









文章目录
什么是threadlocal
threadlocal可以理解为线程自身的本地变量,只有线程自身可以访问,每个线程都会维护自己的threalocal。
如何使用
使用方式非常简单,核心就两个方法set/get
public class TestThreadLocal {
private static final ThreadLocal<String> threadLocal = new ThreadLocal<>();
public static void main(String[] args) {
new Thread(new Runnable() {
@Override
public void run() {
try {
threadLocal.set("aaa");
Thread.sleep(500);
System.out.println("threadA:" + threadLocal.get());
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}).start();
new Thread(new Runnable() {
@Override
public void run() {
threadLocal.set("bbb");
System.out.println("threadB:" + threadLocal.get());
}
}).start();
}
}
运行结果
threadB:bbb
threadA:aaa
通过以上代码可以看到两个线程使用了一个threadlocal,第一个线程设置值先于第二个线程,第二个线程先于第一个线程get,可以看到,获取的值并没有被影响,也就证明了每个线程只能获取到本线程的变量。
应用场景
它可以在哪些场景使用呢?
- 在多租户系统中,可以在全局前置拦截器中解析租户id放入threadlocal中并封装一个util,controller/service直接TenementUtil.get()就可以获取到,不需要重复解析,也不需要每个controller方法都去解析一遍租户id造成大量代码冗余
- 同样的逻辑可以在全局前置拦截器中将用户的信息解析放入threadlocal中
- 看过我xxl-job源码篇的话应该知道,xxl-job执行器封装的上下文对象也是用threadlocal存储的,这样我们只需要关注业务逻辑就可以了
ThreadLocal是怎么做到一个线程有多个ThreadLocal对象的呢
每个Thread类中都维护了threadLocals变量
ThreadLocal.ThreadLocalMap threadLocals = null;
我们看一下ThreadLocal.ThreadLocalMap的构造函数
ThreadLocalMap(ThreadLocal<?> firstKey, Object firstValue) {
// 初始化entry表
table = new Entry[INITIAL_CAPACITY];
// 计算table表的位置
int i = firstKey.threadLocalHashCode & (INITIAL_CAPACITY - 1);
table[i] = new Entry(firstKey, firstValue);
// 当前size
size = 1;
// 设置阈值
setThreshold(INITIAL_CAPACITY);
}
可以看到,threadlocalmap维护了一个table数组,数组的位置由ThreadLocal中threadLocalHashCode保证
我们看一下threadLocalHashCode的逻辑,定位到ThreadLocal这段代码
// 本对象私有常量
private final int threadLocalHashCode = nextHashCode();
// 共享原子对象
private static AtomicInteger nextHashCode =
new AtomicInteger();
private static final int HASH_INCREMENT = 0x61c88647;
private static int nextHashCode() {
// 获取并增加,原子操作
return nextHashCode.getAndAdd(HASH_INCREMENT);
}
可以看到每个ThreadLocal对象都维护了final类型的threadLocalHashCode,而该常量是通过静态方法AtomicInteger.getAndAdd获取的,AtomicInteger是基于cas的原子操作,因此并发创建下也不会有重复的情况,这种情况下我们每个ThreadLocal对象的threadLocalHashCode都可以保证绝对唯一。也就是说每次new ThreadLocal都有不同的threadLocalHashCode值。
ThreadLocal内存泄露的问题
说到内存泄露,不得不先了解threadlocal的存储结构和引用,我们先看一下ThreadLocalMap构造方法
ThreadLocalMap(ThreadLocal<?> firstKey, Object firstValue) {
// 初始化entry表
table = new Entry[INITIAL_CAPACITY];
// 计算table表的位置
int i = firstKey.threadLocalHashCode & (INITIAL_CAPACITY - 1);
table[i] = new Entry(firstKey, firstValue);
// 当前size
size = 1;
// 设置阈值
setThreshold(INITIAL_CAPACITY);
}
可以看到此处存储用的是Entry对象,我们看一下它的结构
static class Entry extends WeakReference<ThreadLocal<?>> {
Object value;
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}
可以看到Entry对象继承了WeakReference(弱引用)对象,这里为什么要用弱引用呢?
