






文章目录
主要覆盖的题型
递归、分治、单调栈、并查集、滑动窗口、前缀和、二分查找、BFS广搜、DFS深搜
刷题指南
一些常用程序写法
python实现二叉树的遍历以及基本操作
迷宫问题
最长公共子序列
波兰表达式
数独
单调栈
并查集
一个递归的例子——斐波那契数列
1. 简介
斐波那契数列(Fibonacci sequence),又称黄金分割数列
2. 通项公式
a n = 1 5 [ ( 1 + 5 2 ) n − ( 1 − 5 2 ) n ] a_n=\frac{1}{\sqrt{5}}[(\frac{1+\sqrt{5}}{2})^n-(\frac{1-\sqrt{5}}{2})^n] an=51[(21+5)n−(21−5)n]
(如上,又称为“比内公式”,是用无理数表示有理数的一个范例。)
注:此时
a
1
=
1
,
a
2
=
1
,
a
n
=
a
n
−
1
+
a
n
−
1
,
(
n
≥
2
,
n
∈
N
∗
)
a_1=1, a_2=1, a_n=a_{n-1}+a_{n-1}, (n ≥ 2, n ∈ N^*)
a1=1,a2=1,an=an−1+an−1,(n≥2,n∈N∗)
3. 与黄金分割的关系
当趋向于无穷大时,前一项与后一项的比值越来越逼近黄金分割0.618
4. 应用
-
黄金分割
随着数列项数的增加,前一项与后一项之比越来越逼近黄金分割的数值 0.6180339887 …
-
杨辉三角
将杨辉三角左对齐,成下图所示排列,将同一斜行的数加起来,即得一数列 1、1、2、3、5、8、……

-
矩形面积

a 1 2 + a 2 2 + ⋅ ⋅ ⋅ + a n 2 = a n ⋅ a n + 1 a_1^2 + a_2^2 + ··· + a_n^2 = a_n·a_{n+1} a12+a22+⋅⋅⋅+an2=an⋅an+1
运算符
- 除和整除
print(3 / 2, 3 // 2) # 1.5 1
数字
- 复数(complex)
可以用a + bj,或者complex(a,b)表示,复数的实部a和虚部b都是浮点型
list 列表
- 删除指定位置元素
del list1[2]
- 组合
| Python 表达式 | 结果 | 描述 |
|---|---|---|
| [1, 2, 3] + [4, 5, 6] | [1, 2, 3, 4, 5, 6] | 组合 |
- list 包含的方法
| 方法 | 描述 |
|---|---|
| list.count(obj) | 统计某个元素在列表中出现的次数 |
| list.extend(seq) | 在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表) |
| list.index(obj) | 从列表中找出某个值第一个匹配项的索引位置 |
| list.insert(index, obj) | 将对象插入列表 |
| list.pop([index=-1]) | 移除列表中的一个元素(默认最后一个元素),并且返回该元素的值 |
| list.remove(obj) | 移除列表中某个值的第一个匹配项 |
| list.reverse() | 反向列表中元素 |
| list.sort(cmp=None, key=None, reverse=False) | 对原列表进行排序 |
- 间隔切片
list1[1:8:2] # 在[1, 8)以步长2进行截取
元组
| Python 表达式 | 结果 | 描述 |
|---|---|---|
| (1, 2, 3) + (4, 5, 6) | (1, 2, 3, 4, 5, 6) | 连接 |
| (‘Hi!’,) * 4 | (‘Hi!’, ‘Hi!’, ‘Hi!’, ‘Hi!’) | 复制 |
字典
- 删除元素、清空字典
del tinydict['Name'] # 删除键 'Name'
| 序号 | 函数及描述 |
|---|---|
| 1 | dict.clear() 删除字典内所有元素 |
| 2 | dict.copy() 返回一个字典的浅复制 |
| 3 | dict.fromkeys(seq, default_val) 创建一个新字典,以序列seq中元素做字典的键,val为字典所有键对应的初始值 |
| 4 | dict.get(key, default=None) 返回指定键的值,如果键不在字典中返回 default 设置的默认值 |
| 5 | key in dict 如果键在字典dict里返回true,否则返回false |
| 6 | dict.items() 以列表返回一个视图对象 |
| 7 | dict.keys() |
| 8 | dict.setdefault(key, default=None) 和get()类似, 但 如果 key 在 字典中,返回对应的值。如果不在字典中,则插入 key 及设置的默认值 default,并返回 default ,default 默认值为 None |
| 9 | dict.update(dict2) 把字典dict2的键/值对更新到dict里 |
