相关法律法规,以友好的形式使用爬虫。


















 1089
1089

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











