






用例设计方法
(一)等价类划分
常见的软件测试面试题划分等价类: 等价类是指某个输入域的子集合.在该子集合中,各个输入数据对于揭露程序中的错误都是等效的.并合理地假定:测试某等价类的代表值就等于对这一类其它值的测试.因此,可以把全部输入数据合理划分为若干等价类,在每一个等价类中取一个数据作为测试的输入条件,就可以用少量代表性的测试数据.取得较好的测试结果.等价类划分可有两种不同的情况:有效等价类和无效等价类.
(二)边界值分析法
边界值分析方法是对等价类划分方法的补充。测试工作经验告诉我,大量的错误是发生在输入或输出范围的边界上,而不是发生在输入输出范围的内部.因此针对各种边界情况设计测试用例,可以查出更多的错误.
使用边界值分析方法设计测试用例,首先应确定边界情况.通常输入和输出等价类的边界,就是应着重测试的边界情况.应当选取正好等于,刚刚大于或刚刚小于边界的值作为测试数据,而不是选取等价类中的典型值或任意值作为测试数据.
(三)错误推测法
基于经验和直觉推测程序中所有可能存在的各种错误, 从而有针对性的设计测试用例的方法.
错误推测方法的基本思想: 列举出程序中所有可能有的错误和容易发生错误的特殊情况,根据他们选择测试用例-例如, 在单元测试时曾列出的许多在模块中常见的错误-以前产品测试中曾经发现的错误等, 这些就是经验的总结。还有, 输入数据和输出数据为0的情况。输入表格为空格或输入表格只有一行-这些都是容易发生错误的情况。可选择这些情况下的例子作为测试用例.
(四)因果图方法
前面介绍的等价类划分方法和边界值分析方法,都是着重考虑输入条件,但未考虑输入条件之间的联系, 相互组合等-考虑输入条件之间的相互组合,可能会产生一些新的情况-但要检查输入条件的组合不是一件容易的事情, 即使把所有输入条件划分成等价类,他们之间的组合情况也相当多-因此必须考虑采用一种适合于描述对于多种条件的组合,相应产生多个动作的形式来考虑设计测试用例-这就需要利用因果图(逻辑模型)-因果图方法最终生成的就是判定表-它适合于检查程序输入条件的各种组合情况.
(五)正交表分析法
有时候,可能因为大量的参数的组合而引起测试用例数量上的激增,同时,这些测试用例并没有明显的优先级上的差距,而测试人员又无法完成这么多数量的测试,就可以通过正交表来进行缩减一些用例,从而达到尽量少的用例覆盖尽量大的范围的可能性。
(六)场景分析方法
指根据用户场景来模拟用户的操作步骤,这个比较类似因果图,但是可能执行的深度和可行性更好。
Jmeter
提取器
边界提取器,xpath,json,正则提取器一般使用Jmeter的步骤:
- 新建一个线程组。
- 然后就是新建一个HTTP请求默认值。(输入接口服务器IP和端口)
- 再新建很多HTTP请求,一个请求一个用例。(输入接口路径,访问方式,参数等。)
- 然后创建断言和查看结果树。
Jmeter的关联方法
- 接口返回结果通常为Html和Json格式
- 主要用到正则提取、Json提取、Xpath提取和边界值提取还有beanshell
- 对于Html这种格式通常用正则或者Xpath来提取
- 对于Json这种格式通常用Json提取器
Linux
-n 是显示行号;相当于nl命令
head: 看前多少行日志
head -n 10 test.log 查询日志文件中的头10行日志;
head -n -10 test.log 查询日志文件除了最后10行的其他所有日志;
tail: 看后多少行日志
tail -100f test.log 实时监控100行日志
tail -n 10 test.log 查询日志尾部最后10行的日志;
tail -n +10 test.log 查询10行之后的所有日志;
cat:
一次正序显示整个文件。cat filename
cat -n test.log |grep "debug" 查询关键字的日志
tac:
一次逆序显示整个文件。tac filename
cd:
cd 路径:表bai示切换du到这个路径下
cd ~:表示切换到当前这个登录的用户的主文件夹下,比如当前用户名是name,就是切换到/home/name/;当前用户是root,就是切换到/root/目录。
cd ~name:表示切换到名字叫name的用户的主文件夹下。
cd ..:(两个点号)表示切换到当前目录的上一层目录。
cd -(英文减号)表示回到刚才切换的目录,取决于你的上一个cd操作。
pwd:展示当前所在路径
mkdir:创建文件夹
touch:创建文件
rm -rf 文件名或者文件路径
查看后台所有java进程
ps -ef | grep java
结束后台进程
kill+进程编号
强制结束后台进程
kill -s 9 进程编号ps -ef | grep java 是一个在 Unix 和 Linux 系统上常用的命令组合,用于查找与 Java 相关的进程。
这里是对该命令的详细解释:
ps -ef:
ps 是 "process status" 的缩写,用于显示当前系统的进程状态。
-e 选项表示列出所有进程。
-f 选项表示使用完整的格式显示进程信息,通常包括 UID、PID、PPID、C、STIME、TTY、TIME 和 CMD。
| (管道):
管道是 Unix/Linux 中的一个重要概念,用于将一个命令的输出作为另一个命令的输入。
grep java:
grep 是一个强大的文本搜索工具,允许你在文本中搜索特定的字符串或模式。
在这里,grep java 用于搜索包含 "java" 字符串的行。
因此,ps -ef | grep java 的整体意思是:列出系统上的所有进程,并搜索那些与 "java" 相关的进程。
当你运行这个命令时,你可能会看到与 Java 相关的进程信息,例如 Java 应用程序、Java 虚拟机(JVM)或任何与 Java 相关的工具或守护进程。
注意:这个命令也会显示 grep java 进程本身,因为它也包含了 "java" 字符串。要排除这个进程,你可以使用更复杂的命令,如 ps -ef | grep java | grep -v grep。这里,grep -v grep 会排除包含 "grep" 字符串的行。数据库
INSERT INTO table_name (列1, 列2,...) VALUES (值1, 值2,....)
UPDATE 表名称 SET 列名称 = 新值 WHERE 列名称 = 某值
DELETE FROM 表名称 WHERE 列名称 = 值
SELECT Persons.LastName, Persons.FirstName, Orders.OrderNo
FROM Persons
LEFT JOIN Orders
ON Persons.Id_P=Orders.Id_P
ORDER BY Persons.LastName
ORDER BY Company 降序DESC, id升序 ASC
order by 默认按照 ASC 升序排列
max(id),最小 min(id)(一)为什么要使用数据库?