| 10 | dict.values() 返回一个视图对象 |
| 11 | pop(key[,default]) 删除字典给定键 key 所对应的值,返回值为被删除的值。key值必须给出。 否则,返回default值。 |
| 12 | popitem() 返回并删除字典中的最后一对键和值。 |
集合
| 方法 | 描述 |
|---|---|
| add() | 为集合添加元素 |
| update() | 给集合添加元素 |
| pop() | 随机移除元素 |
| remove() | 移除指定元素 |
| discard() | 删除集合中指定的元素 该方法不同于 remove() 方法,因为 remove() 方法在移除一个不存在的元素时会发生错误,而 discard() 方法不会。 |
| clear() | 移除集合中的所有元素 |
| copy() | 拷贝一个集合 |
| difference() | 返回多个集合的差集 |
| difference_update() | 移除集合中的元素,该元素在指定的集合也存在。 |
| intersection() | 返回集合的交集 |
| intersection_update() | 返回集合的交集。 |
| isdisjoint() | 判断两个集合是否包含相同的元素,如果没有返回 True,否则返回 False。 |
| issubset() | 判断指定集合是否为该方法参数集合的子集。 |
| issuperset() | 判断该方法的参数集合是否为指定集合的子集 |
| symmetric_difference() | 返回两个集合中不重复的元素集合。 |
| symmetric_difference_update() | 移除当前集合中在另外一个指定集合相同的元素,并将另外一个指定集合中不同的元素插入到当前集合中。 |
| union() | 返回两个集合的并集 |
字符串
- 重复
x = 'abc' * 2
| 序号 | 方法及描述 |
|---|---|
| 1 | capitalize() 将字符串的第一个字符转换为大写 |
| 2 | center(width, fillchar) 返回一个指定的宽度 width 居中的字符串,fillchar 为填充的字符,默认为空格。 |
| 3 | count(str, beg= 0,end=len(string)) 返回 str 在 string 里面出现的次数,如果 beg 或者 end 指定则返回指定范围内 str 出现的次数 |
| 4 | bytes.decode(encoding=“utf-8”, errors=“strict”) Python3 中没有 decode 方法,但我们可以使用 bytes 对象的 decode() 方法来解码给定的 bytes 对象,这个 bytes 对象可以由 str.encode() 来编码返回。 |
| 5 | encode(encoding=‘UTF-8’,errors=‘strict’) 以 encoding 指定的编码格式编码字符串,如果出错默认报一个ValueError 的异常,除非 errors 指定的是’ignore’或者’replace’ |
| 6 | endswith(suffix, beg=0, end=len(string)) 检查字符串是否以 obj 结束,如果beg 或者 end 指定则检查指定的范围内是否以 obj 结束,如果是,返回 True,否则返回 False. |
| 7 | expandtabs(tabsize=8) 把字符串 string 中的 tab 符号转为空格,tab 符号默认的空格数是 8 。 |
| 8 | find(str, beg=0, end=len(string)) 检测 str 是否包含在字符串中,如果指定范围 beg 和 end ,则检查是否包含在指定范围内,如果包含返回开始的索引值,否则返回-1 |
| 9 | index(str, beg=0, end=len(string)) 跟find()方法一样,只不过如果str不在字符串中会报一个异常。 |
| 10 | isalnum() 如果字符串至少有一个字符并且所有字符都是字母或数字则返 回 True,否则返回 False |
| 11 | isalpha() 如果字符串至少有一个字符并且所有字符都是字母或中文字则返回 True, 否则返回 False |
| 12 | isdigit() 如果字符串只包含数字则返回 True 否则返回 False… |
| 13 | islower() 如果字符串中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是小写,则返回 True,否则返回 False |
| 14 | isnumeric() 如果字符串中只包含数字字符,则返回 True,否则返回 False |
| 15 | isspace() 如果字符串中只包含空白,则返回 True,否则返回 False. |
| 16 | istitle() 如果字符串是标题化的(见 title())则返回 True,否则返回 False |