通过下图我们可以看一下ThreadLocal引用结构,虚线为弱引用,实线为强引用,不明白强引用和弱引用可以看我之前的文章JAVA中的引用类型,强引用软引用弱引用虚拟引用

可以看到,ThreadLocal作为Entry的key,它是一个弱引用,当没有外部强引用ThreadLocal对象时,那么下次gc回收时一定会将ThreadLocal回收。
使用过程中建议将ThreadLocal放入成员变量位置,尽量用static修饰,避免频繁创建ThreadLocal实例。
当存储大对象也要小心,如非必要尽量不要存储大对象,如果一定有必要,使用完后建议调用remove方法移除对象,避免出现堆内存溢出的问题。
当线程结束后ThreadLocalMap和Entry表会被回收。
set(T value)方法
找到java.lang.ThreadLocal#set
public void set(T value) {
// 获得当前线程实例
Thread t = Thread.currentThread();
// 获得存储对象
ThreadLocalMap map = getMap(t);
if (map != null) {
// 设置value
map.set(this, value);
} else {
// 创建并设置
createMap(t, value);
}
}
当set时会获得当前对象,并尝试从Thread对象中获得threadLocalMap对象,没有就创建
我们看一下getMap和createMap方法
ThreadLocalMap getMap(Thread t) {
return t.threadLocals;
}
void createMap(Thread t, T firstValue) {
t.threadLocals = new ThreadLocalMap(this, firstValue);
}
可以看到,threadLocalMap对象是由Thread对象维护的,也就是说每一个线程都有一个独立的threadLocalMap对象,当Thread的threadLocals对象为空时则会创建这个ThreadLocalMap对象
接下来看看值是如何设置的java.lang.ThreadLocal.ThreadLocalMap#set
private void set(ThreadLocal<?> key, Object value) {
Entry[] tab = table;
int len = tab.length;
// 计算数组下标
int i = key.threadLocalHashCode & (len-1);
// 找到相同的threadlocal,如果找不索引加一继续找
// 此处跳出有两个条件,找到相同的threadlocal,或者找k为null
// 此处主要作用就是看数组中是否存在threadlocal,存在就覆盖赋值
for (Entry e = tab[i];
e != null;
e = tab[i = nextIndex(i, len)]) {
ThreadLocal<?> k = e.get();
if (k == key) {
// 如果找到threadlocal就直接修改值并结束set
e.value = value;
return;
}
if (k == null) {
// 不存在需要替换过期值
replaceStaleEntry(key, value, i);
return;
}
}
// 代码走到这里说明没有找到threadlocal,也不存在过期值,那么直接给索引位置设置entry
tab[i] = new Entry(key, value);