1)数据永久保存
2)使用SQL语句,查询方便效率高。
3)管理数据方便
(二)什么是SQL?
结构化查询语言(Structured Query Language)简称SQL,是一种数据库查询语言。
作用:用于存取数据、查询、更新和管理关系数据库系统。
(三)什么是死锁?怎么解决?
死锁是指两个或多个事务在同一资源上相互占用,并请求锁定对方的资源,从而导致恶性循环的现象。
常见的解决死锁的方法
1、如果不同程序会并发存取多个表,尽量约定以相同的顺序访问表,可以大大降低死锁机会。
2、在同一个事务中,尽可能做到一次锁定所需要的所有资源,减少死锁产生概率;
3、对于非常容易产生死锁的业务部分,可以尝试使用升级锁定颗粒度,通过表级锁定来减少死锁产生的概率;
如果业务处理不好可以用分布式事务锁或者使用乐观锁
(四)什么是游标?
游标是系统为用户开设的一个数据缓冲区,存放SQL语句的执行结果,每个游标区都有一个名字。用户可以通过游标逐一获取记录并赋给主变量,交由主语言进一步处理。
(五)改
修改t_sales表中id值为3的记录,将asales改为6900
UPDATE t_sales SET asales = 6900 WHERE id = 3;(六)删
删除表中id为5的数据
DELETE FROM t_sales WHERE id = 5;(七)查
查询student表的第2条到4条记录
SELECT * FROM student LIMIT 1,3计算并查询出表score中计算机的平均分数
select AVG(grade) from score where c_name="计算机"
计算并查询出表score中计算机的最低/最高分数
select MIN(grade) from score where c_name="计算机"
select max(grade) from score where c_name="计算机"
查询出表score中计算机的信息按照分数倒序排列(desc是逆序排序,asc是正序排序,asc可省略不写)
select * from score where c_name="计算机" order by grade desc查询李四的考试科目(c_name)和考试成绩(grade)
SELECT c_name, grade FROM score WHERE stu_id = (SELECT id FROM student WHERE name= '李四' );
查询计算机成绩低于95的学生信息
SELECT * FROM student WHERE id IN (SELECT stu_id FROM score WHERE c_name="计算机" and grade<95);
(八)group by 和order by的区别
order by用于排序,一般和升序/降序一起使用。
group by用于分类汇总,一般和汇集函数sum,max,min等一起使用。
一起使用的时候,group by要在order by前面
(九)group by
GROUP BY 是 SQL 中的一个非常重要的子句,它通常与聚合函数(如 SUM(), AVG(), MAX(), MIN(), COUNT() 等)一起使用,用于将来自表中的多行数据组合成较小的汇总行。简而言之,GROUP BY 子句允许你根据一个或多个列对结果集进行分组,并对每个分组执行聚合操作。
基本用法
假设有一个名为 sales 的表,它记录了销唀数据,包括 date(销售日期)、product_id(产品ID)和 amount(销售额)等字段。
如果你想计算每个产品的总销售额,你可以使用 GROUP BY 子句结合 SUM() 函数来实现:
sql
SELECT product_id, SUM(amount) AS total_sales
FROM sales
GROUP BY product_id;
这个查询会按照 product_id 对销售记录进行分组,并计算每个产品的总销售额(amount 的总和)。
多列分组
你也可以根据多个列来分组数据。比如,如果你想按产品和销售年份来计算总销售额,可以这样做:
sql
SELECT YEAR(date) AS sale_year, product_id, SUM(amount) AS total_sales
FROM sales
GROUP BY YEAR(date), product_id;
这里,我们首先使用 YEAR(date) 函数从 date 字段中提取年份,然后按年份和产品ID对销售记录进行分组。
注意事项
当使用 GROUP BY 时,SELECT 列表中未包含在聚合函数中的每个列都必须包含在 GROUP BY 子句中。
如果你在 SELECT 列表中使用了聚合函数,但 GROUP BY 子句为空或未包含所有非聚合列,SQL 可能会返回错误或不确定的结果,具体取决于数据库系统。
不同的数据库系统(如 MySQL、PostgreSQL、SQL Server 等)在处理 GROUP BY 和非聚合列时可能有细微的差别。
示例
假设 sales 表有以下数据:
date | product_id | amount
------------|------------|--------
2023-01-01 | 1 | 100
2023-01-02 | 1 | 150
2023-01-01 | 2 | 75
2023-01-02 | 2 | 125
执行上面的第一个查询后,你可能会得到如下结果:
product_id | total_sales
-----------|------------
1 | 250
2 | 200
这表明产品 1 的总销售额为 250,产品 2 的总销售额为 200。GIT

一、本地克隆地址
git clone 代码地址二、创建分支
git branch feature2三、推送分支到仓库
git push --set-upstream origin feature2 //远程推送feature2分支(推送到仓库)四、切换到feature2
git checkout feature2 //切换到 feature2分支五、查看当前所在分支文件状态
git status //查看当前所在分支文件状态六、添加需要改的到缓存区
git add 文件名 //添加未跟踪文件
git add . //添加所有文件七、讲缓存区更新到分支并添加备注
git commit -m “message”八、推送分支到远程仓库
git pushGit是一个开源的分布式版本控制系统,用于敏捷高效地处理任何或小或大的项目。以下是Git命令的详细大全,这些命令涵盖了Git的基本操作、分支管理、远程仓库操作、撤销修改等多个方面:
一、基本配置
查看和设置用户信息
查看用户名和邮箱:git config --list
设置用户名和邮箱(全局):git config --global user.name "用户名"、git config --global user.email "邮箱"
初始化仓库
初始化当前目录为Git仓库:git init
初始化指定目录为Git仓库:git init [project-name]
二、工作区与暂存区
查看状态
查看当前仓库状态:git status
添加文件到暂存区
添加指定文件到暂存区:git add [file1] [file2] ...
添加当前目录的所有文件到暂存区:git add .
