






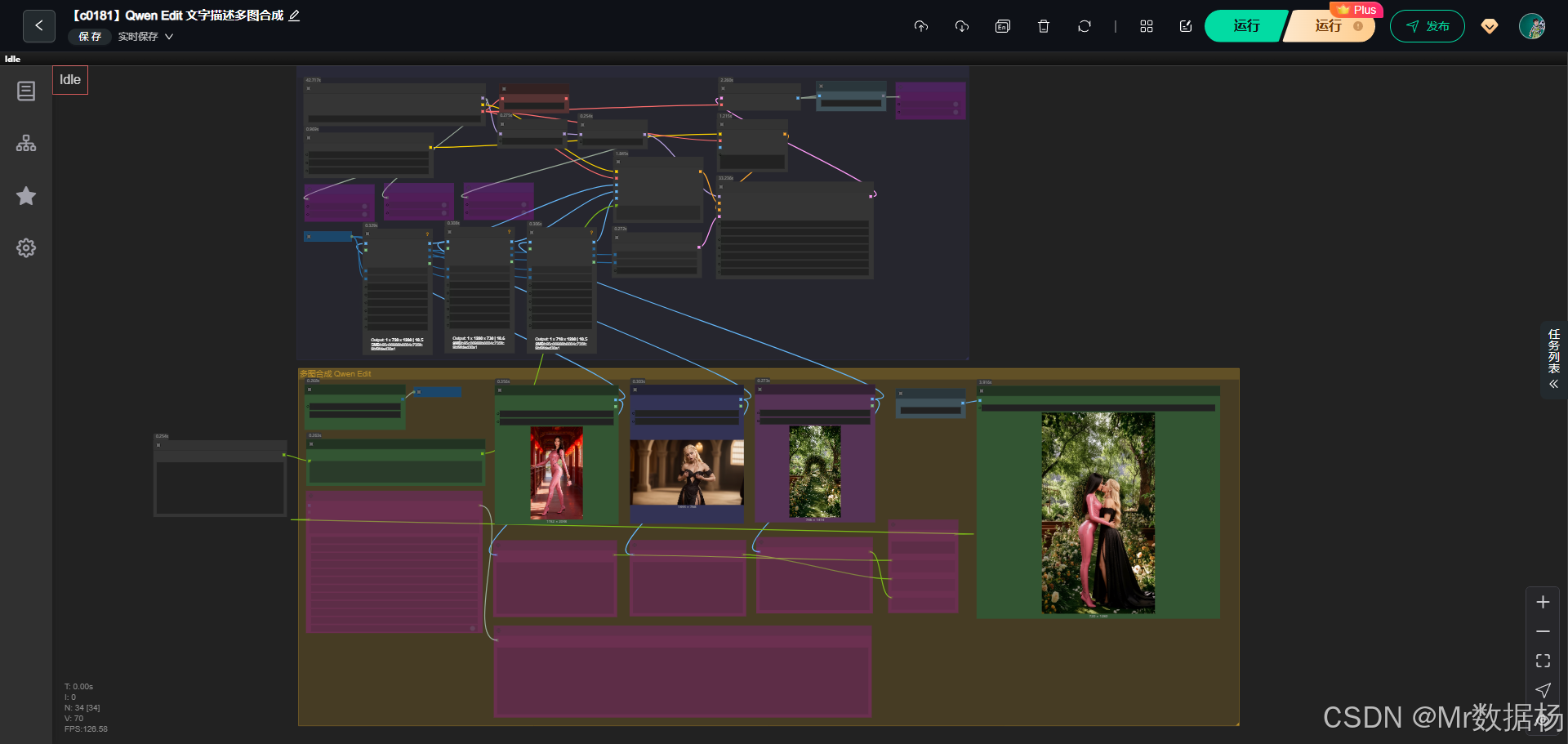
今天给大家演示的是一个利用 Qwen Edit 多图合成能力 的 ComfyUI 工作流。这个工作流通过加载三张参考图,分别代表人物、物体与背景,再结合文字描述和自动图像描述,让模型在统一场景中完成高一致性的图像重建与合成。

通过图像编码、条件组合、采样生成与最终解码输出,整个流程对多图融合与场景一致性控制能力做了非常完整的展示,是一个非常适合学习图像编辑增强与多图逻辑合成的典型示例。
工作流介绍
这个工作流围绕三张输入参考图展开,通过加载主模型、CLIP 编码器与 VAE,对图像进行统一尺寸调整后输入到 Qwen 图像编辑编码节点中,结合用户文本要求与模型自动生成的图像描述,构建出完整的条件文本。随后使用采样器生成潜空间结果,再通过 VAE 解码为最终图像输出。整体结构清晰,节点间逻辑紧凑,既能保证人物、物体、背景三方内容的完整保留,也能让合成后的画面实现光影一致、透视统一。
核心模型
核心模型部分主要由基础生成模型、文本编码器和 VAE 组成。CheckpointLoaderSimple 加载整体工作流的底层模型,配合 CLIPLoader 提供文本与图像的双向理解能力,再由 VAE 负责潜空间图像的最终解码输出。它们共同构成图像编辑与多图融合的技术核心,使整个工作流既能理解参考图,又能根据多重文本控制渲染准确的画面。
| 模型名称 | 说明 |
|---|---|
| Qwen-Rapid-AIO-SFW-v5.safetensors | 主生成模型,处理多图合成与图像编辑的核心权重来源。 |
| qwen_2.5_vl_7b_fp8_scaled.safetensors | CLIP 文本图像编码器,用于理解提示词与输入参考图。 |
| VAE(由 CheckpointLoaderSimple 输出) | 图像解码模块,将潜空间的采样结果还原为最终图像。 |
Node节点
工作流由多种节点协同运作,包括图像加载节点、图像缩放节点、文本描述生成节点、条件编码节点、采样节点与输出节点。图像加载节点负责处理三张参考图;文本生成节点自动分析图像内容;条件编码节点将人物、物体、背景三方逻辑融合到 Prompt 中;采样器生成潜图;最后由 VAE 解码与保存节点输出最终结果。这些节点组合实现了从输入到输出的完整自动化流程。
| 节点名称 | 说明 |
|---|---|
| LoadImage | 加载三张参考图作为人物、物体、背景的输入。 |
| ImageResizeKJv2 | 将多张图调整到统一分辨率,方便后续编码处理。 |
| RH_Captioner | 自动生成图像详细描述文本。 |
| TextConcatenator | 将多段描述与提示词组合成最终 Prompt。 |
| TextEncodeQwenImageEditPlus | 将文本与图像编码为模型可理解的条件信息。 |
| KSampler | 根据条件信息进行潜空间采样生成。 |
| VAEDecode | 将采样生成的潜图解码为最终图像。 |
| SaveImage | 保存结果图像。 |
工作流程
整个工作流程从三张参考图开始,通过统一分辨率处理与自动内容理解,将人物、物体与背景的多源信息汇聚到同一个条件体系中,再结合用户提供的文本逻辑提示,生成高一致性的合成画面。流程中图像经过加载、缩放处理后由 Captioner 自动生成精准描述,再与用户文本指令合并,随后进入 Qwen 图像编辑编码节点。采样器基于这些条件在潜空间中生成最终图像结构,最后通过 VAE 解码得到清晰成品。整个过程自动化程度高,节点之间协作紧密,让生成结果在内容保持与场景融合上都十分自然。
