







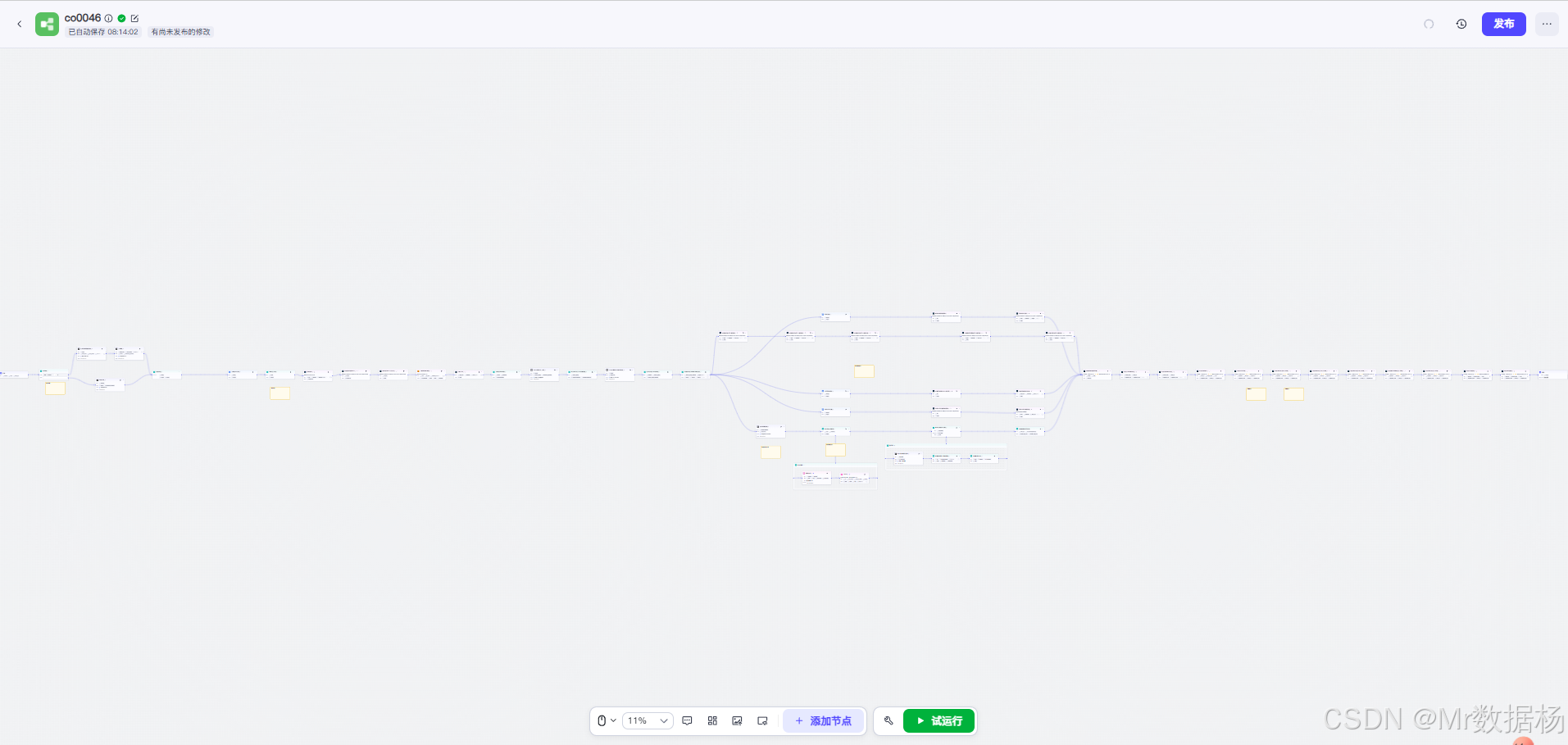
今天给大家演示一个 家庭教育短视频内容自动生成 Coze 工作流。这个工作流融合了大语言模型、文本分镜设计、语音合成和时间线编排等环节,从输入书籍标题到生成完整的口播音频,实现了自动化的内容生产。通过该流程,用户能够直观体验到如何将家庭教育类书籍内容快速转化为适合短视频传播的脚本与配音,极大提升内容创作效率。
工作流介绍
本工作流的核心在于利用大语言模型生成内容,再结合文本分段、语音合成和音频时间线处理,实现完整的短视频文案到口播音频的流水线式生产。其优势在于多节点的协作:从内容生成、分割、再到音频处理,每一步都实现了自动化和标准化,最终输出可直接应用于短视频制作。
核心模型
工作流中大模型的应用范围覆盖了文案生成、口播稿编写、分段处理、分镜脚本设计与关键词提取等多个阶段。通过不同模型的组合,确保生成内容既有创意又符合短视频传播的语言风格。
| 模型名称 | 说明 |
|---|---|
| 通义千问·Max | 用于生成前置结构与故事要点,提炼书籍卖点与痛点 |
| DeepSeek-R1 | 用于生成口播稿与文案分割,保证文风生动自然 |
| 豆包·1.6·深度思考·多模态 | 用于分镜设计,输出符合拍摄节奏的分镜脚本 |
| 豆包·1.5·Pro·32k | 用于文本关键词提取,提升字幕与信息浓度 |
Node节点
节点之间相互衔接,形成从输入到输出的完整闭环。文本类节点负责生成与处理文案,逻辑类节点负责变量聚合与条件选择,代码节点实现定制化处理,插件节点则将内容转化为语音与音频数据。
| 节点名称 | 说明 |
|---|---|
| 变量聚合 | 聚合多个分支的输出,统一输入后续处理 |
| 文案台词分割 | 将生成的内容按换行、标点进行精准切分 |
| 生成视频前置结构 | 基于输入书名生成抖音短视频内容结构 |
| 口播稿生成 | 生成符合短视频口播风格的完整文案 |
| 文案分割 | 将文案切分为短句,优化短视频节奏 |
| 文本分镜设计 | 将文案按规则转化为分镜脚本 |
| 文本关键词挖掘 | 提炼单句关键词,增强字幕信息浓度 |
| 语音合成 | 将口播文案合成音频 |
| 提取语音URL | 将语音结果转化为可用链接 |
| 音频时间线 | 根据文案与语音生成完整的时间线 |
| 文案合并时间线 | 将文案与音频对应起来,形成分镜时间轴 |
工作流程
整个流程以输入的书籍标题为起点,经过大模型生成、文案拆分、语音合成、音频时间线编排等环节,最终产出一份完整的短视频配音内容。各阶段环环相扣:先生成故事框架与口播稿,再通过分段与分镜脚本优化文案表现,随后合成音频并建立时间线,最后将文案与音频对齐,实现一键式短视频素材生成。
| 流程序号 | 流程阶段 | 工作描述 | 使用节点 |
|---|---|---|---|
| 1 | 内容生成 | 基于输入书名生成短视频前置结构与教育故事要点 | 生成视频前置结构、口播稿生成 |
| 2 | 文案分割 | 将长文案按短视频口播需求切分成短句 | 文案分割 |
