









CIFAR图片分类实现
数据获取
这里数据获取依旧使用torchvision,后面会尝试做一点自己的数据集。这里关注一下归一化这个问题,在没有使用BN的情况下,我们通常会对数据进行归一化或者标准化,好处我大概总结了一下:
- 计算机大数吞小数的情况,也就是数值方面的问题
- 在训练中,针对激活函数的非线性性,在区间限制内才有比较好的非线性性。
- 梯度的数量级可能变化非常大,同时可能会存在数值问题
- 权值太大,学习率就必须非常小,也会引发数值问题
- 收敛会更快
关于归一化的一些理解:https://blog.csdn.net/program_developer/article/details/78637711。
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5)),#每个channel,mean,std=0.5
# transforms.CenterCrop
] #3个通道的平均值和方差都取0.5
)
#训练数据集
trainset =torchvision.datasets.CIFAR10(
root=data_root,
train=True,
download=False,
transform=transform
)
trainloader = Data.DataLoader(
dataset=trainset,
batch_size=BATCH_SIZE,
shuffle=True,
num_workers=4
)
#测试数据集
testset=torchvision.datasets.CIFAR10(
root=data_root,
train=False,
transform=transform
)
testloader=Data.DataLoader(
dataset=testset,
batch_size=BATCH_SIZE,
shuffle=False,
num_workers=4
)
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
数据分析
这里对训练集进行一些基本的分析,主要包括类别分布,然后图片的查看等。
def data_analyze(dataset):
#数据分布
fig1=plt.figure()
targets=dataset.targets
plt.hist(targets,bins=10,rwidth=0.8)
plt.title('dataset histogram')
plt.xlabel('class_id')
plt.ylabel('class_num')
#图片抽样查看
fig2=plt.figure()
images=dataset.data[:20]
for i in np.arange(1,21):
plt.subplot(5,4,i)
plt.text(10,10,'{}'.format(targets[i-1]),fontsize=20,color='g')
plt.imshow(images[i-1])
fig2.suptitle('Images')
plt.show()
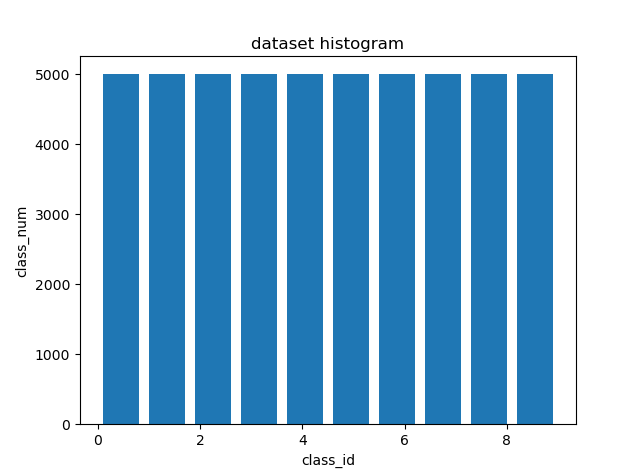
训练集的分布:10个类别均有5000个样本:'plane', 'car', 'bird', 'cat','deer', 'dog', 'frog', 'horse', 'ship', 'truck'
图片的信息,都是(28,28,3)的图片,同时在dataset直接读出来的也是numpy格式的(28,28,,3)的图片。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6OgQiJjD-1592795363396)(https://raw.githubusercontent.com/UESTC-Liuxin/pytorch/master/md_img/Exp12_2.png)]
网络构建
这里的网络的话,是自己写的小网络,当然,实验证明,差得一批。。。。
class CifarNet(nn.Module):
def __init__(self):
super(CifarNet,self).__init__()
self.Conv=nn.Sequential(
nn.Conv2d(
in_channels=3,
out_channels=6,
kernel_size=5,
padding=2
),#if stride=1 , padding=(kernel_size-1)/2
nn.MaxPool2d(2,2),
nn.ReLU(),
nn.Conv2d(
in_channels=6,
out_channels=16,
kernel_size=5
),
nn.MaxPool2d(2,2),
nn.ReLU()
)
self.Fc=nn.Sequential(
nn.Linear(16*6*6,20),
nn.ReLU(),
nn.Linear(20,100),
nn.ReLU(),
nn.Linear(100,10)
)
def forward(self, x):
x=self.Conv(x)
x=x.view(-1,16*6*6)
x=self.Fc(x)
return x
训练与可视化
viz = Visdom(server='http://[::1]', port=8097,env='Cifar Loss')
# viz.line([0.], [0.], win='train_loss', opts=dict(title='train loss'))
# viz.line([0.], [0.], win='test_acc', opts=dict(title='test acc'))
if __name__ == '__main__':
net = CifarNet()
writer = SummaryWriter( comment="myresnet")
with writer:
writer.add_graph(net, (torch.rand(1,3,32, 32),))
optimizer = torch.optim.SGD(net.parameters(), lr=LR,momentum=0.9)
loss_func = nn.CrossEntropyLoss()
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
net.to(device)
# 随机获取训练图片
for epoch in range(EPOCH):
Loss=[]
train_win='train{}_loss'.format(epoch)
viz.line([0.], [0.], win=train_win, opts=dict(title=train_win))
for step,(batch_x,batch_y) in enumerate(trainloader):
batch_x,batch_y=batch_x.to(device),batch_y.to(device)
print(batch_x.size())
out=net(batch_x)
#计算损失时,直接用非one-hot的展开与准确标签做计算,标签也不是one-hot的,就直接是一个数
loss=loss_func(out,batch_y)
optimizer.zero_grad()
loss.backward()
Loss.append(loss.data)
optimizer.step()
viz.line([loss.item()], [step], win=train_win, update='append')
if step%500==0:
print('epoch:', epoch, 'step:', step, 'loss:{:.3f}'.format(loss.data))
writer.add_scalar('Train', loss, step)
test_win = 'test{}_acc'.format(epoch)
viz.line([0.], [0.], win=test_win, opts=dict(title=test_win))
total=0
correct=0
#TEST
for step1, (batch_x, batch_y) in enumerate(testloader):
batch_x, batch_y = batch_x.to(device), batch_y.to(device)
pred_x=net(batch_x)
_, predicted = torch.max(pred_x.data, 1)
total += batch_y.size(0)
correct += (predicted == batch_y).sum().item()
acc=correct/total
viz.line([acc], [step1], win=test_win, update='append')
writer.add_scalar('Test', acc, step1)
# data_analyze(trainset)
最后效果不怎么好,准确率一直在40%左右,于是我决定在后面换成残差网络,看来普通网络还是不大行。















 216
216











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