| 17 | isupper() 如果字符串中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是大写,则返回 True,否则返回 False |
| 18 | join(seq) 以指定字符串作为分隔符,将 seq 中所有的元素(的字符串表示)合并为一个新的字符串 |
| 19 | len(string) 返回字符串长度 |
| 20 | ljust(width[, fillchar]) 返回一个原字符串左对齐,并使用 fillchar 填充至长度 width 的新字符串,fillchar 默认为空格。 |
| 21 | lower() 转换字符串中所有大写字符为小写. |
| 22 | lstrip() 截掉字符串左边的空格或指定字符。 |
| 23 | maketrans() 创建字符映射的转换表,对于接受两个参数的最简单的调用方式,第一个参数是字符串,表示需要转换的字符,第二个参数也是字符串表示转换的目标。 |
| 24 | max(str) 返回字符串 str 中最大的字母。 |
| 25 | min(str) 返回字符串 str 中最小的字母。 |
| 26 | replace(old, new [, max]) 把 将字符串中的 old 替换成 new,如果 max 指定,则替换不超过 max 次。 |
| 27 | rfind(str, beg=0,end=len(string)) 类似于 find()函数,不过是从右边开始查找. |
| 28 | rindex( str, beg=0, end=len(string)) 类似于 index(),不过是从右边开始. |
| 29 | rjust(width,[, fillchar]) 返回一个原字符串右对齐,并使用fillchar(默认空格)填充至长度 width 的新字符串 |
| 30 | rstrip() 删除字符串末尾的空格或指定字符。 |
| 31 | split(str=“”, num=string.count(str)) 以 str 为分隔符截取字符串,如果 num 有指定值,则仅截取 num+1 个子字符串 |
| 32 | splitlines([keepends]) 按照行(‘\r’, ‘\r\n’, \n’)分隔,返回一个包含各行作为元素的列表,如果参数 keepends 为 False,不包含换行符,如果为 True,则保留换行符。 |
| 33 | startswith(substr, beg=0,end=len(string)) 检查字符串是否是以指定子字符串 substr 开头,是则返回 True,否则返回 False。如果beg 和 end 指定值,则在指定范围内检查。 |
| 34 | strip([chars]) 在字符串上执行 lstrip()和 rstrip() |
| 35 | swapcase() 将字符串中大写转换为小写,小写转换为大写 |
| 36 | title() 返回"标题化"的字符串,就是说所有单词都是以大写开始,其余字母均为小写(见 istitle()) |
| 37 | translate(table, deletechars=“”) 根据 table 给出的表(包含 256 个字符)转换 string 的字符, 要过滤掉的字符放到 deletechars 参数中 |
| 38 | upper() 转换字符串中的小写字母为大写 |
| 39 | zfill (width) 返回长度为 width 的字符串,原字符串右对齐,前面填充0 |
| 40 | isdecimal() 检查字符串是否只包含十进制字符,如果是返回 true,否则返回 false。 |
- 注意
isdigit——数字
isnumeric——数字字符
isdecimal——十进制字符
Python 函数
不同进制数转换
- bin() 函数——将数字转化为二进制(字符串)
y = bin(10) # '0b1010'
- oct()——将一个整数转换成 8 进制(字符串)
y = oct(10) # '0o12'
- hex() 函数——将10进制整数转换成16进制(字符串)
y = hex(255) # '0xff'
- int()——将一个字符串或数字转换为整型
y = int('12',16) # 18 如果是带参数base的话,12要以字符串的形式进行输入,12 为 16进制
y = int('0xa',16) # 10
y = int('10',8) # 8
- 不同进制之间的转换

ASCII码与字符相互转换
- ord() 函数——返回字符的ASCII数值
y = ord('a') # 97
- chr() 函数——当前整数对应的 ASCII 字符
>>>chr(0x30) # 十六进制
'0'
>>> chr(97) # 十进制
'a'
>>> chr(8364)
'€'
排列组合
C 10 5 C_{10}^5 C105
from itertools import combinations
num_l = list(combinations(num_list, 5)) # C(10, 5)
