







文本转语音技术正逐渐成为人机交互的重要组成部分,在多语音合成场景下,如何有效接入并管理各类 TTS 服务商成为开发者关注的关键问题。
文章围绕一个基于 Django 后台的 TTS 插件系统展开,涵盖用户积分控制、语音服务配置、字数记录、API 接入与本地合成等模块,实现灵活扩展的语音能力整合解决方案。
功能展示
TTS 插件的功能体系围绕资源分配、服务配置与调用追踪展开,构建了一个完整的语音合成管理闭环。积分用户模块负责使用权限控制与额度分配,结合用户充值与实时扣费机制,确保系统资源合理调度。TTS配置模块为多服务商接入提供标准化配置流程,适应不同厂商的接入要求,提升插件扩展性。积分记录模块则补齐了使用透明度和日志可追溯性,便于后续审计与优化调用策略。整体系统注重可操作性与数据一致性,提升后台管理效率和多模态输出的落地能力。
| 模块名称 | 功能简述 | 管理操作 | 使用价值 |
|---|---|---|---|
| 积分用户 | 统计用户调用TTS服务的字数消耗,关联用户信息 | 同步用户信息、分配额度、查看订单 | 控制资源分配,追踪使用情况 |
| TTS配置 | 管理语音合成服务商配置及参数,支持多厂商接入 | 填写API参数、保存生效 | 支持灵活接入,降低配置难度 |
| 积分记录 | 记录用户调用接口的详细消耗日志,包括时间、厂商、字数、用途等信息 | 自动记录、展示与导出 | 支持成本审计、行为追踪与性能监控 |
积分用户
该模块用于统计并管理系统用户在调用TTS文本转语音模型服务过程中的字数消耗情况,帮助管理员精准掌握各用户的使用额度与历史记录。点击 “同步用户信息” 按钮,系统将自动从当前后台用户表中导入用户数据,生成对应的积分用户记录。同步操作无需手动添加,确保数据实时一致。
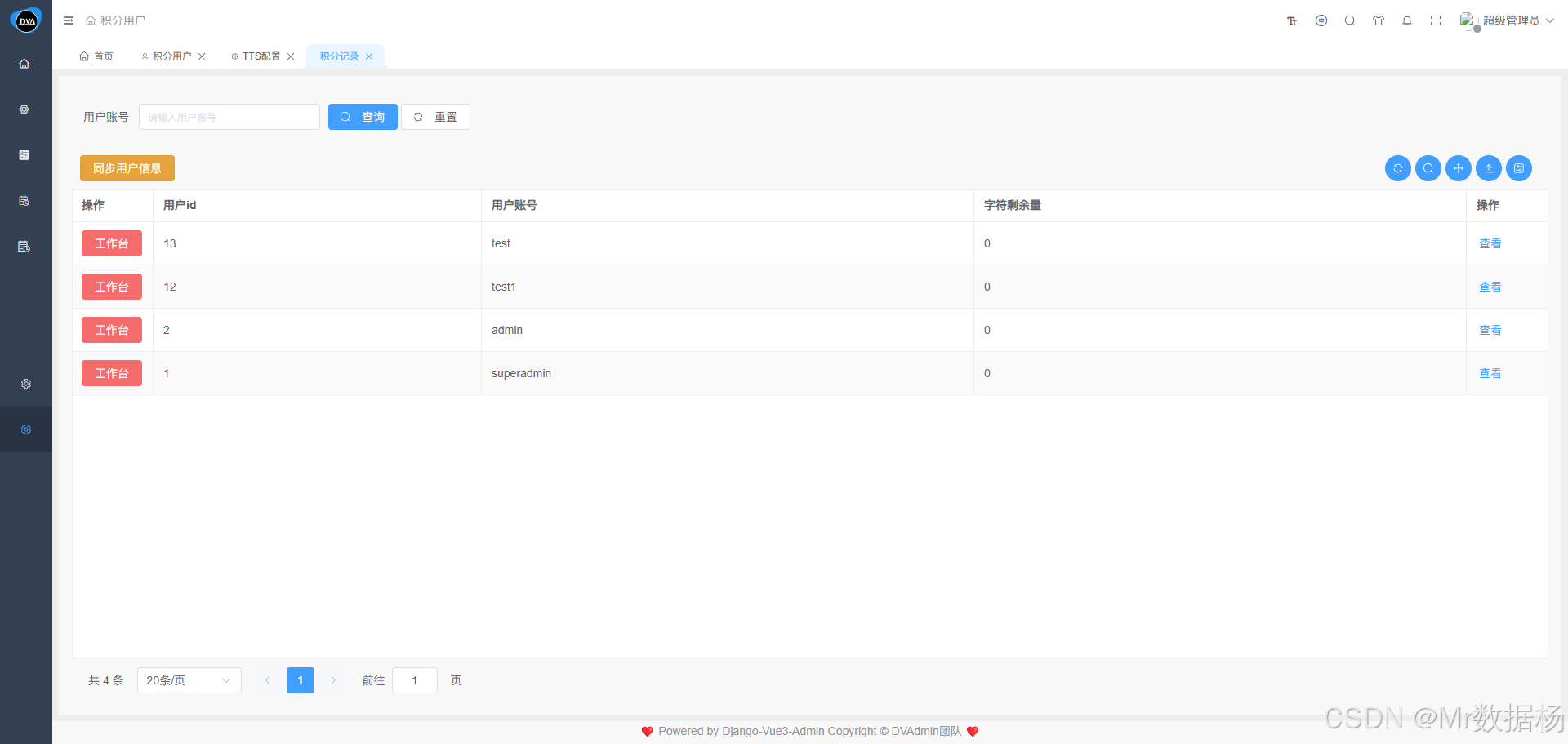
在工作台页面,管理员可以为每位用户分配字符使用额度,类似于“充值积分”。用户在使用TTS不同厂商进行文本转语音操作时,将按实际消耗从余额中扣除。该机制既能限制过度调用,又方便追踪成本开销。
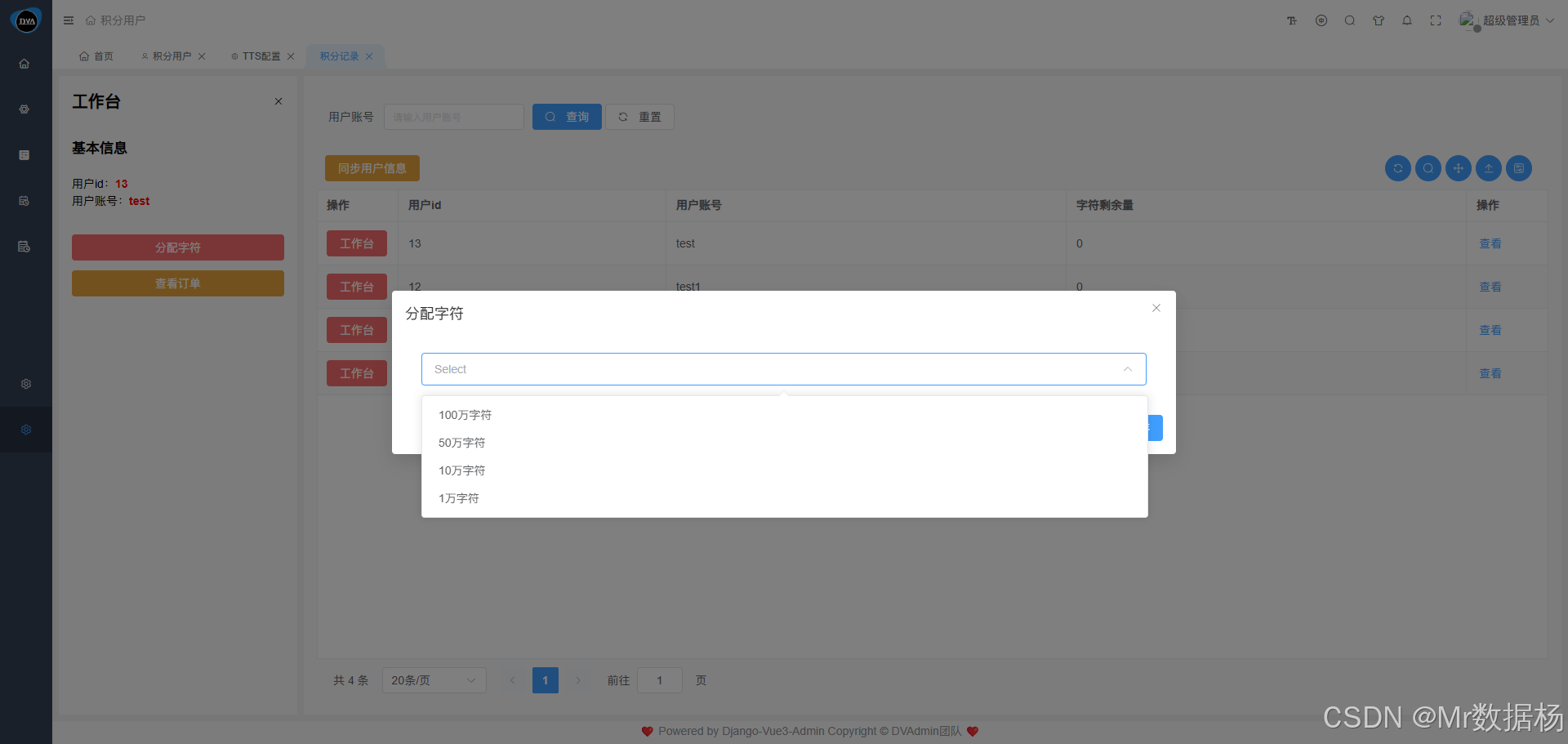
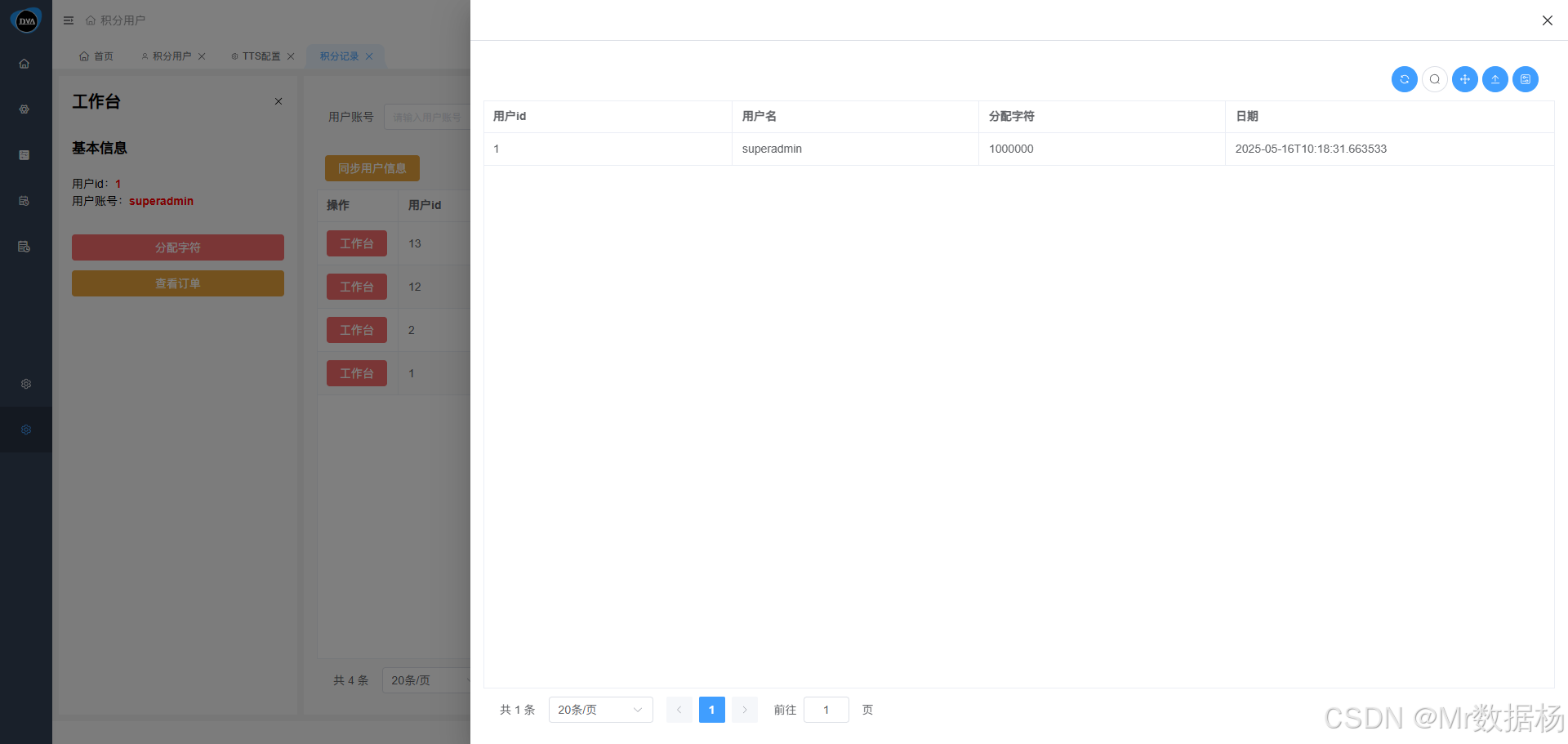
点击“查看订单”按钮可进入充值记录页面,支持查看所有用户的充值订单详情,包括时间、金额、备注信息等。该页面方便管理员审核充值行为、核对账单、导出报表等操作。