停止追踪指定文件,但保留文件在工作区:git rm --cached [file]
撤销修改
撤销工作区的修改(尚未add):git checkout -- [file]
撤销暂存区的修改(已add,未commit):git reset HEAD [file]
三、提交与查看历史
提交
提交暂存区到仓库区:git commit -m "提交信息"
提交工作区自上次commit之后的变化:git commit -a -m "提交信息"
修改最后一次提交信息:git commit --amend -m "新的提交信息"
查看历史
查看提交历史:git log
查看简洁的提交历史:git log --pretty=oneline
查看提交日志(图像模式):git log --graph
查看某个文件的版本历史:git log --follow [file]
四、分支管理
查看分支
查看所有本地分支:git branch
查看所有远程分支:git branch -r
查看所有本地和远程分支:git branch -a
创建与切换分支
创建新分支并切换到该分支:git checkout -b [branch-name]
切换分支:git checkout [branch-name]
合并分支
合并指定分支到当前分支:git merge [branch]
删除分支
删除本地分支:git branch -d [branch-name]
强制删除本地分支:git branch -D [branch-name]
删除远程分支:git push origin --delete [branch-name]
五、远程仓库
查看远程仓库
查看远程仓库信息:git remote -v
克隆远程仓库
克隆远程仓库到本地:git clone [url]
克隆远程仓库的指定分支:git clone -b [branch-name] [url]
推送与拉取
推送本地分支到远程仓库:git push [remote] [branch]
强制推送:git push [remote] [branch] --force
拉取远程仓库的最新代码:git pull [remote] [branch]
六、撤销与重置
版本回退
回退到上一个版本:git reset --hard HEAD^
回退到指定版本:git reset --hard [commit-id]
撤销已提交的版本
撤销某次提交并创建新的提交:git revert [commit-id]
七、其他常用命令
忽略文件
创建.gitignore文件,并添加需要忽略的文件或目录。
查看差异
查看工作区与暂存区的差异:git diff
查看暂存区与最近一次提交的差异:git diff --cached
查看工作区与最近一次提交的差异:git diff HEAD
查看所有分支的提交历史
使用git log --graph --all --decorate --oneline命令可以查看所有分支的提交历史,并显示分支名和标签。
以上仅为Git命令的一部分,APP专项
性能指标
1、响应
2、内存
3、CPU
4、FPS (app使用的流畅度)
5、GPU渲染
6、电量
7、流量
内存泄露 memory leak
是指程序在申请内存后,无法释放已申请的内存空间,一次内存泄露危害可以忽略,但内存泄露堆积后果很严重,无论多少内存,迟早会被占光。
内存泄漏是指你向系统申请分配内存进行使用(new),可是使用完了以后却不归还(delete),结果你申请到的那块内存你自己也不能再访问(也许你把它的地址给弄丢了),而系统也不能再次将它分配给需要的程序。
内存溢出
就是你要求分配的内存超出了系统能给你的,系统不能满足需求,于是产生溢出。 一个盘子用尽各种方法只能装4个果子,你装了5个,结果掉倒地上不能吃了。这就是溢出!比方说栈,栈满时再做进栈必定产生空间溢出,叫上溢,栈空时再做退栈也产生空间溢出,称为下溢。就是分配的内存不足以放下数据项序列,称为内存溢出。
1、网络测试
可使用抓包工具辅助网格测试推荐:fiddler,Charles
(1)网络切换
2G-3G-4G-wifi-网络信号差--无网
(2)网络信号弱
关注是否出现ANR、crash2、中断测试
(1)意外中断
a、来电
b、短信
c、闹铃
d、断网
e、断电
f、视频聊天
g、语音聊天
h、无响应
i、系统更新提醒
j、内存不足提醒
k、其他app的消息通知
(2)任务切换
a、锁屏
b、切换到其他应用3、兼容测试
(1)不同的机型
(2)不同的操作系统版本注意:app兼容测试方法
(1)手工测试(一般适用于用户量小、且对兼容测试要求不高的项目)
(2)云测试平台(一般适用于用户量大、且对兼容测试要求高的项目)
目前市场上主流云测试平台包括:
(1)腾讯云测:
http://wetest.qq.com(2)百度云测:
http://mtc.baidu.com(3)阿里云测:
http://mqc.aliyun.com/(4)testin云测:
https://www.testin.cn/4、性能测试
(1)客户端性能测试
a、流量消耗
b、耗电量
c、CPU
d、内存消耗
(2)服务器端性能测试5、UI测试
(1)横竖屏切换
(2)手势操作
a、长按呼出菜单
b、双手捏合放大放小
c、滑动
(3)输入信息界面自适应键盘遮挡
(4)其他UI测试要点与web基本相同6、安全测试
(1)密码不明文显示
(2)密码框不支持复制
(3)敏感信息加密传输
(4)多次登录失败,锁定账号
(5)登录成功后,长时间不操作软件,session是否丢失,提示重新登录
(6)权限控制
(7)SQL注入7、稳定性测试(使用monkey完成)
8、安装测试
(1)安装前
a、干净的安卓系统
b、装有旧版本的安卓系统
c、装有本版本的安卓系统
d、装有最新版本的安卓系统(需要安装旧版本)
e、装有杀毒软件的安卓系统
f、装有同行业其他软件的安卓系统
g、内存不足的安卓系统
(2)安装过程中
a、意外中断
b、许可确认提示
c、是否显示安装进度
(3)安装后
a、软件是否可以正常启动
b、检查安装文件是否齐全
c、检查许可权限
d、统计安装总时长9、升级测试
(1)自动升级
(2)弹出是否升级的提示,人工选择
(3)升级过程中意外中断
(4)升级过程中内存不足
(5)升级后数据是否同步
(6)app运行状态下升级
(7)跨版本升级测试10、卸载测试
(1)大型app考虑卸载过程中意外中断
(2)app处于运行状态下进行卸载
(3)app卸载后,对应的文件是否删除
(4)卸载后,重新再次安装该版本app
(5)是否弹出卸载确认提示11、接口测试(需求抓包工具辅助)
(1)系统内模块间的接口
(2)系统外第三方接口(有界面,主调)
(3)系统外被调接口(无界面,需要接口测试工具模拟发送请求)
12、其他测试
(1)支持文件格式
a)图片上传
b)视频上传
c)文件上传APP测试需要的工具
一、adb测试工具
adb:android debug bridge,安卓调试桥梁,一款用于连接电脑与安卓手机的工具
1、adb get-serialno 获取序列号:
2、adb devices:用于查看电脑当前连接的安卓设备
3、adb install apk文件包:在安卓设备上安装app
注意:若当前电脑连接的安卓设备2台及以上,可通过以下命令完成安装:
adb -s 设备序列号 install apk文件包
install -r 覆盖安装,保留数据和缓存文件 -d 解决低版本version问题 -s 安装apk到sd卡
4、adb uninstall app软件包名:卸载app
uninstall 可选参数-k的作用为卸载软件但是保留配置和缓存文件
5、adb shell:进入adb运行环境
5.1、adb [-d|-e|-s <serial Number>] <command>
-d:真机(多个设备中只有一个真机时适用)
-e:模拟器(多个设备中只有一个模拟器时适用)
-s:序列号
5.2、adb shell ls [-al] 列出目录下的文件和文件夹,可选参数-al可查看文件和文件夹的详细信息
5.3、adb shell cd <folder> 进入文件夹
5.4、adb shell cat <filename> 查看文件
5.5、adb shell rename path/oldfilename path/newfilename 重命名文件
5.6、adb shell rm -r <folder> -r 可选参数用于删除文件夹及下面的所有文件
5.7、adb shell mv path/1 path/2 移动文件
5.8、adb shell cp file path/1 拷贝文件
5.9、adb shell mkdir path/1 创建目录
5.10、adb shell chmod 777 filename 设置文件最高读写权限
6、adb push 电脑端路径及文件 手机端路径:将电脑端指定的文件传输到手机指定的路径中
7、adb pull 手机端路径及文件 电脑端路径:将手机端指定的文件传输到电脑端指定的路径中
8、adb logcat 查看log:
安卓系统中生成的日志,有哪些级别?