或
class Solution:
def balance(self, candidates):
res = []
cur = []
self.back(candidates, 0, cur, res)
return min(res)
def back(self, candidates, start, cur, res):
if len(cur) == 5:
res.append(abs(sum(candidates) - sum(cur) - sum(cur)))
return
for i in candidates[start:]:
cur.append(i)
self.back(candidates, candidates.index(i) + 1, cur, res)
cur.pop()
print(Solution().balance([1, 2, 3, 4, 5, 6, 7, 8, 9, 10]))
A 10 5 A_{10}^5 A105
from itertools import permutations
# 组合,没有重复 (不放回抽样组合)
num_l = list(permutations(num_list, 5)) # A(10, 5)
# 组合,有重复 (放回抽样组合)
num_l = list(combinations_with_replacement(num_list, 5)) # A(10, 5)
正则表达式
import re
# re.match() 只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;而re.search匹配整个字符串,直到找到一个匹配
# re.fullmatch() 首尾都要匹配
searchObj = re.search("(.*) are (.*?) .*", "Cats are smarter than dogs", re.M | re.I)
if searchObj:
print("searchObj.group() : ", searchObj.group()) # Cats are smarter than dogs
print("searchObj.group(1) : ", searchObj.group(1)) # Cats
print("searchObj.group(2) : ", searchObj.group(2)) # smarter
print("searchObj.groups() : ", searchObj.groups()) # ('Cats', 'smarter')
print('searchObj.span() : ', searchObj.span()) # (0, 26)
else:
print("Nothing found!!") # return None
# 匹配项替换
num = re.sub('#.*$', "", "2004-959-559 # 这是一个国外电话号码") # 2004-959-559
| 模式 | 描述 |
|---|---|
| ^ | 匹配字符串的开头 |
| $ | 匹配字符串的末尾 |
| . | 匹配任意字符,除了换行符,当re.DOTALL标记被指定时,则可以匹配包括换行符的任意字符 |
| [amk] | 匹配 ‘a’,‘m’或’k’ |
| [^ abc] | 匹配除了a,b,c之外的字符 |
| * | ≥ 0 |
| + | ≥ 1 |
| abc? | 匹配ab,或abc |
| o{2} | 精确匹配2个o |
| o{2,} | 匹配 2 个前面表达式, 能匹配 "foooood"中的所有 o |
| o{2,4} | 匹配2~4个o |
| a | b | 匹配a或b |
| \w | 匹配字母数字及下划线 |
| \W | 匹配非字母数字及下划线 |
| \s | 匹配任意空白字符,等价于 [ \t\n\r\f]。 |
| \S | 匹配任意非空字符 |
| \d | 匹配任意数字,等价于 [0-9]. |
| \D | 匹配任意非数字 |
| [a-zA-Z0-9] | 匹配任何字母及数字 |
日期
import datetime
x = datetime.date(1992, 12, 25) # 1992-12-25
x = datetime.date.today() # 2022-05-18
x = datetime.date.fromtimestamp(1576244364) # 2019-12-13
x = datetime.date.today().year # 2022
x = datetime.time(11, 11, 11, 23424) # 11:11:11.023424
x = datetime.time(11, 11, 11, 23424).hour # 11
x = datetime.datetime(1992, 12, 25, 12, 23, 35) # 1992-12-25 12:23:35
x = datetime.datetime.now() # 2022-05-18 00:12:15.109031
