






前情提要
在分布式计算中 Join 一般都是性能地瓶颈,因为中间有 Shuffle,Doris中默认的 Join 机制是 ShuffleJoin(适用于一切Join)但是效率相对平庸!
Join优化
Broadcast join
如果是大表 Join 小表,我们可以在小表前加个 [broadcast],也就是广播一个小表给大表进行 Join,大表拥有小表的全量数据,小表参与每一个 Join 节点。
sql select ... from order_info_broadcast as oi JOIN [broadcast] goods_broadcast as gs
Bucket shuffle join (桶join)
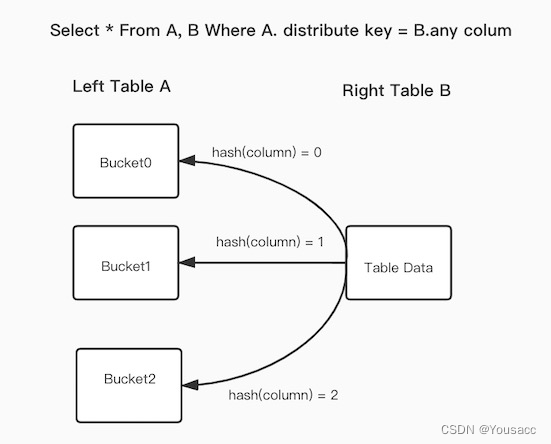
在 FE 之中保存了 Doris 每个表的数据分布信息,如果 join 语句命中了表的数据分布列,我们应该使用数据分布信息来减少 join 语句的网络与内存开销。
如果一个 A 表经常需要用某个固定字段 K,来跟 B 表进行关联查询,则我们可以把 K 定义为 A 表的分桶字段,这样一来,当 Join 的等值表达式命中了 A 的数据分布列,Doris 底层就会将 Join 的执行计划解析为:Bukect shuffle join。
Bucket Shuffle Join 会根据 A 表的数据分布信息,将 B 表的数据发送到对应的 A 表的数据存储计算节点,相比 Shuffle Join 会减少 Shuffle 的数据量和 IO;
sql mysql> set enable_bucket_shuffle_join = true;
Colocation join (协同位置组join)条件非常严格
如果 经常需要对 A 、 B 、C 等表进行关联查询分析,那么,我们可以在定义 A 、 B 、C 表时,各自使用关联的on条件字段来作为分桶列,且让他们的分桶数相同,且指定他们的位置协同组是同一个组(那么,这些表的相同桶号的桶,就会被存放在相同的BE节点上,JOIN时完全不需要网络传输)。

CREATE TABLE A (k1 int, v1 int sum)
DISTRIBUTED BY HASH(k1)
BUCKETS 8
PROPERTIES(
"colocate_with" = "group1"
);
CREATE TABLE B (kk1 int, v1 int sum)
DISTRIBUTED BY HASH(kk1)
BUCKETS 8
PROPERTIES(
"colocate_with" = "group1"
)
CREATE TABLE C (f1 int, v1 int sum)
DISTRIBUTED BY HASH(f1)
BUCKETS 8
PROPERTIES(
"colocate_with" = "group1"
)
则,这些表的桶数都相同,桶中的数据都按照join条件列拥有相同的数据分布规律,且各表的相同桶号的桶都会落在相同的BE节点上;
select
*
from a join b on a.k1 = b.kk1
join c on b.kk1 = c.f1
这样,Doris 底层在 Join 时,就不需要进行数据的 Shuffle,各桶在各 BE 的本地进行拼接即可;















 1380
1380

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