I:信息
V:冗(rong)余 (最低优先级)
D:调试
W:警告
E:错误
F:严重错误
S — 静默 (最高优先级,不会打印任何信息)
日志格式:adb logcat -s 过滤指定参数log -v time 保留日志时间 >> 追加写 > 覆盖写
日志过滤:adb -e logcat 标签名:级别>1.txt 或者使用grep过滤adb logcat | grep "SEARCH_TERM"
如:adb -e logcat taobao:w>11.txt
将w级别及其以上级别日志,且含taobao标签的所有日志保存到11.txt中
如:adb -e logcat *:w>11.txt
将w级别及其以上级别日志,所有日志保存到11.txt中
使用来清除旧的日志
adb logcat -c
9、adb reboot 重启机器:
10、adb reboot [bootloader|recovery] 重启设备,可选参数进入bootloader(刷机模式)或recovery(恢复模式)
11、adb shell am start -n package_name 启动应用
12、adb kill-server 终止adb服务进程:
13、adb start-server 重启adb服务进程:
14、adb help 获取帮助 里面有adb的各种命令和参数的介绍
15、adb version 查看adb版本
16、adb root 以root权限重启adb
17、adb remount 将system分区重新挂在为可读写分区,此命令在操作系统目录时很重要
18、adb shell pm path <package_name> 查看app的路径
18.1、adb shell pm list packages 查看所有App的名称查看手机上的APP名称。可以在后面加上 -f
19、adb shell dumpsys package <package_name> | grep version 查看apk的版本信息
20、adb shell pm clear <PACKAGE> 删除与包相关的所有数据:清除数据和缓存
21、adb shell ps <package_name|PID> 【 adb shell ps | grep <package_name>】 查看某个app的进程相关信息
22、adb shell kill pid Number杀掉某个进程,一般用于模拟某个bug复现
23、adb shell dumpsys meminfo <package_name|PID> 查看某一个app的内存占用
24、adb shell getprop | grep heapgrowthlimit 查看单个应用程序的最大内存限制
25、adb shell dumpsys batterystats ><package_name> > xxx.txt 获取单个应用的电量消耗信息
26、adb shell wm size【adb shell dumpsys window | grep Surface】 查看手机分辨率
27、adb shell getprop | grep version 查看手机sdk版本
28、adb shell getprop | grep product 查看手机型号信息
29、 adb shell cat /proc/meminfo 查看系统当前内存占用
30、adb shell top 查看设备上进程的cpu和内存占用情况
31、adb shell screencap /sdcard/screen.png 命令来进行手机屏幕截图
32、adb shell screenrecord /sdcard/demo.mp4 命令来录制屏幕视频
33、adb shell input 模拟按键/输入
33.1、adb shell input text "insert%stext%shere" 命令向屏幕输入框输入一些信息%s表示空格
33.2、adb shell input tap 500 1450 模拟屏幕点击事件
33.3、adb shell input swipe 100 1500 100 450 100 模拟手势滑动事件表示从屏幕坐标(100,1500)开始,滑动到(100,450)结束,整个过程耗时100ms. 【adb shell input swipe 100 500 100 500 500】模拟长按事件
33.4、adb shell input keyevent 模拟点按实体按钮的命令二、monkey
1、使用场合:主要用于app的稳定性测试。安卓系统自带的一款工具。
2、原理:通过发送大量的随机事件,测试手机或某app的稳定性。
3、adb shell monkey 事件数>日志文件:测试手机的稳定性
4、monkey命令的基本参数
(1)-p app软件包名
注意:若需要同时往多个app发送随机事件,增加-p app软件包名2即可
如:
adb shell monkey -p 软件包名1 -p 软件包名2 事件数>日志文件
(2)日志详细级别:
-v:详细级别为1等级
-v -v
-v -v -v
ANR:应用程序无响应,application not responding
数
(3)增加事件延迟
--throttle 毫秒数
(4)-s 种子数
5、monkey的事件类型
(1)--pct-touch 百分比:触摸事件
注意:百分比可书写为70或70%,多种事件百分比相加不能大于100%
(2)--pct-motion 百分比:滑动事件
如:adb shell monkey -p 软件包名 -v -v -v --pct-touch 60 --pct-motion 20 5000 >日志文件
(3)--pct-trackball 百分比:轨迹事件
(4)--pct-nav 百分比:上下左右方向键
(5)--pct-majornav 百分比:Home键,菜单键,返回键
(6)--pct-syskeys 百分比:声音键、锁屏键等系统键
6、monkey的调试选项
(1)--hprof:在/data/misc目录下会生成profiling报告,该报告文件容量较大,小心使用
(2)--ignore-crashes:忽略崩溃。monkey执行过程中,遇到崩溃,不停止,继续执行下去
(3)--ignore-timeouts:忽略超时错误(ANR)。monkey执行过程中,遇到ANR,不停止,继续执行下去
(4)--ignore-security-exceptions:忽略许可错误。monkey执行过程中,遇到许可错误,不停止,继续执行下去
(5)--kill-process-after-error:程序出错后结束进程。
ADB用法大全:
点开链接访问具体内容:http://www.wanandroid.com/blog/show/2310Python
字典拆包/捷报
在Python中,当你在函数调用时,在字典前加上**(双星号),这被称为“解包”(unpacking)字典。这种语法允许你将字典的键值对作为关键字参数传递给函数。这意味着字典的键会被视为函数参数的名字,而对应的值则会被视为这些参数的值。
这种技术特别有用,当你有一个函数,它接受多个关键字参数,而你希望从一个字典中动态地传递这些参数时。
下面是一个简单的例子来说明这一点:
def greet(first_name, last_name, greeting="Hello"):
print(f"{greeting}, {first_name} {last_name}!")
