









 本文介绍了一个使用PyTorch处理Iris数据集的示例,通过自定义数据集类并利用DataLoader进行数据加载,实现了数据的shuffle和mini-batch划分,适用于机器学习和深度学习的初步实践。
本文介绍了一个使用PyTorch处理Iris数据集的示例,通过自定义数据集类并利用DataLoader进行数据加载,实现了数据的shuffle和mini-batch划分,适用于机器学习和深度学习的初步实践。
import sys
import torch
import random
import argparse
import numpy as np
import pandas as pd
import torch.nn as nn
from torch.nn import functional as F
from torch.optim import lr_scheduler
from torchvision import datasets, transforms
from torch.utils.data import TensorDataset, DataLoader, Dataset
class DealDataset(Dataset):
def __init__(self):
xy = np.loadtxt(open('./iris.csv','rb'), delimiter=',', dtype=np.float32)
#data = pd.read_csv("iris.csv",header=None)
#xy = data.values
self.x_data = torch.from_numpy(xy[:, 0:-1])
self.y_data = torch.from_numpy(xy[:, [-1]])
self.len = xy.shape[0]
def __getitem__(self, index):
return self.x_data[index], self.y_data[index]
def __len__(self):
return self.len
dealDataset = DealDataset()
train_loader2 = DataLoader(dataset=dealDataset,
batch_size=2,
shuffle=True)
#print(dealDataset.x_data)
for i, data in enumerate(train_loader2):
inputs, labels = data
#inputs, labels = Variable(inputs), Variable(labels)
print(inputs)
#print("epoch:", epoch, "的第" , i, "个inputs", inputs.data.size(), "labels", labels.data.size())
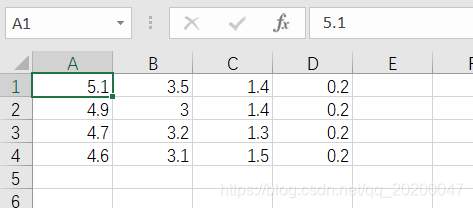
简易数据集
![]()
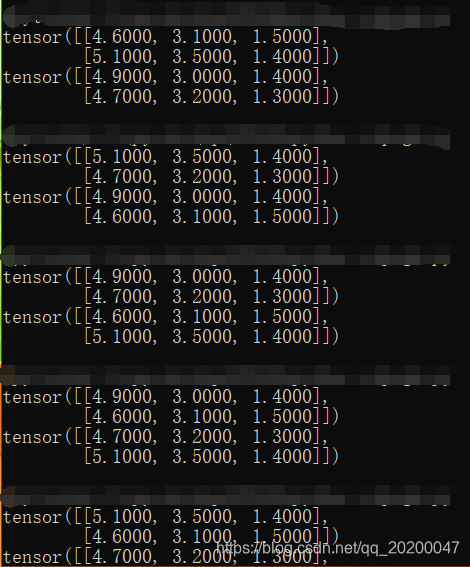
shuffle之后的结果,每次都是随机打乱,然后分成大小为n的若干个mini-batch.

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









