







问题
with t1 as (
select *
from dor_alive_user_all_rt
where app_id = 'xxx'
and alive_id = 'xxxx'
),
t2 as (
select *
from dor_t_users_full_rt
where app_id = 'xxx'
)
select
t1.app_id,
t1.alive_id,
t2.user_id,
t2.wx_name,
t2.phone
from t1
join t2 on t1.app_id = t2.app_id
and t1.user_id = t2.user_id;
上面的SQL,t1表2条数据,t2表56万条数据
如果是t1 left join t2,时间是2.8s,如果是t1 join t2,时间是0.4s,如果是t2 right join t1,时间则不到30ms,为什么三种Join写法会有三个不同的执行时间呢,接下来我们一起仔细探究其中的差别。
原因
-
t1 left join t2:由于右表过大,表扫描时无法构建runtime filter,因此这个过程是2条数据去 Join 56万条数据,速度很慢。

上图可以看到,Join的过程也没有使用runtime filter。 -
t1 join t2:执行计划如下,扫描时对t1表构建runtime filter,但是由于t1表通过alive_id就可以剔除所有不符合的数据,因此这部分优化没有效果。此外,1:VOlapScanNode的结果是56万条数据。真正让它速度变快的是在Hash Join的时候对t2表使用了runtime filter,原本t2表是56万条数据,runtime filter之后只剩2条数据,因此Hash Join的速度变快了。