# 创建一个包含参数的字典
person = {"first_name": "John", "last_name": "Doe"}
# 使用**解包字典作为关键字参数
greet(**person) # 输出: Hello, John Doe!
# 如果你还想传递额外的关键字参数,可以这样做
greet(**person, greeting="Hi") # 输出: Hi, John Doe!
在这个例子中,greet函数接受三个参数:first_name、last_name和一个可选的greeting。通过**person,我们将person字典解包为关键字参数,并传递给greet函数。如果字典中的键与函数参数名匹配,则对应的值会被用作参数的值。此外,我们还可以通过在函数调用时直接添加额外的关键字参数来覆盖字典中的值,如greet(**person, greeting="Hi")所示。
这种技术使得函数调用更加灵活和动态,特别是在处理不确定数量的参数时。Json和字典的区别?
python中,json和dict非常类似,都是key-value的形式,而且json、dict也可以非常方便的通过dumps、loads互转。既然都是key-value格式,为啥还需要进行格式转换?
json:是一种数据格式,是纯字符串。可以被解析成Python的dict或者其他形式。
dict:是一个完整的数据结构,是对Hash Table这一数据结构的一种实现,是一套从存储到提取都封装好了的方案。它使用内置的哈希函数来规划key对应value的存储位置,从而获得O(1)的数据读取速度。
json和dict对比
- json的key只能是字符串,python的dict可以是任何可hash对象(hashtable type);
- json的key可以是有序、重复的;dict的key不可以重复。
- json的value只能是字符串、浮点数、布尔值或者null,或者它们构成的数组或者对象。
- json任意key存在默认值undefined,dict默认没有默认值;
- json访问方式可以是[],也可以是.,遍历方式分in、of;dict的value仅可以下标访问。
- json的字符串强制双引号,dict字符串可以单引号、双引号;
- dict可以嵌套tuple,json里只有数组。
- json:true、false、null
- python:True、False、None
- json中文必须是unicode编码,如"\u6211".
- json的类型是字符串,字典的类型是字典。
hashtable
一个对象当其声明周期内的hash值不发生改变,而且可以跟其他对象进行比较时,这个对象就是hashtable的。
1、python中的基本类型都是Hashtable,如str、bytes、数字类型、tuple等;
2、用户自定义的类型默认都是hashtable,因为它们的hash值就是id()值;
3、frozenset始终都是hashtable的,因为它们所有的项目都是被定义成hashtable的;
4、只有当tuple内的所有项都是hashtable的时候,tuple才是hashtable;
Python3 中有六个标准的数据类型:
- Number(数字)
- String(字符串)
- List(列表)
- Tuple(元组)
- Set(集合)
- Dictionary(字典)
可变类型和不可变类型:
- 不可变数据(3 个):Number(数字)、String(字符串)、Tuple(元组);
- 可变数据(3 个):List(列表)、Dictionary(字典)、Set(集合)。
不可变数据类型,不允许变量的值发生变化
如果改变了变量的值,相当于是新建了一个对象,
而对于相同的值的对象,在内存中则只有一个对象,
内部会有一个引用计数来记录有多少个变量引用这个对象;
可变数据类型,允许变量的值发生变化,
即如果对变量进行append、+=等这种操作后,
只是改变了变量的值,而不会新建一个对象,
变量引用的对象的地址也不会变化,不过对于相同的值的不同对象,
在内存中则会存在不同的对象,即每个对象都有自己的地址,
相当于内存中对于同值的对象保存了多份,这里不存在引用计数,是实实在在的对象。
说一说你所知道的 Python 数据结构有哪些。
列表,字典,元祖,
说一下深拷贝和浅拷贝
浅拷贝,相当于只考虑父辈,不考虑其内部存在的子辈。
最外层a的地址发生改变,但内部的x和y引用的还是老的地址。
深拷贝,相当于复制了一个新的,跟以前的没关系。
最外层a和内部可变对象的地址发生改变,但内部不可变对象地址还是老的。Python 中列表和元组的区别是什么?元组是不是真的不可变?
列表和元组之间的区别是数组内容是可以被修改的而元组内容是只读的
元组与列表相互转换,使用函数list()将元组转化为列表,使用函数tuple()将列表转化为元组什么是生成器和迭代器?它们之间有什么区别?
什么是生成器?生成器只有在调用时才会生成相应的数据只记录当前位置,只有一个__next__()方法 ---->(i*i for i in range(10)) ==生成器
可以作用于for 循环的对象统称为可迭代对象(Iterable)
可以被__next__()函数调用并不断返回下一个值的对象称为迭代器:Iterator。
使用isinstance()判断一个对象是否为迭代器:Iterator。python 生成器和迭代器_python迭代器和生成器_m0_51736952的博客-CSDN博客
什么是闭包?装饰器又是什么?
