







 本文介绍了一个基于TensorFlow1.x的人脸表情识别项目,利用卷积神经网络在FER2013、JAFFE和CK+数据集上进行训练,达到高准确率。项目包括环境部署、数据准备、网络设计、模型训练和GUI界面,提供实时摄像头预测功能。
本文介绍了一个基于TensorFlow1.x的人脸表情识别项目,利用卷积神经网络在FER2013、JAFFE和CK+数据集上进行训练,达到高准确率。项目包括环境部署、数据准备、网络设计、模型训练和GUI界面,提供实时摄像头预测功能。
1. 简介
使用卷积神经网络构建整个系统,在尝试了Gabor、LBP等传统人脸特征提取方式基础上,深度模型效果显著。在FER2013、JAFFE和CK+三个表情识别数据集上进行模型评估。
2. 环境部署
基于Python3和Keras2(TensorFlow后端),具体依赖安装如下(推荐使用conda虚拟环境)。
cd FacialExpressionRecognition
conda create -n FER python=3.6 -y
conda activate FER
conda install cudatoolkit=10.1 -y
conda install cudnn=7.6.5 -y
pip install -r requirements.txt
如果你是Linux用户,直接执行根目录下的env.sh即可一键配置环境,执行命令为bash env.sh。
3. 数据准备
可网络自行下载公开数据集或自制数据集
4.网络设计
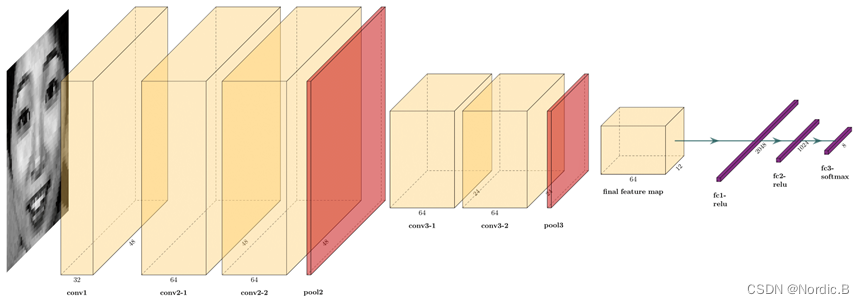
使用经典的卷积神经网络,模型的构建主要参考2018年CVPR几篇论文以及谷歌的Going Deeper设计如下网络结构,输入层后加入(1,1)卷积层增加非线性表示且模型层次较浅,参数较少(大量参数集中在全连接层)。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1219
1219

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