TTS配置
该模块用于统一管理系统支持的TTS文本转语音厂商及其 API 接入配置,便于开发者与管理者对接第三方模型服务如微软、魔音等。系统会根据内置的初始化数据预配置主流模型厂商的服务信息。根据不同的厂商信息填写不同的配置要求即可。
|厂商|额外说明|
|微软|需要选择对应密钥的服务地区|
|魔音|key是两部分组成,用,分割|
⚠️ 修改或新增配置信息后,请务必点击右上角的 “保存” 按钮以生效。
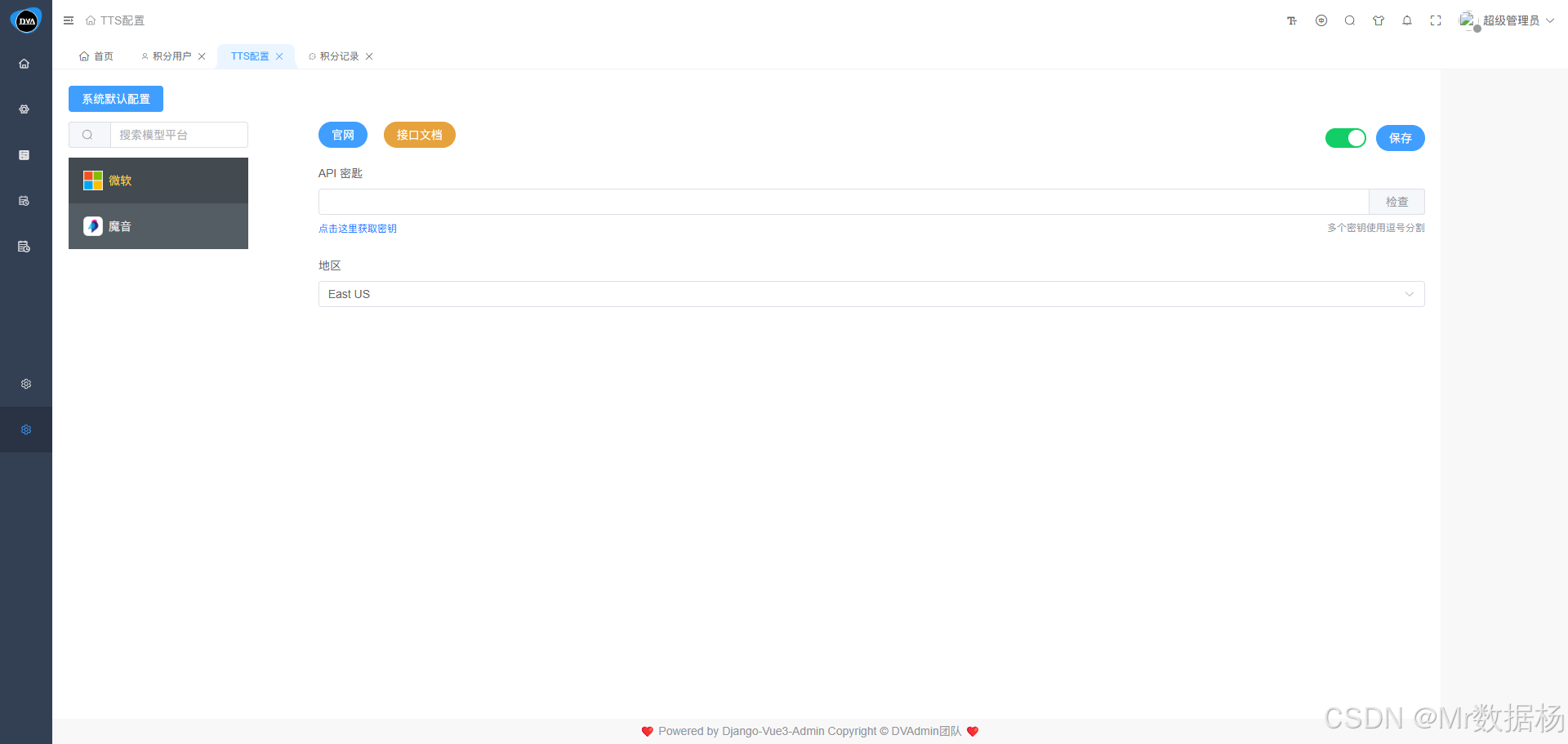
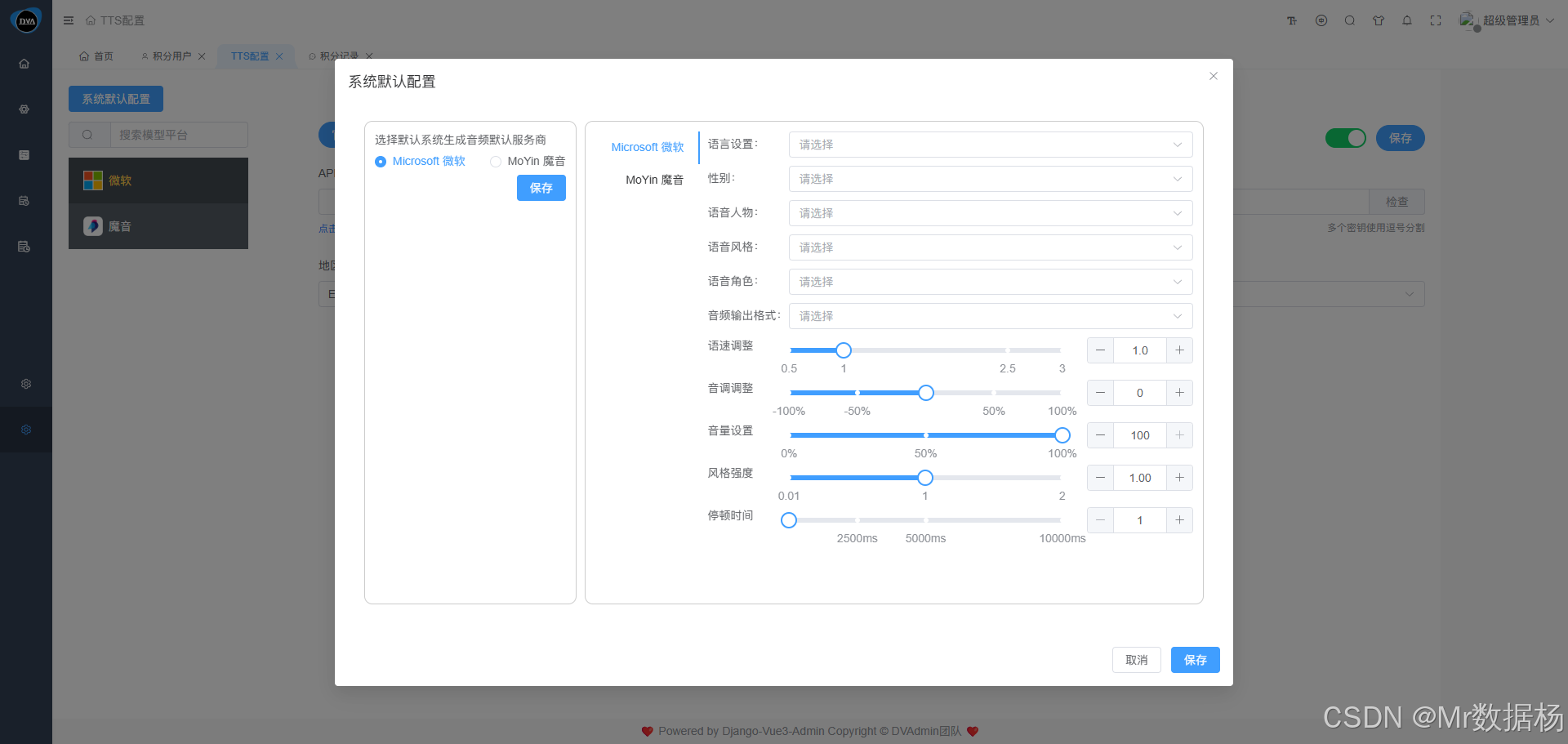
系统默认配置界面分为左右两部分:右侧可设置不同厂商的配音参数,包括语言、角色、语速和语调等选项;左侧在选择并保存特定厂商配置后,该设置将全局生效,用于后续的文本转语音操作。请注意,必须确保所有参数设置准确无误,否则将无法成功生成语音。
积分记录
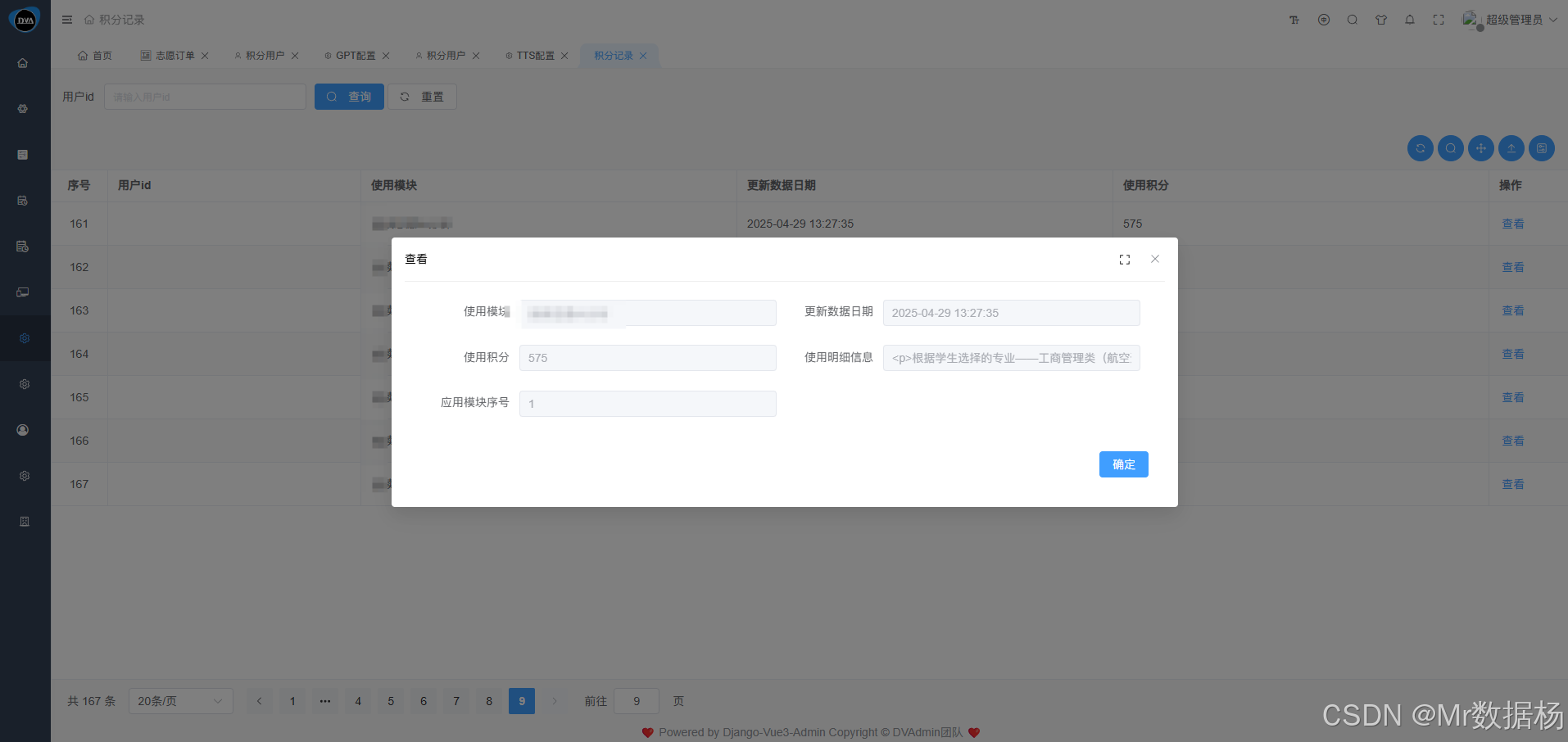
该模块用于详细记录用户在系统中调用各类厂商接口时的字数消耗情况,包括每一次请求的模型类型、调用时间、消耗额度、所属应用等关键信息。
快速上手
解压插件包放置 dv3admin 项目 plugins 目录下。
dv3admin_tts/
├── fixtures/ # 初始化数据(如模板导入、默认配置)
├── management/ # Django 自定义管理命令
├── migrations/ # 数据库迁移脚本
├── setting_data/ # 插件配置项、模型初始化配置
├── static/ # 前端静态资源(JS、CSS、图标等)
├── views_app/ # 后端视图逻辑模块
├── web/ # Web 端相关模块(如交互组件或集成页面)
├── dv3admin_tts/ # 主要 Django 应用包
│ ├── __init__.py # Python 包初始化
│ ├── apps.py # Django 应用注册入口
│ ├── models.py # 数据模型定义
│ ├── settings.py # 插件级别的配置(如默认参数)
│ ├── urls.py # URL 路由配置
│ └── README.md # 子应用说明文档
├── .gitignore # Git 忽略配置