| 流程序号 | 流程阶段 | 工作描述 | 使用节点 |
|---|---|---|---|
| 1 | 输入准备 | 加载三张参考图(人物、物体、背景),统一图像尺寸 | LoadImage、ImageResizeKJv2 |
| 2 | 图像理解 | 自动生成三张图的详细描述文本 | RH_Captioner |
| 3 | 文本整合 | 将用户文本与三条图像描述合并成最终提示词 | TextConcatenator、Text Multiline、JjkText |
| 4 | 条件编码 | 处理文本提示与图像条件信息,生成模型可识别的 CONDITIONING | TextEncodeQwenImageEditPlus |
| 5 | 模型采样 | 根据条件在潜空间生成图像结构 | KSampler |
| 6 | 解码输出 | 将潜图解码成最终图像,并保存 | VAEDecode、SaveImage |
大模型应用
RH_Captioner 图像语义理解与描述生成
RH_Captioner 的任务是读取输入图片并输出精确、可控的文字描述,用来补充场景语义。当工作流需要理解人物、物体或背景的视觉内容时,这个节点负责将图像转换成语言,使下游的合成逻辑拥有更清晰的语义基础。该节点的 Prompt 决定描述的细节密度、风格倾向,影响后续生成结果的稳定性与内容一致性。
| 节点名称 | Prompt 信息 | 说明 |
|---|---|---|
| RH_Captioner | Please provide a detailed description of this image. If any characters in the image are familiar to you, such as celebrities, movie characters, or animated figures, please directly use their names. The description should be as detailed as possible, but should not exceed 200 words. | 将图像内容转为结构化语言,为人物、物体、背景提供语义基础,供后续 Prompt 拼接与条件编码使用。 |
Qwen3VLProcessor 文本控制与语义生成核心
Qwen3VLProcessor 是工作流中唯一执行自由文本推理的大模型节点。它基于合成后的 Prompt 生成最终控制语义,决定图像融合方式、结构一致性、人物与物体的摆放逻辑等。Prompt 在这里承担关键作用,无论是用户自定义要求,还是三张图的自动描述,都会在此节点被整合为最终的语义指令,直接影响成片质量、画面合理性与一致性。
| 节点名称 | Prompt 信息 | 说明 |
|---|---|---|
| Qwen3VLProcessor | Use the person exactly as shown in the reference image. Do not change the face, body shape, hairstyle, outfit, or pose structure. Use the object exactly as shown in its reference. Place or hold the object naturally with the person. Do not duplicate the object, do not place it on the floor, and do