







一 KNN简介
K最近邻(k-Nearest Neighbor,KNN)分类算法,该方法的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。你可以简单的理解为由那离自己最近的K个点来投票决定待分类数据归为哪一类。
KNN算法的过程为:
选择一种距离计算方式, 通过数据所有的特征计算新数据与已知类别数据集中的数据点的距离,按照距离递增次序进行排序,选取与当前距离最小的k个点,对于离散分类,返回k个点出现频率最多的类别作预测分类;对于回归则返回k个点的加权值作为预测值。
二 KNN算法的三个要素
KNN有三个基本的要素:K值的选择,距离度量,分类决策规则
(1)分类决策:KNN做分类预测时,一般是选择多数表决法,即训练集里和预测的样本特征最近的K个样本,预测为里面有最多类别数的类别。而KNN做回归时,一般是选择平均法,即最近的K个样本的样本输出的平均值作为回归预测值。
(2)k值的选择:没有一个固定的经验,一般根据样本的分布,选择一个较小的值,可以通过交叉验证选择一个合适的k值。
(3)距离度量:特征空间中2个实例点的距离是2个实例点相似程度的,反映一般情况下,计算两个点之间的距离采用的是欧氏距离比较多,还可以选择的距离有:L-p距离(即Minkowski距离)等。
L-p距离在p=1时为曼哈顿距离,p=2时为欧式距离,p=∞时为各个坐标距离的最大值。
三 分类 回归预测
KNN算法通过计算新数据与训练数据特征值之间的距离,然后选取K(K>=1)个距离最近的邻居进行分类判断(投票法)或者回归。但是他不仅可以用于分类,还可以用于回归。通过找出一个样本的k个最近邻居,将这些邻居的属性的平均值赋给该样本,就可以得到该样本的属性。更有用的方法是将不同距离的邻居对该样本产生的影响给予不同的权值(weight),如权值与距离成正比。
3.1分类
假设下图,新来一个实例要找类别,定义K=5,通过距离度量,发现红色四个,蓝色一个,就说明了邻居决策他为红色类。
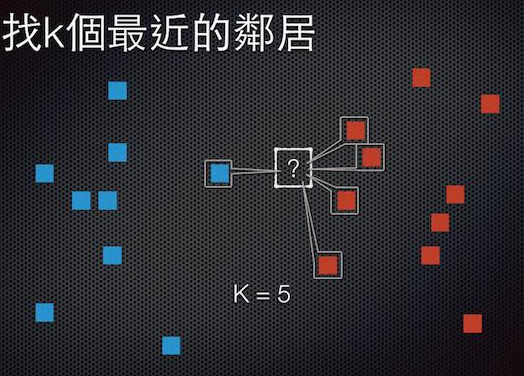
常见的图
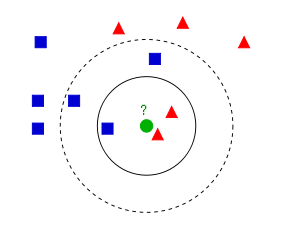
如果K=3,那么离绿色点最近的有2个红色三角形和1个蓝色的正方形,这3个点投票,于是绿色的这个待分类点属于红色的三角形。
如果K=5,那么离绿色点最近的有2个红色三角形和3个蓝色的正方形,这5个点投票,于是绿色的这个待分类点属于蓝色的正方形。
3.2 预测回归
假设我们有下面一组数据,假设X是流逝的秒数,Y值是随时间变换的一个数值(你可以想像是股票值)

那么,当时间是6.5秒的时候,Y值会是多少呢?我们可以用KNN算法来预测之。
这里,让我们假设K=2,于是我们可以计算所有X点到6.5的距离,如:X=5.1,距离是 | 6.5 –5.1 | = 1.4,X = 1.2那么距离是| 6.5 – 1.2 | = 5.3。于是我们得到下面的表:
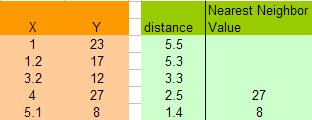
注意,上图中因为K=2,所以得到X=4和 X =5.1的点最近,得到的Y的值分别为27和8,在这种情况下,我们可以简单的使用平均值来计算:(27+8)/2=17.5
于是,最终预测的数值为:17.5