将 web 文件夹下的 dv3admin_tts 复制到前端的 src/views/plugins 目录下即可。
在 application/settings.py 中添加下面的内容即可。
# ********** 一键导入插件配置开始 **********
from plugins.dv3admin_chatgpt.tts import * # ChatGPT配置
在项目根目录下执行以下命令以完成模型配置、菜单注册和静态资源加载:
python manage.py init_tts
初始化完成后将输出如下内容:
✅ TTS 菜单初始化完成
✅ TTSSetting 初始化完成
✅ 静态文件 初始化完成
完成以上步骤后,即可在后台系统中看到 TTS 插件菜单并开始使用。
应用开发
管理后台项目内应用
如果想在管理后台中开发一个直接可以调用当前插件的应用模块,例如在某个模块嵌入使用当前功能进行音频流生成。
可以根据下面的Demo直接进行接口对接即可,需要在初始化数据后在管理后台输入API的具体参数后可用。
dv3admin_tts 插件通过标准化接口封装,支持本地语音合成与多种第三方 TTS 服务(如 Microsoft TTS、MoYinTTS)的接入。开发者可在后台系统配置语音参数,通过流式接口实现文本到语音的动态转换,支持语速、音调、风格等定制化选项,适用于交互式内容输出、语音播报与辅助阅读等场景。统一的调用方式和灵活的参数结构,降低了集成成本,增强了系统的多模态输出能力。
| 接口名称 | 类型 | URL 示例 | 特点与用途描述 | 参数关键项 | 鉴权方式 |
|---|---|---|---|---|---|
| 本地 TTS 合成接口 | 本地服务 | /api/dv3admin_tts/tts_local_stream/ | 适用于无外部依赖的本地合成,部署简单 | Text, part_use, app_part | 内部默认携带 Token |
| Microsoft TTS 接口 | 第三方 | /api/dv3admin_tts/Microsoft_tts_parameter_stream/ | 语音风格丰富,参数可精细控制 | LocalName, SpeakingSpeed, Pitch, Style, Volume | JWT 鉴权 |