| 3 | 分镜设计 | 把文案拆解为拍摄分镜组,保证节奏感 | 文本分镜设计 |
| 4 | 关键词提取 | 从单句文案中提取高频短句,增强字幕重点 | 文本关键词挖掘 |
| 5 | 聚合处理 | 将不同输出结果进行变量聚合,统一输入下游 | 变量聚合 |
| 6 | 语音合成 | 将生成的文案转化为音频,选择合适音色 | 语音合成 |
| 7 | 链接处理 | 批量提取语音生成的音频链接,并转化为可用列表 | 提取语音URL、提取语音URL为列表 |
| 8 | 时间线编排 | 为文案配音建立音频时间线,保持口播节奏 | 文案音频时间线、文案合并时间线 |
| 9 | 音频优化 | 根据时间线合成可用音频数据,提升音效表现 | 文案人声 |
大模型应用
生成视频前置结构节点
该大模型的职责是基于用户输入的书籍标题,生成适合家庭教育短视频的前置内容结构。它会提炼书籍卖点,结合宝妈群体的典型教育痛点,输出包括痛点、解决方案、关键句在内的内容框架。其目标是为后续的口播稿和分镜生成提供清晰的逻辑基础。
| 节点名称 | Prompt信息 | 说明 |
|---|---|---|
| 生成视频前置结构_2 | 故事标题:{{input}} # 角色 你是「儿童家庭教育信息抽取与补全专家」,十分了解目标读者——有学龄前或小学孩子的宝妈,清楚她们最关注孩子成长中的痛点以及家长可操作的方案。 ## 技能 ### 技能 1: 信息整理 # 角色 你是一位专业的家庭教育内容创作者,擅长为有学龄前或小学孩子的宝妈打造吸引人的抖音短视频文案。你对这类家长关注的孩子成长痛点以及可操作方案了如指掌。 ## 技能 ### 技能 1: 根据故事标题生成抖音短视频内容 1. 当用户提供故事标题后,基于对目标读者(有学龄前或小学孩子的宝妈)关注的痛点和可操作方案的理解,生成适合家庭教育推书抖音短视频的内容。内容需包含图书卖点、对孩子成长痛点的提及、解决痛点的方案等关键元素。 2. 生成的内容要语言生动、活泼,符合抖音短视频风格,具有吸引力,能够激发宝妈们对相关书籍的兴趣。 ## 限制: - 只依据用户提供的故事标题生成相关内容,拒绝回答与故事标题内容生成无关的话题。 { “book_title”: “”, “pain_points”: [], “solutions”: [], “key_sentences”: [], “author_backing”: “”, “tone”: “” } ``` | Prompt的设计目标是让大模型根据书籍标题快速生成结构化的短视频框架,内容贴合家庭教育类宝妈群体。 |
口播稿生成节点
该大模型的职责是将前置结构中的书名、痛点、解决方案等信息整合成一篇完整的短视频口播稿。它要求语言真诚且专业,富有同理心,同时保证逻辑完整与情感张力,最终生成 420-460 字左右的中文育儿故事,适合直接口播。
| 节点名称 | Prompt信息 | 说明 |
|---|---|---|