t0 = datetime.datetime(year=2018, month=7, day=12, hour=7, minute=9, second=33)
t1 = datetime.datetime(year=2019, month=6, day=10, hour=5, minute=55, second=13)
x = t1 - t0 # 332 days, 22:45:40
x = datetime.datetime.now().strftime('%j') # 138 day, 从元旦算起
四舍五入
- round(num, n) 函数
print(round(3.1415926, 2)) # 3.14
print(round(3.1415926, 3)) # 3.142
文件结束
try:
dosomething()
except EOFError: # 文件结束判断
dosomething()
最长升序子序列
- 使用bisect模块——得到最长数字最小的最长升序子序列
import bisect
input_list = [2, 4, 3, 5, 7, 3, 9, 8]
sequence = []
for ele in input_list:
pos = bisect.bisect_left(sequence, ele) # 查找 ele 可以在列表 sequence 中插入的位置
if pos == len(sequence): # 如果发现插入新值的位置是在最右边,说明新元素是当前最大值,追加到列表后边
sequence.append(ele)
else: # 否则,说明 pos 位置的原有元素不比新值 ele 更大,将它替换
sequence[pos] = ele
print(sequence) # [2, 3, 5, 7, 8]
- 使用动态规划——得到最长升序子序列的长度
dp = [1] * n
for i in range(n):
for j in range(i):
if nums[j] < nums[i]:
dp[i] = max(dp[i], dp[j] + 1)
print(max(dp)) # 5
分数求解
import fractions
x = fractions.Fraction('8/11') # 8/11
y = x - fractions.Fraction(2 / 4) # 5/22
print(y.numerator) # 5
print(y.denominator) # 22
最大公约数和最小公倍数
import math
a, b = 5, 8
gcd = math.gcd(a, b) # 最大公约数: 1
lcm = a * b // x # 最小公倍数: 40
多重排序
y = sorted(x, key=lambda i: (-i[1], i[0]))
匹配替换
print(re.sub('(\d+)', '*\g<1>*', input()))
Python 基础
Python 基础语法
标识符
- 第一个字符必须是字母表中字母或下划线 _ 。
- 标识符的其他的部分由字母、数字和下划线组成。
- 标识符对大小写敏感
-
数字(Number)类型
整数、布尔型、浮点数和复数(a+bj) -
字符串(String)
- 使用三引号(‘’’ 或 “”")可以指定一个多行字符串。
- 反斜杠可以用来转义,使用 r 可以让反斜杠不发生转义。 如 r"this is a line with \n" 则 \n 会显示,并不是换行。
同一行显示多条语句
语句之间使用分号 ; 分割,以下是一个简单的实例:
import sys; x = 'runoob'; sys.stdout.write(x + '\n')
Python3 基本数据类型
每个变量在使用前都必须赋值,变量赋值以后该变量才会被创建。在 Python 中,变量就是变量,它没有类型,我们所说的"类型"是变量所指的内存中对象的类型
标准数据类型
- 不可变数据(3 个):Number(数字)、String(字符串)、Tuple(元组);
- 可变数据(3 个):List(列表)、Dictionary(字典)、Set(集合)。
isinstance 和 type 的区别在于
type()不会认为子类是一种父类类型,isinstance()会认为子类是一种父类类型
注意:Python3 中,bool 是 int 的子类,True 和 False 可以和数字相加, True=1、False=0 会返回 True,但可以通过 is 来判断类型。
>>> issubclass(bool, int)
True
>>> True==1
True
>>> False==0
True
>>> True+1
2
>>> False+1
1
>>> 1 is True
False
>>> 0 is False
False
>>>0 == False
True
元组
虽然tuple的元素不可改变,但它可以包含可变的对象,比如list列表。
数据类型转换
>>> n=81
>>> eval("n + 4")
85
- frozenset(s)