闭包,又称闭包函数或者闭合函数,其实和前面讲的嵌套函数类似,
不同之处在于,闭包中外部函数返回的不是一个具体的值,
而是一个函数。一般情况下,返回的函数会赋值给一个变量,
这个变量可以在后面被继续执行调用。装饰器有什么作用?你用过装饰器吗?请写一个装饰器的例子。
装饰器本质上是一个Python函数(其实就是闭包)
它可以让其他函数在不需要做任何代码变动的前提下增加额外功能
装饰器的返回值也是一个函数对象。
装饰器用于有以下场景,比如:插入日志、性能测试、事务处理、缓存、权限校验等场景。说一下什么是匿名函数,用匿名函数有什么好处?
lambda 表达式,又称匿名函数
常用来表示内部仅包含 1 行表达式的函数。
如果一个函数的函数体仅有 1 行表达式,则该函数就可以用 lambda 表达式来代替。回调函数
回调函数就是一个被作为参数传递的函数。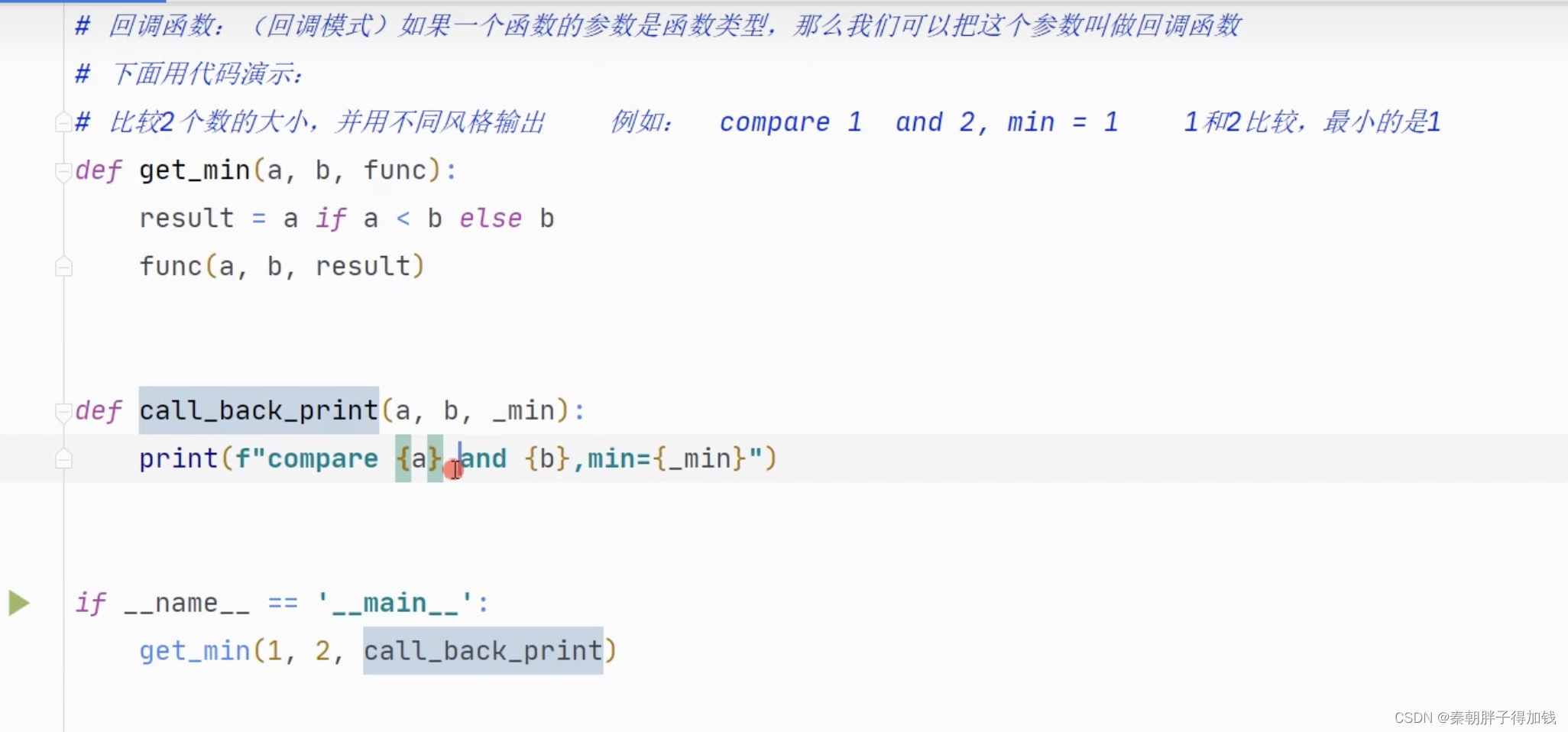
如何提高 Python 的运行效率吗?
1、多进程并行编程
对于CPU密集型的程序,可以使用multiProcessing的Process,Pool等封装好的类,通过多进程的方式实现并行计算。但是因为进程中的通信成本比较大,对于进程之间需要大量数据交互的程序效率未必有大的提高。
2、多线程并行编程
对于IO密集型的程序,multiprocessing.dummy模块使用multiprocessing的接口封装threading,使得多线程编程也变得非常轻松。
3、优化算法时间
算法的时间复杂度对程序的执行效率影响最大,在Python中可以通过选择合适的数据结构来优化时间复杂度,如list和set查找某一个元素的时间复杂度分别是O(n)和O(1)。不同的场景有不同的优化方式,总得来说,一般有分治,分支界限,贪心,动态规划等思想。
4、针对循环的优化
每种编程语言都会强调需要优化循环。当使用Python的时候,你可以依靠大量的技巧使得循环运行得更快。然而,开发者经常漏掉的一个方法是:避免在一个循环中使用点操作。优化循环的关键,是要减少Python在循环内部执行的工作量,因为Python原生的解释器在那种情况下,真的会减缓执行的速度。
5、函数选择
在循环的时候使用xrange而不是range;使用xrange可以节省大量的系统内存,因为xrange()在序列中每次调用只产生一个整数元素。而range()将直接返回完整的元素列表,用于循环时会有不必要的开销。递归调用

接口自动化
接口自动化使用的测试框架是什么?
测试框架:python+unittest+requests+ddt+openpyxl+pymysql+logging
测试框架:python:入门简单,语法简洁
unittest :定义一个测试用例类,具体的方法来维护测试用例的生命周期,测试场景行为,测试用例 前置场景,行为,期望结果,实际结果,断言方法,Setup teardown方法
requests:接口调用 ,支持http请求的库,API 简洁,提供不同的http请求方法,支持session,cookies,
ddt :数据驱动,ddt 类装饰器,data 测试方法装饰器 unpack解包可迭代的数据类型<br><br>普通用户,数据库,配置文件---(基础数据)
openpyxl: 数据管理 excel管理 数据,使用openpyxl模块来进行excel数据的读和写(excle,csv, json, yaml, txt都可以管理测试数据)
pymysql:数据库交互,数据校验<br><br> eval,json:数据格式的转换 Eval将python支持的格式转换成对应的格式
logging:日志处理, 统一日志输出格式,渠道,级别,执行结果的记录,便于定位问题
jenkins:持续集成
不可逆的操作,如何处理,比如删除一个订单这种接口如何测试?