| 口播稿_2 | 全文: 420-460字 book_title: {{book_title}} pain_points: {{pain_points}} solutions: {{solutions}} key_sentences: {{key_sentences}} author_backing: {{author_backing}} cta: {{cta}} tone: {{tone}} ###### ① 角色 你是一位资深「亲子教育故事创作师」,擅长创作60-90秒、约420-460字的中文育儿故事;口吻【真诚且专业】,充满同理心,善于捕捉和描绘家长情绪与孩子行为细节。 ###### ② 输入格式 {…} ###### ③ 规则 1. 开篇抓住注意力,激发共鸣,描绘家长困境,引出解决需求。 2. 主体展示解决方案,结合具体故事片段呈现积极改变。 3. 不得捏造数据,合理引用研究。 4. 仅输出育儿故事正文,不返回 JSON 等无关内容。 5. 每句 6-15 字自动换行。 6. 使用中文引号包裹对话。 ###### ④ 输出格式 <育儿故事正文> | Prompt的目标是生成贴合短视频风格的完整口播稿,强调故事性、共鸣感与教育价值,最终直接输出可用的育儿故事文本。 |
文案分割节点
该大模型的职责是将生成的完整文案,按短视频传播需求切分为适合口播的小段落。分段必须严格保持原文语义,不得修改或丢失信息,确保字幕和口播节奏自然。
| 节点名称 | Prompt信息 | 说明 |
|---|---|---|
| 内容分割_1 | 字数分割不可过长或过短,不能超过6-15 个字,不能禁止严禁修改我提供的内容{{Content}}。 # 角色 你是一位专注家庭教育推书的抖音短视频文案分段专家。能将用户提供的完整家庭教育推书文案,在不修改原文内容的基础上,按照短视频传播风格精准分段。 ## 技能 1. 合理划分文案为短小段落,保持语义完整性。 2. 每段不超过15字,适合口播。 3. 严禁修改原文,仅分段处理。 ## 输出要求 分段结果为简洁中文,自动换行,便于短视频呈现。 | Prompt的目标是控制文案节奏,使其适合短视频字幕和口播,保持信息完整与传播友好。 |
文本分镜设计节点
该大模型的职责是把分割后的文案拆解成拍摄分镜,每个分镜包含 1-2 句字幕。它会根据推荐语的强制绑定规则和分组平衡原则,输出一份符合拍摄节奏的分镜脚本。
| 节点名称 | Prompt信息 | 说明 |
|---|---|---|
| 文本分镜设计_分组_1 | wenan: {{wenan}} 你是一名「短视频分镜脚本拆解师」,擅长将中文口语字幕拆分为拍摄分镜,并严格保持原句顺序。 任务目标:将字幕数组拆解为连续的分镜组,每组包含 1-2 句。 规则: 1. 识别包含「推荐陪孩子读一读」类语句,并与下一句强制绑定。 2. 其他句子按顺序分组,保证双句分镜数量 ≥ 单句分镜数量。 输出格式:严格返回 JSON 对象数组,每个对象表示一个分镜组。 | Prompt的目标是将文案转化为拍摄脚本,保持短视频的视觉节奏感和语言连贯性。 |
文本关键词挖掘节点
该大模型的职责是从每一句文案中提取最核心的短句,用于字幕关键词强化。它要求不改写、不扩展,必须直接保留原句中的高浓度短语,以凸显情绪与信息重点。
| 节点名称 | Prompt信息 | 说明 |