转换为不可变集合,参考Python frozenset() 函数的使用与作用
推导式
# 元组推导式
print(tuple(i for i in range(10))) # (0, 1, 2, 3, 4, 5, 6, 7, 8, 9)
运算符
海象运算符(python3.8)
if (a := len([1, 2, 3, 4, 5, 6])) > 5:
print(a) # 6
-
位运算符
& —— 与
| —— 或
~ —— 非
^ —— 异或
<< —— 左移
>> —— 右移 -
身份运算符
is 是判断两个标识符是不是引用自一个对象
x is y, 类似 id(x) == id(y), id() 函数用于获取对象内存地址 -
成员运算符
in 如果在指定的序列中找到值返回 True
数字
-
abs()和math.fabs()
abs() 是内置函数。 fabs() 函数在 math 模块中定义。
fabs() 函数只对浮点型跟整型数值有效。 abs() 还可以运用在复数中 -
math.log()
如math.log(math.e)返回1.0,math.log(100,10)返回2.0 -
math.modf(x)
返回小数与整数部分 -
random.choice(range(100))
从序列的元素中随机挑选一个元素 -
random.randrange(1, 100, 2)
从指定范围内,按指定基数递增的集合中获取一个随机数,基数默认值为 1 -
random.random()
随机生成一个[0, 1)的实数 -
random.seed(10)
设置随机数种子 -
random.shuffle (lst )
对序列随机排序 -
random.uniform(x, y)
随机生成下一个实数 -
math.hypot(x, y)
返回欧几里德范数 sqrt(x*x + y*y) -
数字常量
math.e和math.pi
end关键字
a, b = 0, 1
while b < 1000:
print(b, end=',')
a, b = b, a+b
# 1,1,2,3,5,8,13,21,34,55,89,144,233,377,610,987,
循环语句
while
如果 while 后面的条件语句为 false 时,则执行 else 的语句块
count = 0
while count < 5:
print (count, " 小于 5")
count = count + 1
else:
print (count, " 大于或等于 5")
for
for <variable> in <sequence>:
<statements> # 若有break, 直接跳出,不经过else
else: # 循环结束或条件为False时执行else
<statements>
迭代器与生成器
迭代器有两个基本的方法:iter() 和 next()。
字符串,列表或元组对象都可用于创建迭代器
- 迭代器
class Num:
def __init__(self):
self.x = 1
def __iter__(self): # 返回一个特殊的迭代器对象
return self
def __next__(self): # 返回当前迭代的一个值
if self.x <= 20:
x0 = self.x
self.x += 1
return x0
else:
raise StopIteration # 结束迭代
- 生成器
#!/usr/bin/python3
import sys
def fibonacci(n): # 生成器函数 - 斐波那契
a, b, counter = 0, 1, 0
while True:
if (counter > n):
return
yield a
a, b = b, a + b
counter += 1
f = fibonacci(10) # f 是一个迭代器,由生成器返回生成
while True:
try:
print (next(f), end=" ")
except StopIteration:
sys.exit()
# 0 1 1 2 3 5 8 13 21 34 55
函数
在 python 中,strings, tuples, 和 numbers 是不可更改的对象(不影响外部变量),而 list,dict 等则是可以修改的对象。
- 传不可变对象
def change(a):
print(id(a)) # 指向的是同一个对象
a=10
print(id(a)) # 一个新对象
- 传可变参数
def func(arg, *args, **kwargs):
print(arg)
print(args)
print(kwargs)
func(1, 2, 3, a=4, b=5)
- 匿名函数
lambda 函数拥有自己的命名空间,且不能访问自己参数列表之外或全局命名空间里的参数。
虽然 lambda 函数看起来只能写一行,却不等同于 C 或 C++ 的内联函数,后者的目的是调用小函数时不占用栈内存从而增加运行效率
x = lambda a : a + 10
print(x(5)) # 15