| MoYinTTS 接口 | 第三方 | /api/dv3admin_tts/Microsoft_tts_parameter_stream/ (共用路径) | 兼容语音角色、语速、音调与风格选择 | Speaker, Style, Language, Symbolsil | JWT 鉴权 |
本地请求(在管理后台设置好参数)
本地语音合成接口通过后台预设参数实现对文本的直接转语音处理,无需依赖外部服务,适合在内网或资源受限环境中部署使用。接口支持流式音频返回,开发者可通过标准 POST 请求将目标文本传入,配合应用分区与用途标记,实现语音内容的分类存储与调试追踪。结合后台设置,音频将实时以二进制格式返回并可保存为标准音频文件,方便后续播放或嵌入式使用。
import requests
ts_config = {
"Text": "这样它就是不可变的11111", # 必填:需要合成的文本
"part_use": "测试文本转语音",
"app_part": "1"
}
# 请求的 URL
url = "http://localhost:8000/api/dv3admin_tts/tts_local_stream/"
# 发送 POST 请求,这里默认请求会携带 token
response = requests.post(url, json=ts_config)
# 处理响应
if response.status_code == 200:
file_format = "wav"
# 获取音频流(假设是 WAV 格式)
with open(f"output.{file_format}", 'wb') as f:
for chunk in response.iter_content(chunk_size=1024):
if chunk:
# print(chunk)
f.write(chunk)
print(f"语音合成文件已保存为 output.{file_format}")
else:
print(f"语音合成请求失败: {response.text}")
参数请求(应用三方工具请求服务用)
MicrosoftTTS
Microsoft TTS 接口提供丰富语音控制参数,涵盖语言、语音人物、语速、音调、风格、角色等定制选项,可用于打造更具表现力和拟人化的语音合成体验。通过 HTTP 请求方式传入完整参数配置,系统可实现流式音频输出,支持以 WAV 格式保存本地文件。该模式适用于对语音风格要求高的内容场景,如情感朗读、虚拟助手、故事播讲等,同时具备较强的语言适配能力。
