







闲着没事,想方便的看一些小网站,就打算动手写一个爬虫,根据使用了上一次写酷q的自动回复机器人封装的clientSocket类,至于为什么不用python,几行代码就可以做完的事,用C++写了200多行,因为觉得用C++造轮子挺有意思的,虽然我的C++用得很烂…….
做完这个后,我发现我对http的请求格式,有很大的误解,所以在上次写酷q请求数据的时候,http没有发送响应消息,就发了报文。
http协议详解:https://www.cnblogs.com/li0803/archive/2008/11/03/1324746.html
爬虫思路:
1、通过访问url(头节点,我们开始输入的网址),从该url中解析出图片资源(.jpg .png)链接与该网页中其他的网页链接(后面统称为节点)并保存至容器(如队列,栈之类)
2、通过请求图片url,下载完当前的网页中的图片后,我们就从刚刚获取的网页链接(节点)中扩展,也就是读取其他的节点,然后重复步骤1。
3、为了防止重复加载同一个节点,用map(字典)对节点进行计数。
碰见的问题:
1、如解析url的时候,我首先想到的是用正则表达式去匹配,(http://)?(^\/)(.*) ,然后通过分组获取host与filepath,程序运行开始下载几张图片的时候是没问题,但是后面会报错然后程序蹦了,通过日志发现,在解析一些的图片资源时,解析会失败,并没有把http:// 给去掉,以至于host是带有http://,这个问题我也不知道怎么回事,正则表达式应该是对的,测试了也是正确的。
解决方法:不用正则表达式,直接用string,将我们要提取的字符串substr提取出来,程序就能正常运行。
2、并不是所有的http网站都可以爬到图片,虽然代码中的这个腾讯新闻网站没事,但是爬http://www.acfun.cn/,的时候会碰到解析图片资源的url错误(应该是正则表达式写法的问题),目前没想好怎么写,改过几次,可能需要根据不同的网站写不同的正则表达式,匹配相应的资源。
3、C++正则表达式的使用,以及regex_serach的使用。
结果:
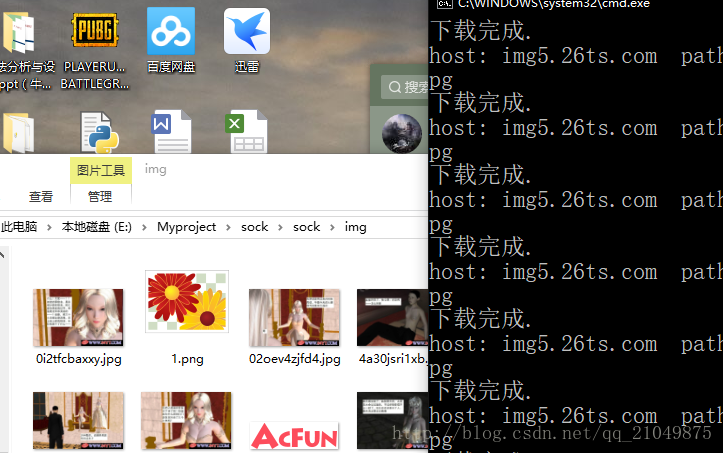
代码:
urlDownload.h
#pragma once
#include <winsock2.h>
#include<iostream>
#include <fstream>
#include<string>
#include<vector>
#include<queue>
#include<map>
using namespace std;
#pragma comment(lib, "ws2_32.lib")
class urlDownload {
private:
//socket
WSADATA ws;
SOCKET sock;
//data
queue<string>htmlurl;
vector<string>comurl;
vector<string>imageurl;
map<string, int>urlmap;
//addr
string host;
string filepath;
//log对象
ofstream wlog;
//获取资源名称
string getFileName(const string &filepath);
void parse_url(const string &url);
//获取html里的img url
void getImageUrl(const string &allHtml);
//获取com url
void getComUrl(const string &allHtml);
//错误日志
void log(const string &str);
string iToa(int num);
//http Get请求
void request(const string &url);
//接收请求网页得到的html文本,可以在工程文件夹看到相关的html文件
void recvUrl();
public:
urlDownload() {
CreateDirectoryA("./img", 0);
WSAStartup(MAKEWORD(2, 2), &ws);
}
~urlDownload() {
WSACleanup();
}
//接收网页的图片
void downLoadImage(const string &url);
void run(const string &url);
};
urlDownload.cpp
#include"urlDownload.h"
#include<conio.h>
#include<regex>
void urlDownload::log(const string & str){
wlog.open("log.txt", ios::binary | ios::out | ios::app);
wlog << (str + "\n").c_str();
wlog.close();
}
string urlDownload::getFileName(const string & filepath){
string name = "";
int len = filepath.length();
for (int i = len; i != 0; i--) {
if (filepath[i] == '/') {
name.assign(filepath, i + 1, len - 1);
break;
}
}
return name;
}
void urlDownload::parse_url(const string & url){
auto hpos = url.find("http://");
if (hpos == string::npos) {
auto epos = url.find('/');
host = url.substr(0, epos);
filepath = "/";
}
else {
hpos += strlen("http://");
auto epos = url.find('/', hpos);
if (epos == string::npos) {
return;
}
host = url.substr(hpos, epos - hpos);
filepath = url.substr(epos, url.length() - epos);
}
}
void urlDownload::getImageUrl(const string & allHtml){
smatch mat;
regex pattern("src=\"(.+?\.(jpg|png))\"");
string::const_iterator start = allHtml.begin();
string::const_iterator end = allHtml.end();
while (regex_search(start, end, mat, pattern))
{
string msg(mat[1].first, mat[1].second);