int sz = ++size;
if (!cleanSomeSlots(i, sz) && sz >= threshold)
// 扩容动作
rehash();
}
注意此处replaceStaleEntry,代码走到这里说明存在过期值,前面我们讲了threadlocal被entry弱引用,当主线程中不存在强引用了,自然也就会被gc回收,这时就出现一个状况,entry对象存在,但是key值不存在了,此时就会调用这个方法将数据置换,
采用了开放地址法,当下标发生冲突,就去寻找下一个空的位置
我用下图解释一下以上面的代码,假设我有entry1-5,现在table中存储了entry1,entry2,entry3,entry4,现在要存入entry5,计算下标为2,最终entry5实际存入下标3
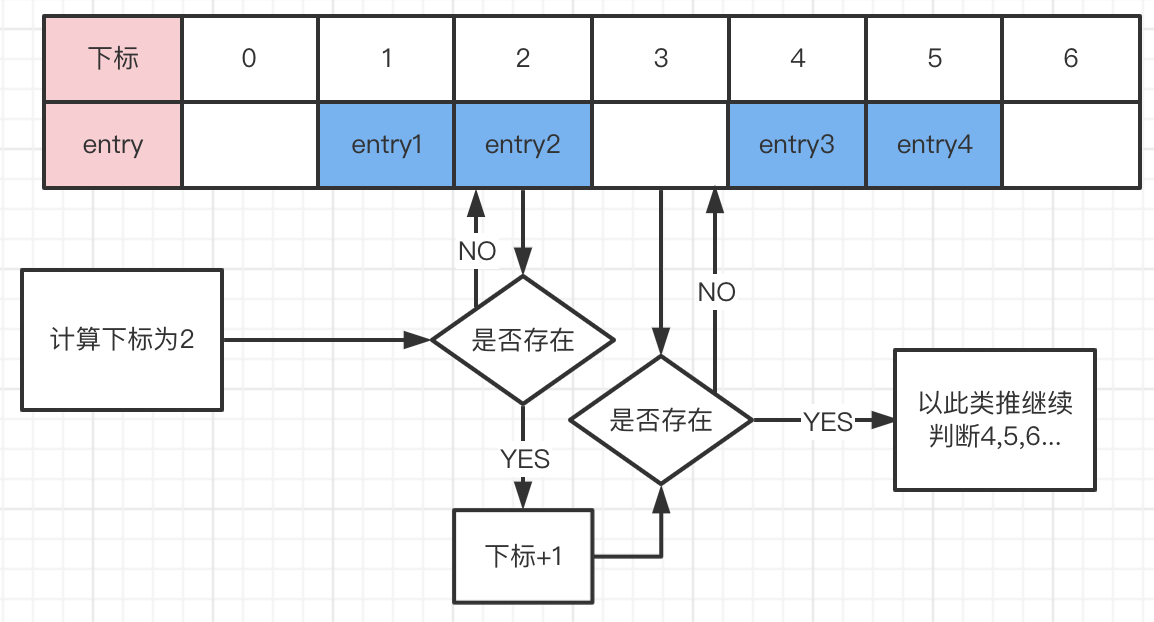

现在entry3的key(也就是threadlocal)失去强引用后,其entry依旧会留存于table数组中,当计算索引为所在位置时会进行置换动作。
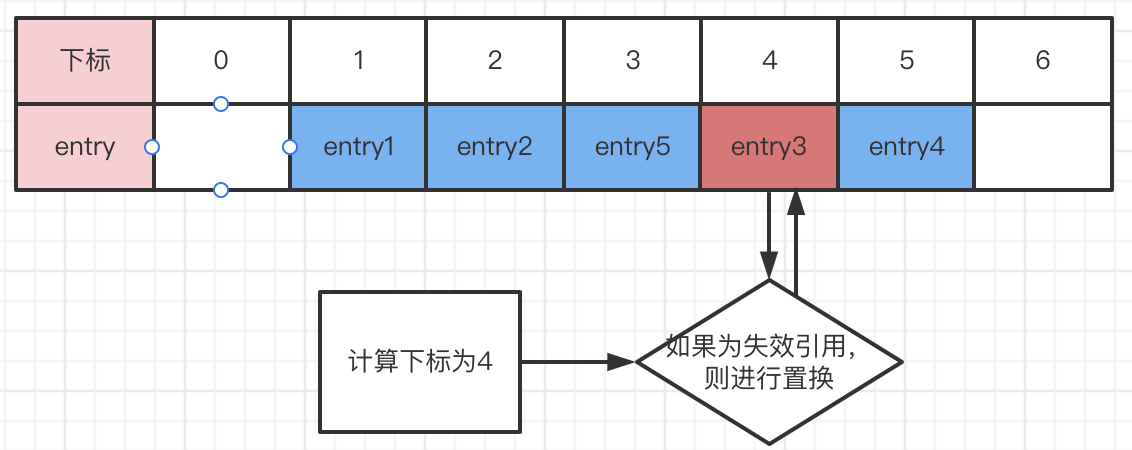
我们看一下置换的代码java.lang.ThreadLocal.ThreadLocalMap#replaceStaleEntry
private void replaceStaleEntry(ThreadLocal<?> key, Object value,
int staleSlot) {
Entry[] tab = table;
int len = tab.length;
Entry e;
int slotToExpunge = staleSlot;
// 向前找到最小失效的下标
for (int i = prevIndex(staleSlot, len);
(e = tab[i]) != null;
i = prevIndex(i, len))
if (e.get() == null)
slotToExpunge = i;
// 向后遍历++操作 和上面正好相反
for (int i = nextIndex(staleSlot, len);
(e = tab[i]) != null;
i = nextIndex(i, len)) {
ThreadLocal<?> k = e.get();
// 找到相同的key则需要进行置换动作
if (k == key) {
// 置换value 和key
e.value = value;
tab[i] = tab[staleSlot];
tab[staleSlot] = e;
// 如果第一层循环没有找到任何对象,需要将数据对其
if (slotToExpunge == staleSlot)
slotToExpunge = i;
// 清理过期entry 结束置换动作
cleanSomeSlots(expungeStaleEntry(slotToExpunge), len);
return;
}
// 如果key不存在,且前面不存在失效的key,则将数据对其
if (k == null && slotToExpunge == staleSlot)
slotToExpunge = i;
}
// 没有找到相同的key则直接new一个新的entry放进去
tab[staleSlot].value = null;
tab[staleSlot] = new Entry(key, value);
// 清楚其他的过期对象
if (slotToExpunge != staleSlot)
cleanSomeSlots(expungeStaleEntry(slotToExpunge), len);