- python3.8 中的 / 和 *
def f(a, b, /, c, d, *, e, f): # / 之前必须为 位置参数, * 后面的必须为 关键字参数
print(a, b, c, d, e, f)
f(10, 20, 30, d=40, e=50, f=60) # 10 20 30 40 50 60
模块
- 搜索路径
Python的搜索路径,搜索路径是由一系列目录名组成的,Python解释器就依次从这些目录中去寻找所引入的模块,sys.path
每个模块有各自独立的符号表,在模块内部为所有的函数当作全局符号表来使用
被导入的模块的名称将被放入当前操作的模块的符号表中
- __name__属性
if __name__ == '__main__':
print('程序自身在运行')
else:
print('我来自另一模块')
-
dir()模块
内置的函数 dir() 可以找到模块内定义的所有名称 -
模块导入
注意当使用 from package import item 这种形式的时候,对应的 item 既可以是包里面的子模块(子包),或者包里面定义的其他名称,比如函数,类或者变量。
import item.subitem.subsubitem 这种导入形式,除了最后一项,都必须是包,而最后一项则可以是模块或者是包,但是不可以是类,函数或者变量的名字
错误和异常
- try 和 except
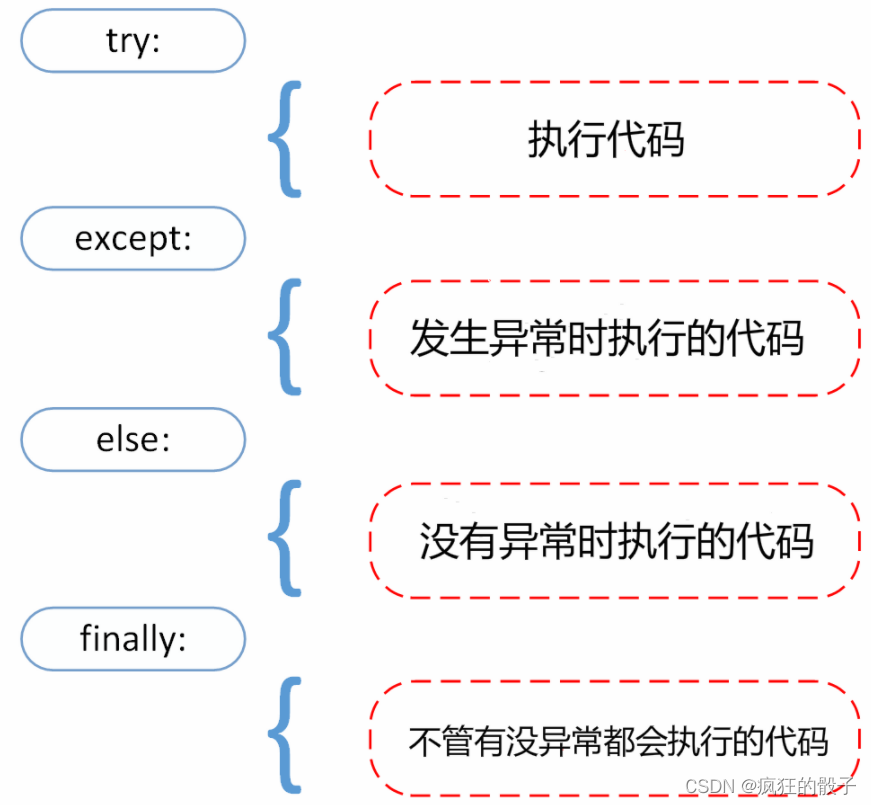
- raise
raise Exception('x 不能大于 5') # 必须是一个异常的实例或者是异常的类
class MyError(Exception):
def __init__(self, value):
self.value = value
def __str__(self):
return repr(self.value)
try:
raise MyError(2)
except MyError as e:
print('My exception occurred, value:', str(e)) # My exception occurred, value: 2
- assert
assert expression
# 等价于
if not expression:
raise AssertionError
面向对象
self代表类的实例,而非类
class Test:
def prt(self):
print(self)
print(self.__class__)
t = Test()
t.prt()
# 以上实例执行结果为:
# <__main__.Test instance at 0x100771878>
# __main__.Test
- 多重继承
若是父类中有相同的方法名,而在子类使用时未指定,python从左至右搜索 即方法在子类中未找到时,从左到右查找父类中是否包含方法
class DerivedClassName(Base1, Base2, Base3):
<statement-1>
- 运算符重装
class Vector:
def __init__(self, a, b):
self.a = a
self.b = b
def __str__(self):
return 'Vector (%d, %d)' % (self.a, self.b)
def __add__(self,other):
return Vector(self.a + other.a, self.b + other.b)
v1 = Vector(2,10)
v2 = Vector(5,-2)
print (v1 + v2) # Vector(7,8)
- __repr__() 方法是类的实例化对象用来做“自我介绍”的方法,直接打印实例化类对象时调用
命名空间
局部的命名空间去 -> 全局命名空间 -> 内置命名空间
命名空间的生命周期取决于对象的作用域,如果对象执行完成,则该命名空间的生命周期就结束。
因此,我们无法从外部命名空间访问内部命名空间的对象
- 作用域
- 在
局部(Local)找不到,便会去局部外的局部(Enclosing)找(例如闭包),再找不到就会去全局(Global)找,再者去内置(Built-in)中找 - Python 中只有
模块(module),类(class)以及函数(def、lambda)才会引入新的作用域,其它的代码块(如 if/elif/else/、try/except、for/while等)是不会引入新的作用域的,也就是说这些语句内定义的变量,外部也可以访问的
- global 和 nonlocal关键字
global修改全局作用域,nonlocal修改enclosing作用域
参考
菜鸟教程·Python 3 教程
10个数平均分两组,差值最小
Python frozenset() 函数的使用与作用
百度百科·斐波那契数列
















 972
972











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