imageurl.push_back(msg);
start = mat[0].second;
}
}
void urlDownload::getComUrl(const string & allHtml){
smatch mat;
regex pattern("href=\"(http://[^\s\"]+)\"");
string::const_iterator start = allHtml.begin();
string::const_iterator end = allHtml.end();
while (regex_search(start, end, mat, pattern))
{
string msg(mat[1].first, mat[1].second);
comurl.push_back(msg);
start = mat[0].second;
}
}
string urlDownload::iToa(int num){
char *str = new char[10];
string temp = "";
itoa(num, str, 10);
temp += str;
delete[]str;
return temp;
}
void urlDownload::request(const string & url){
parse_url(url);
sock = socket(AF_INET, SOCK_STREAM, 0);
if (sock == INVALID_SOCKET) {
cout << string("建立socket失败! 错误码: " + iToa(WSAGetLastError()));
return;
}
hostent *phost = gethostbyname(host.c_str());
if (phost == NULL) {
string temp("主机无法解析出ip! addr: " + host + filepath + "错误码: " + iToa(WSAGetLastError()));
cout << temp;
log(temp);
return;
}
sockaddr_in server = { AF_INET };
server.sin_port = htons(80);
memcpy(&server.sin_addr, phost->h_addr, 4);
if (connect(sock, (sockaddr*)&server, sizeof(server)) == SOCKET_ERROR)
{
cout << string("连接失败 addr: " + host + filepath + " 错误码:" + iToa(WSAGetLastError()));
closesocket(sock);
return;
}
string reqInfo = "GET " + (string)filepath + " HTTP/1.1\r\nHost: " + (string)host + "\r\nConnection:Close\r\n\r\n";
if (SOCKET_ERROR == send(sock, reqInfo.c_str(), reqInfo.size(), 0))
{
cout << string("send error! 错误码: " + iToa(WSAGetLastError()));
closesocket(sock);
return;
}
}
void urlDownload::downLoadImage(const string & url){
request(url);
string name = getFileName(filepath);
string savePath = "./img/" + name;
ofstream out;
out.open(savePath, ios::out | ios::binary);
char buff[1024];
string mes = "";
memset(buff, 0, sizeof(buff));
int len;
len = recv(sock, buff, sizeof(buff) - 1, 0);
mes += buff;
char *cpos = strstr(buff, "\r\n\r\n");
out.write(cpos + strlen("\r\n\r\n"), len - (cpos - buff) - strlen("\r\n\r\n"));
while ((len = recv(sock, buff, sizeof(buff) - 1, 0)) > 0) {
out.write(buff, len);
}
cout << "下载完成.\n" << "host: " << host << " " << "path: " << filepath << endl;
out.close();
closesocket(sock);
}
void urlDownload::recvUrl(){
static int htmlNum = 1;
char fileName[100];
sprintf(fileName, "data%d.txt", htmlNum);
htmlNum++;
char buff[1024];
string msg = "";
memset(buff, 0, sizeof(buff));
int len;
ofstream out(fileName, ios::out | ios::binary);
while ((len = recv(sock, buff, sizeof(buff) - 1, 0)) > 0) {
msg += buff;
out.write(buff, len);
}
out.close();
getImageUrl(msg);
getComUrl(msg);
closesocket(sock);
}
void urlDownload::run(const string &url){
htmlurl.push(url);
while (!htmlurl.empty()) {
auto tempurl = htmlurl.front();
htmlurl.pop();
urlmap[tempurl]++;
request(tempurl);
recvUrl();
for (auto i : imageurl) {
downLoadImage(i);
}
imageurl.clear();
for (auto i : comurl) {
if (urlmap[i] == 0) {
htmlurl.push(i);
}
}
comurl.clear();
}
}
main:
urlDownload t;
t.run("http://news.qq.com/");














 1344
1344

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