}
可以看到,当存在过期的情况并不会直接清除,而是复用之前的entry对象,当entry不存在时才会重新new一个entry
get()方法
通过前面的内容,我们已经了解了整个threadlocal的运作原理和引用结构,接下来我们深入剖析一下get方法
java.lang.ThreadLocal#get
public T get() {
// 获得当前线程
Thread t = Thread.currentThread();
// 获得threadlocalmap对象
ThreadLocalMap map = getMap(t);
if (map != null) {
// 获得entry对象
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null) {
@SuppressWarnings("unchecked")
T result = (T)e.value;
// 正常返回
return result;
}
}
// 当threadlocalmap不存在时 初始化threadlocalmap并返回
return setInitialValue();
}
java.lang.ThreadLocal.ThreadLocalMap#getEntry
private Entry getEntry(ThreadLocal<?> key) {
// 计算entry table索引
int i = key.threadLocalHashCode & (table.length - 1);
Entry e = table[i];
if (e != null && e.get() == key)
return e;
else
// 当entry的值不存在时
return getEntryAfterMiss(key, i, e);
}
java.lang.ThreadLocal.ThreadLocalMap#getEntryAfterMiss
private Entry getEntryAfterMiss(ThreadLocal<?> key, int i, Entry e) {
Entry[] tab = table;
int len = tab.length;
while (e != null) {
ThreadLocal<?> k = e.get();
if (k == key)
// 找到entry
return e;
if (k == null)
// 移除过期条目
expungeStaleEntry(i);
else
// 向下扫描
i = nextIndex(i, len);
e = tab[i];
}
return null;
}
为什么不直接使用hashmap呢
一般情况下,ThreadLocal存储的数据量不会太大,被remove后会被垃圾回收器回收,数据结构就一层数组,使用这种存储方式更省空间,数组下标查询效率也更高
数据结构:
hashmap是数组+链表+红黑树
threadlocalmap只有数组
引用类型:
hashmap value是强引用,不利于内存释放
threadlocalmap是弱引用,内存表现更优秀
hash冲突:
hashmap通过链表/红黑树解决冲突
threadlocalmap通过开放寻址解决冲突
性能上:
hashmap大数据量下性能更优
threadlocalmap数据量不大的情况下性能更好















 313
313











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