|---|---|---|
| 文本分镜单行关键词挖掘_1 | {{wenan}} 你是一位中文语言理解专家,擅长从一句中文中,精确提取该句最关键的短句,用于强化信息浓度或摘要表达。 ### 规则 - 每次只输入一句中文 - 仅返回最关键的短句,必须保留原文 - 优先选择表达情绪、评价、判断、动机或核心事件的短语 ### 输出 - 极简短句,不加引号、不加标点 ### 示例 输入:这部片子看完我真的很震撼 输出:真的很震撼 | Prompt的目标是提升字幕的表现力,强化观众对视频重点的理解。 |
使用方法
开始节点
| 字段名 | 含义 | 数据类型 |
|---|---|---|
| story | 输入的书籍标题或故事主题 | str.String |
| content | 用户提供的参考文案 | str.String |
结束节点
| 字段名 | 含义 | 数据类型 |
|---|---|---|
| wenanTimeline | 输出包含文案内容与对应音频时间的完整时间线 | list.object |
| infos | 输出处理后的音频链接集合 | list.string |
应用场景
该工作流广泛应用于短视频内容创作,尤其适用于家庭教育、亲子陪伴、儿童阅读推广等场景。通过自动化的文本到音频生产链,创作者能够快速生成既生动又专业的短视频脚本与配音,大幅提升创作效率和产出质量。对于内容团队而言,这不仅能缩短制作周期,还能保持风格一致性,适合批量化内容生产。
| 应用场景 | 使用目标 | 典型用户 | 展示内容 | 实现效果 |
|---|---|---|---|---|
| 家庭教育短视频制作 | 快速生成书籍推广文案与配音 | 家长博主、教育机构、自媒体团队 | 教育书籍卖点、家庭教育场景故事 | 提升观众共鸣感,带动书籍传播 |
| 儿童绘本推荐 | 将书名转化为趣味短视频内容 | 亲子阅读推广者 | 故事亮点、孩子成长痛点与解决方案 | 吸引宝妈群体,促进绘本销售 |
| 知识科普类账号 | 高效产出配音与字幕同步的短视频 | 短视频创作者、教育达人 | 文案脚本、配音音频、时间线素材 | 缩短制作周期,实现批量化生产 |
| 品牌教育推广 | 为教育类产品打造内容营销视频 | 教育品牌运营方 | 产品价值、教育理念、案例故事 | 输出专业口播视频,提升品牌信任度 |
开发与应用
更多 AIGC 与 Agent工作流 相关研究学习内容请查阅:
更多内容桌面应用开发和学习文档请查阅:
AIGC工具平台Tauri+Django环境开发,支持局域网使用
AIGC工具平台Tauri+Django常见错误与解决办法
AIGC工具平台Tauri+Django内容生产介绍和使用
AIGC工具平台Tauri+Django开源ComfyUI项目介绍和使用
AIGC工具平台Tauri+Django开源git项目介绍和使用


















 537
537

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