not change its design. Use the background exactly as shown in the background reference. Do not alter the architecture, perspective, lighting, or layout. Combine the person, the object, and the background into a single consistent scene. Keep everything visually consistent with the three references. Do not regenerate or redesign any part of the person, the object, or the background. | 整合所有文本信息,生成最终语义控制,确保人物、物体、背景一致性,决定画面合成逻辑与质量。 |
使用方法
整个工作流的运行逻辑基于“输入三张参考图 + 文本控制”的自动化流程。用户只需替换人物图、物体图与背景图,系统就会自动进行图像尺寸统一、图像内容分析、Prompt 组合、条件编码与生成渲染。三张图像的意义分别是:人物图用于保持主体外观一致,物体图用于指定要融合的物品,背景图用于提供最终场景。用户输入的 Prompt 用于控制图像合成方式、情绪氛围、动作关系与内容风格。替换素材后,无需手动画框或设置复杂参数,工作流会自动重建一个连贯、真实且符合要求的最终画面。
| 注意点 | 说明 |
|---|---|
| 图像需主体明确 | 人物、物体、背景最好结构清晰,否则 Captioner 描述会不准确。 |
| Prompt 清晰直接 | 文字要求越明确,合成画面越容易保持一致性。 |
| 三图内容需逻辑匹配 | 例如人物姿势与物体使用方式需可融合,避免生成不自然的画面。 |
| 图像分辨率不要过低 | 过低分辨率会降低 Captioner 与模型理解能力。 |
| 不要在 Prompt 中加入互相矛盾的描述 | 避免干扰最终合成效果与内容一致性。 |
应用场景
这个工作流适用于任意需要保持人物原貌、物体原样与背景结构完整的多图合成任务。它能将多个参考元素自然融合成一个统一场景,不改变本体细节,同时确保透视、光线与整体氛围一致,非常适合写真人像融合、再现特定场景构图、商业拍摄替代图等需求。典型用户包括摄影师、设计师、短视频创作团队与需要高度一致性画面的商业制作者。最终生成内容直观、干净、还原度高,让多源素材在同一画面中毫无违和感。
| 应用场景 | 使用目标 | 典型用户 | 展示内容 | 实现效果 |
|---|---|---|---|---|
| 多图融合与合成场景 | 保留三张参考图主体特征并自然融合 | 设计师、摄影师、CG 创作者 | 人物、物体、背景统一场景图像 | 保真度高、光影一致、无违和融合 |
开发与应用
更多 AIGC 与 ComfyUI工作流 相关研究学习内容请查阅:
更多内容桌面应用开发和学习文档请查阅:
AIGC工具平台Tauri+Django环境开发,支持局域网使用
AIGC工具平台Tauri+Django常见错误与解决办法
AIGC工具平台Tauri+Django内容生产介绍和使用
AIGC工具平台Tauri+Django开源ComfyUI项目介绍和使用
AIGC工具平台Tauri+Django开源git项目介绍和使用


















 704
704

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