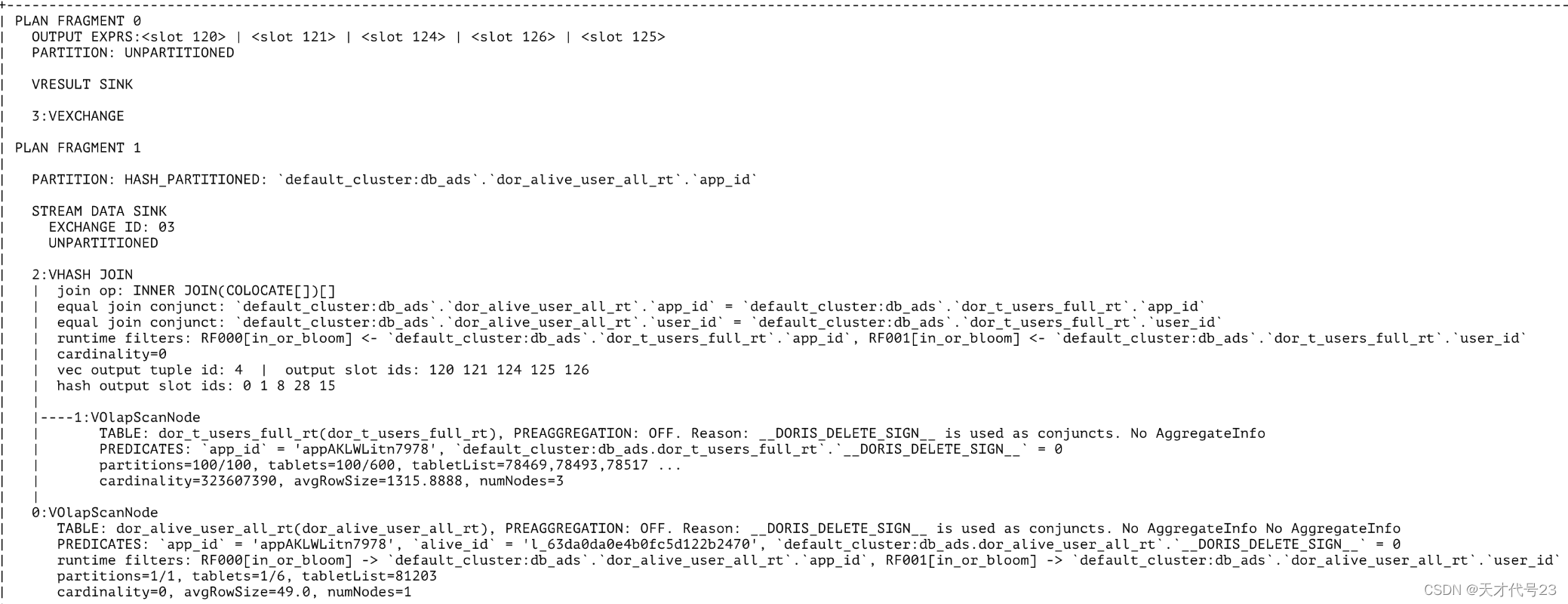
-
t2 right t1:执行计划如下,扫描时对t2表使用了runtime filter,使得结果数据只有两条,因此两个ScanNode的结果都是两条数据,这样Hash Join的速度就很快了,因此整体速度只需几十毫秒。
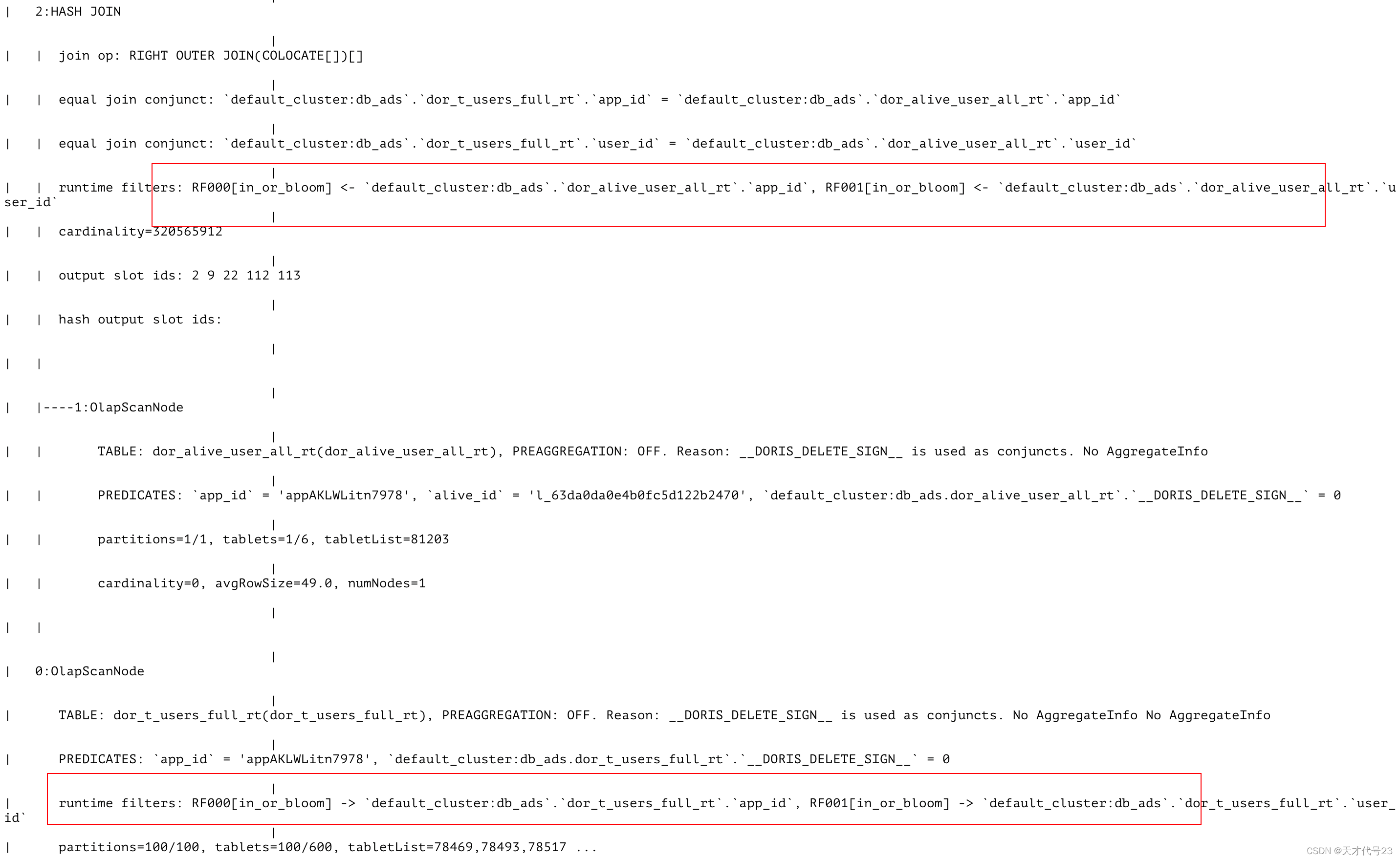
此外,上面的SQL还可以这么写:
with t1 as (
select *
from dor_alive_user_all_rt partition(p_78)
where app_id = 'appAKLWLitn7978'
and alive_id = 'l_63da0da0e4b0fc5d122b2470'
),
t2 as (
select *
from dor_t_users_full_rt partition(p_78)
where app_id = 'appAKLWLitn7978'
)
select /*+SET_VAR(enable_cost_based_join_reorder=true) */
t1.app_id,
t1.alive_id,
t2.user_id,
t2.wx_name,
t2.phone
from t1
join t2 on t1.app_id = t2.app_id
and t1.user_id = t2.user_id;















 1321
1321











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