import requests
# 请求头参考,
headers = {
"Host": "127.0.0.1:9000",
"Connection": "keep-alive",
"Content-Length": "842",
"Sec-Ch-Ua-Platform": "\"Windows\"",
"Authorization": "JWT xxxxxxx", # 这里验证 Authorization 的 token 值
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/132.0.0.0 Safari/537.36 Edg/132.0.0.0",
"Accept": "application/json, text/plain, */*",
"Sec-Ch-Ua": "\"Chromium\";v=\"132\", \"Microsoft Edge\";v=\"132\", \"Not A(Brand\";v=\"8\", \"Microsoft Edge WebView2\";v=\"132\"",
"Content-Type": "application/json",
"Sec-Ch-Ua-Mobile": "?0",
"Origin": "http://tauri.localhost",
"Sec-Fetch-Site": "cross-site",
"Sec-Fetch-Mode": "cors",
"Sec-Fetch-Dest": "empty",
"Referer": "http://tauri.localhost/",
"Accept-Encoding": "gzip, deflate, br, zstd",
"Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6"
}
microsoft_tts_config = {
"Text": "这样它就是不可变的11111", # 需要合成的文本
"Language": "zh-CN", # 语言设置,表示中文(简体),可选值为如 "en-US"(英语),"zh-CN"(中文简体)
"LocalName": "zh-CN-YunxiNeural", # 语音人物,指定要使用的语音模型,"zh-CN-YunxiNeural" 是中文女性语音