该方法的另一个不足之处是计算量较大,因为对每一个待分类的文本都要计算它到全体已知样本的距离,才能求得它的K个最近邻点。目前常用的解决方法是事先对已知样本点进行剪辑,事先去除对分类作用不大的样本。该算法比较适用于样本容量比较大的类域的自动分类,而那些样本容量较小的类域采用这种算法比较容易产生误分。
实现 K 近邻算法时,主要考虑的问题是如何对训练数据进行快速 K 近邻搜索,这在特征空间维数大及训练数据容量大时非常必要。
四 应用
- 训练KNN模型
bool CvKNearest::train( const CvMat* _train_data, const CvMat* _responses,const CvMat* _sample_idx=0,bool is_regression=false, int _max_k=32, bool _update_base=false );
这个类的方法训练K近邻模型。
它遵循一个一般训练方法约定的限制:只支持CV_ROW_SAMPLE数据格式,输入向量必须都是有序的,而输出可以 是 无序的(当is_regression=false),可以是有序的(is_regression = true)。并且变量子集和省略度量是不被支持的。
参数_max_k 指定了最大邻居的个数,它将被传给方法find_nearest。
参数 _update_base 指定模型是由原来的数据训练(_update_base=false),还是被新训练数据更新后再训练(_update_base=true)。在后一种情况下_max_k 不能大于原值, 否则它会被忽略。
- 寻找输入向量的最近邻
float CvKNearest::find_nearest( const CvMat* _samples, int k, CvMat* results=0, const float** neighbors=0, CvMat* neighbor_responses=0, CvMat* dist=0 ) const;
参数说明:
- samples为样本数*特征数的浮点矩阵;
- K为寻找最近点的个数;results与预测结果;
- neibhbors为k*样本数的指针数组(输入为const,实在不知为何如此设计);
- neighborResponse为样本数*k的每个样本K个近邻的输出值;
- dist为样本数*k的每个样本K个近邻的距离。
#include <opencv2/ml/ml.hpp>
#include <iostream>
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/imgproc/imgproc.hpp>
using namespace std;
using namespace cv;
int main()
{
float labels[10] = {0,0,0,0,0,1,1,1,1,1};
Mat labelsMat(10, 1, CV_32FC1, labels);
cout<<labelsMat<<endl;
float trainingData[10][2];
// srand(time(0));
for(int i=0;i<5;i++){
trainingData[i][0] = rand()%255+1;
trainingData[i][1] = rand()%255+1;
trainingData[i+5][0] = rand()%255+255;
trainingData[i+5][1] = rand()%255+255;
}
Mat trainingDataMat(10, 2, CV_32FC1, trainingData);
cout<<trainingDataMat<<endl;
CvKNearest knn;
knn.train(trainingDataMat,labelsMat,Mat(), false, 2 );
// Data for visual representation
int width = 512, height = 512;
Mat image = Mat::zeros(height, width, CV_8UC3);
Vec3b green(0,255,0), blue (255,0,0);
for (int i = 0; i < image.rows; ++i){
for (int j = 0; j < image.cols; ++j){
const Mat sampleMat = (Mat_<float>(1,2) << i,j);
Mat response;
float result = knn.find_nearest(sampleMat,1);
if (result !=0){
image.at<Vec3b>(j, i) = green;
}
else
image.at<Vec3b>(j, i) = blue;
}
}
// Show the training data
for(int i=0;i<5;i++){
circle( image, Point(trainingData[i][0], trainingData[i][1]),
5, Scalar( 0, 0, 0), -1, 8);
circle( image, Point(trainingData[i+5][0], trainingData[i+5][1]),
5, Scalar(255, 255, 255), -1, 8);
}
imshow("KNN Simple Example", image); // show it to the user
waitKey(0);
return 0;
} 
http://blog.csdn.net/xiaowei_cqu/article/details/23782561
http://coolshell.cn/articles/8052.html
http://blog.csdn.net/xiaowei_cqu/article/details/23782561
http://www.cnblogs.com/xiangshancuizhu/archive/2011/08/06/2129355.html
图像识别算法交流 QQ群:145076161,欢迎图像识别与图像算法,共同学习与交流















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