使用新建订单接口造数据,不建议直接使用数据库造数据
如何连接数据库操作?
首先导入模块(提前pip安装) import pymysql
打开数据库连接 db = pymysql.connect("localhost", "username", "psw", "db_name")
创建一个游标对象 cursor = db.cursor()
sql查询语句 sql = "select * from emp"
执行sql语句 cursor.execute(sql)
获取所有记录列表 cursor.fetchall()
然后for循环遍历
关闭数据库连接 db.close()
依赖第三方的接口如何处理
这个需要自己去搭建一个mock服务,模拟接口返回数据,参考【python笔记25-mock-server之moco】(python笔记25-mock-server之moco - 上海-悠悠 - 博客园)
moco是一个开源的框架,在github上可以下载到https://github.com/dreamhead/moco
moco服务搭建需要自己能够熟练掌握,面试会问你具体如何搭建 ,如何模拟返回的数据,是用的什么格式,如何请求的
测试数据存放?
1.对于账号密码,这种管全局的参数,可以用命令行参数,单独抽出来,写的配置文件里(如ini)
2.对于一些一次性消耗的数据,比如注册,每次注册不一样的数,可以用随机函数生成
3.对于一个接口有多组测试的参数,可以参数化,数据放yaml,text,json,excel都可以
4.对于可以反复使用的数据,比如订单的各种状态需要造数据的情况,可以放到数据库,每次数据初始化,用完后再清理
5.对于邮箱配置的一些参数,可以用ini配置文件
6.对于全部是独立的接口项目,可以用数据驱动方式,用excel/csv管理测试的接口数据
7.对于少量的静态数据,比如一个接口的测试数据,也就2-3组,可以写到py脚本的开头,十年八年都不会变更的
什么是数据驱动,如何参数化?
参数化和数据驱动的概念这个肯定要知道的,参数化的思想是代码用例写好了后,不需要改代码,只需维护测试数据就可以了,并且根据不同的测试数据生成多个用例
openpyxl模块操作excel及结合ddt实现数据驱动
GUI自动化
设计模式
- PO模式
- 公用元素使用方法封装,等待,点击,切换iframe,下滑列表,截图,日志
- 页面元素定位语句
- 页面操作步骤
- 用例层,校验assert
- 日志,报告,截图
定位失败原因
| 原因 | 解决方法 |
| 没有打开正确的网址 | 填写正确的网址 |
| 定位器选择错误 | 选择合适的定位器 |
| 定位表达式错误 | 简单粗暴:F12 copy或手写定位调试 |
| 元素嵌套在iframe中 | 1,切换到iframe中:driver.switch_to.frame(’ iframe的id或name值 ');2,再进行元素定位 元素在新窗口中 1,获取打开的多个窗口句柄:handles = driver.window_handles;2,切换到新窗口中: driver.switch_to.window(handles[-1]) |
| 页面元素没有及时加载 | 1,加等待,不要加的太少,加10s,如果10秒还找不到说明不是因为页面加载导致的元素找不到;2,确定是页面元素没有及时加载原因后,可以使用以下三种等待方式,详见1.2 页面元素不可见或不可点击 1,使用JavaScript实现元素定位和动作执行;2,使用鼠标事件ActionChains来操作;3,如果是被伪元素遮挡了原本的元素,可以直接定位到伪元素上进行点击操作 。详见1.3 |
| 页面元素是动态的 | 1.根据其他静态属性定位;2.根据元素属性值模糊匹配定位。 详见1.4 |
| 脚本流程与实际不符 | 调整脚本以符合实际业务流程 |
如何处理重定向
当我们遇到这种重定向,我们应该怎么处理?
# request源码中
param allow_redirects: (optional) Boolean. Enable/disable GET/OPTIONS/POST/PUT/PATCH/DELETE/HEAD redirection. Defaults to ``True``.
:type allow_redirects: bool
发现requests中默认是True,是允许重定向的。
# coding:utf-8
import requests
url = 'http://github.com'
# 重定向为False
r = requests.get(url,allow_redirects=False)
print(r.status_code)
print(r.url)
代码结果:
301
http://github.com/
在默认开启的状态下,我们如何知道请求过程中有没有发现重定向呢?
requests返回中history可以帮我们解决
# coding:utf-8
import requests
url = 'http://github.com'
# 重定向为True
r = requests.get(url,allow_redirects=True)
print(r.status_code)
print(r.history)
代码结果:
200
[<Response [301]>]
发现如果我们允许重定向返回的状态码为200,通过查看历史请求状态码,发现中间请求过301
接口测试
一、你们公司的接口测试流程是怎样的?
接口测试是在对外项目做的,主要有模板中心接口,设计页接口,SDK等。
(一)为什么开展接口测试?
- 测试左移,前后端分离,接口出的早,测试介入越早,就越能在项目早期发现问题,其修复问题的成本越低,同时也提升工作效率。
- 安全性,现在绕过前端很容易,所以对于接口的安全性很重要,所以接口也要做一层校验。
- 非常快速,UI自动化执行一个测试用例10S左右、接口测试用例执行的话,需要的时间是毫秒级的。
- 主要进行可用性测试,安全性还有性能测试
(二)接口测试步骤
- 从开发那里拿到最终API接口文档
- 了解接口业务,包括接口地址、请求方式,入参、出参,token鉴权,返回格式等信息
- 设计接口测试用例
- 调试
- 执行
- 回归
- 产出结果文档
然后使用Postman或Jmeter工具执行接口测试,
二、接口测试如何设计测试用例?
接口测试一般考虑入参形式的变化和接口的业务逻辑,一般设计接口测试用例采用等价类、边界值、场景法居多!