"SpeakingSpeed": "1", # 可选,语速调整(数值为倍速,如 "1" 为正常语速,"0.8" 为慢速,"1.5" 为加速)
"Pitch": "0", # 可选,音调调整,通常为相对百分比 -100% 到 100% 之间(如 "-50%" 表示较低音调,"+20%" 表示较高音调)
"Volume": "100", # 可选,音量设置,通常是 0 到 100 之间的值,表示音量的百分比(如 "50" 表示 50% 音量)
"Style": "embarrassed", # 可选,语音风格,指定语音的情感风格(如 "embarrassed" 表示害羞,"cheerful" 表示愉快)
"StyleDegree": 2, # 风格强度,控制语音风格的强度,通常值在 0.01 到 2 之间,1 为默认强度
"Role": "Narrator", # 可选,语音角色,模拟不同角色的发音,如 "Boy"(男孩)、"Girl"(女孩)、"Man"(男人)等
"StopTime": "0", # 可选,停顿时间,表示合成文本时的停顿,单位为毫秒(ms),如 "500ms" 表示停顿 500 毫秒,0 表示没有停顿
"OutputFormat": "riff-22050hz-16bit-mono-pcm", # 可选音频输出格式
"part_use": "测试文本转语音",
"app_part": "1"
}
# 请求的 URL
url = "http://localhost:8000/api/dv3admin_tts/Microsoft_tts_parameter_stream/"
# 发送 POST 请求
response = requests.post(url, json=microsoft_tts_config, heades=headers)
# 处理响应
if response.status_code == 200:
file_format = "wav"
# 获取音频流(假设是 WAV 格式)
with open(f"output.{file_format}", 'wb') as f:
for chunk in response.iter_content(chunk_size=1024):
if chunk:
# print(chunk)
f.write(chunk)
print(f"语音合成文件已保存为 output.{file_format}")
else:
print(f"语音合成请求失败: {response.text}")
MoYinTTS
MoYinTTS 接口基于参数控制实现中文语音的高保真合成,支持发音人选择、风格匹配、语速音调调整与停顿符号配置,适合用于产品播报、教学语音、语义提示等场景。接口结构与 Microsoft TTS 保持一致,便于统一接入与管理。通过后台路由共用语音合成通道,开发者可灵活切换不同 TTS 服务商,满足多样化音频生成需求,提升系统的语音输出弹性。
import requests
# 请求头参考,这里验证 Authorization 的 token 值
headers = {
"Host": "127.0.0.1:9000",
"Connection": "keep-alive",
"Content-Length": "842",
"Sec-Ch-Ua-Platform": "\"Windows\"",
"Authorization": "JWT xxxxxxx", # 这里验证 Authorization 的 token 值
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/132.0.0.0 Safari/537.36 Edg/132.0.0.0",
"Accept": "application/json, text/plain, */*",
"Sec-Ch-Ua": "\"Chromium\";v=\"132\", \"Microsoft Edge\";v=\"132\", \"Not A(Brand\";v=\"8\", \"Microsoft Edge WebView2\";v=\"132\"",
"Content-Type": "application/json",
"Sec-Ch-Ua-Mobile": "?0",
"Origin": "http://tauri.localhost",
"Sec-Fetch-Site": "cross-site",
"Sec-Fetch-Mode": "cors",
"Sec-Fetch-Dest": "empty",
"Referer": "http://tauri.localhost/",
"Accept-Encoding": "gzip, deflate, br, zstd",
"Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6"
}
moyin_tts_config = {
"Text": "这样它就是不可变的11111", # 必填:需要合成的文本
"Speaker": "魔云熙", # 可选:发音人(需要和官方支持的 speaker 名称一致)
"SpeakingSpeed": "1.0", # 可选:语速(0.5到2.0,字符串类型)
"Pitch": "0.0", # 可选:音调(-1到1,字符串类型,注意小写)
"Symbolsil": "exclamation_300", # 可选:符号停顿映射
"Style": "默认24K",
"Language": "普通话",
"part_use": "测试文本转语音",
"app_part": "1"
}
# 请求的 URL
url = "http://localhost:8000/api/dv3admin_tts/Microsoft_tts_parameter_stream/"
# 发送 POST 请求
response = requests.post(url, json=moyin_tts_config, heades=headers)
# 处理响应
if response.status_code == 200:
file_format = "wav"
# 获取音频流(假设是 WAV 格式)
with open(f"output.{file_format}", 'wb') as f:
for chunk in response.iter_content(chunk_size=1024):
if chunk:
# print(chunk)
f.write(chunk)
print(f"语音合成文件已保存为 output.{file_format}")
else:
print(f"语音合成请求失败: {response.text}")
总结
该插件实现了对 TTS 服务的集中接入与管理,覆盖本地服务与第三方模型,具备流式合成、语音风格控制与实时扣费等功能。通过前后端模块协同设计,支持从配置到调用的完整闭环,降低接入门槛,提高项目语音输出效率。
后续可拓展支持更多语音平台与语言模型,提升语音质量与响应速度。同时引入使用分析与调用优化机制,有助于建立稳定、高效的智能语音系统架构。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