接口测试设计测试用例的思路
1)接口业务逻辑测试?(正例)
接口逻辑测试是指根据业务逻辑、输入参数、输出值的描述,对正常输入情况下所得的输出值
是否正确的测试,也就是测试对外提供的接口服务是否正常工作。
2)模块接口测试?(反例)
模块接口测试是为了保证数据的安全及程序在异常情况下的逻辑的正确性而进行的测试。
模块接口测试的主要包括以下几个方面:
• 鉴权码token异常(鉴权码为空<没有鉴权码>,错误的鉴权码,过期的鉴权码)。
• 其他参数异常。
3)错误码异常覆盖。
4)接口测试其他的关注点
- 接口有翻页时,页码与页数的异常值测试
- 数据库的增删改查,比如一个post接口操作完成后,通过列表页接口看下新的数据是否和刚才的post一致
- 接口返回的图片地址能否打开,图片尺寸是否符合需求
- 当输出参数有联动性时,需要校验返回两参数的实际结果是否都符合需求。
- 所有列表页接口必须考虑排序值
- 所有功能都要考虑兼容旧版本
三、接口测试遇到的问题,如何确认接口是否有问题?
其实我们做接口的时候也碰到了蛮多的问题,都是自己独立解决的,比如返回值乱码(修改jmeter的配置文件为UTF-8编码方式),比如需要登录后才能取得token鉴权码并且这个鉴权码在下面的请求中需要用到(使用正则表达式提取器提取token的值等
- 首先检查接口地址,参数,头,请求体是否正确
- 核对相应内容格式是否和接口文档一致
- 检查数据库数据是否存储和修改正确
四、接口测试执行中比对数据库吗?
肯定,因为接口返回值的数据来源于数据库,接口对数据的操作还要进行深层次的数据库检查!
五、接口测试中有哪些要注意的测试点?
- 接口中返回了图片地址,要手工去进行图片的测试(大小、内容)
- 接口完成查询功能的时候,数据返回的排序显示
- 接口测试的时候,关注参数的默认值、必填项
六、HTTP和HTTPS?
- http80端口,https是443端口
- http是明文,https是加密传输到
- https是http+ssl协议 端口443 面向安全的超文本传输协议,比http安全;
- 通过ca证书验证身份
- 签名发送和接收要保证一致
七、请简述一下cookie、session以及token的区别?
- cookie数据存放在客户的浏览器上,session数据放在服务器上。
- cookie不安全,可以分析存放在本地的cookie并进行cookie欺骗,考虑到安全应当使用session。
- session会在一定时间内保存在服务器上。当访问增多,会比较占用你服务器的性能,考虑到减轻服务器性能方面应当使用cookie。
- 单个cookie保存的数据不能超过4K,很多浏览器都限制一个站点保存cookie的数量。
- 可以将登录信息等重要信息存放为session;其他信息需要保存,可以放在cookie。
各浏览器对cookie的数量限制
- IE50个
- Firefox50个
- Chrome150个
- Safari无限制
八、get和post请求的区别?
- 传送方式:get通过地址栏传输,post通过报文传输;
- 传送长度:get参数有长度限制(受限于url长度,浏览器限制),而post无限制;
- GET产生一个TCP数据包(对于GET方式的请求,浏览器会把http header和data一并发送出去,服务器响应200返回数据),POST产生两个TCP数据包(对于POST,浏览器先发送header,服务器响应100 continue,浏览器再发送data,服务器响应200 ok返回数据)
- 请求参数:get请求参数会被完整保留在浏览历史记录里,而post中的参数不会被保留;get请求参数一般是在url,post是在请求体
- 优势:在做数据查询时,建议用GET方式;而在做数据添加、修改或删除时,建议用post方式;
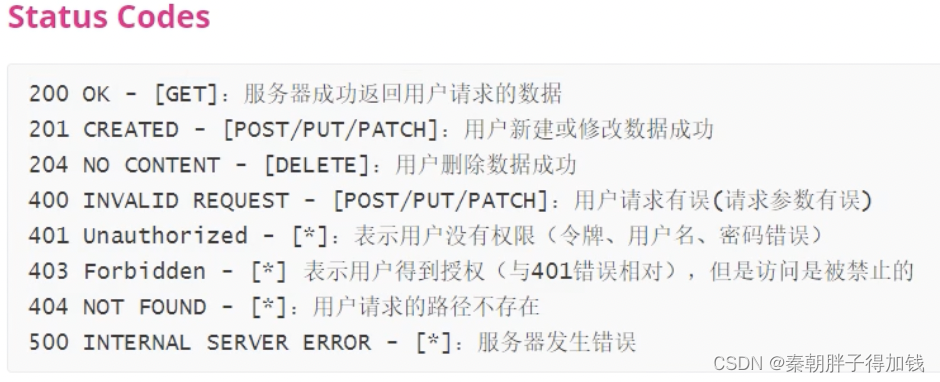
九、响应状态码有哪些?
- 1xx:指示信息–表示请求已接受,继续处理中
- 2xx:成功–表示请求已被成功接收、理解、接受
- 3xx:重定向–要完成请求必须进行更进一步的操作
- 4xx:客户端错误–请求有语法错误或请求无法实现
- 5xx:服务器端错误–服务器未能实现合法的请求
十、什么是DNS?
DNS 是域名系统 (Domain Name System),DNS是用来做域名解析的,它会在你上网输入网址后,把它转换成IP,然后去访问对方服务器;没有它,你想上百度就要记住百度的IP,但有了DNS的处理,你只需要记住对应网站的域名,即网址就可以了。
十一、post请求的四种参数形式是什么?
multipart/form-data
它会将表单的数据处理为一条消息,以标签为单元,用分隔符分开。既可以上传键值对,也可以上传文件。当上传的字段是文件时,会有Content-Type来说明文件类型;content-disposition,用来说明字段的一些信息;
由于有boundary隔离,所以multipart/form-data既可以上传文件,也可以上传键值对,它采用了键值对的方式,所以可以上传多个文件。
application/x-www-form-urlencoded
会将表单内的数据转换为键值对,比如,name=java&age = 23
application/json
设置 header 中Content-type,就告诉服务端数据以 Json 字符串的形式存在,相应的就用 Json 的方法解码数据即可。
text/xml
十二、HTTP的无状态
每次请求都是独立的,第二次无法和第一次相互关联起来
有状态是带有cookie,建立了链接
十三、TCP的三次握手
- 你好
- 收到,你也好
- 我也收到了
















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











