







 本文介绍了如何从小米运动应用导出数据,并使用Python进行深度分析,特别是针对睡眠数据的解析。作者通过备份手机数据,提取小米运动的SQLite数据库,然后使用Python连接数据库,解析包含睡眠、步数等信息的summary字段,最终将数据转化为Excel进行进一步分析。
本文介绍了如何从小米运动应用导出数据,并使用Python进行深度分析,特别是针对睡眠数据的解析。作者通过备份手机数据,提取小米运动的SQLite数据库,然后使用Python连接数据库,解析包含睡眠、步数等信息的summary字段,最终将数据转化为Excel进行进一步分析。
背景:我本身是做数据分析的,因为长期失眠所以想看看自己小米手环上面的数据,找找原因。因为小米运动上自带的报表比较粗浅,所以就想自己导出数据,深入分析一波。
1 备份小米运动并导出
数据导出部分,需要感谢下面这个作者的分享:
https://blog.csdn.net/MizarTian/article/details/85414507
我再代为详细描述一下数据导出的流程:
1.小米运动数据打包。打包路径(以MIUI12.5.2为例):设置->更多设置->备份与恢复->手机备份恢复->第三方应用程序和应用数据(仅勾选小米运动)->立即备份
2.手机链接电脑,将数据拷贝置电脑,手机上的存放路径是:MIUI/backup/AllBackup/(以你备份时间命名的文件夹)/小米运动。把底下.bak文件拷贝到电脑。
剩下的部分,参考上面的链接就可以了,为防上面的链接被作者删除,我这里复制粘贴下原文作者的内容:
2 拆包bak文件
用记事本等文本编辑器打开备份文件,“ANDROID BACKUP”之前的文件头,即“MIUI BACKUP……”,保存退出后,即为原生的安卓备份文件。
备份文件的拆解需要解包工具,称为“android-backup-extractor”,需要JAVA环境和命令行操作。
解包工具可以从GitHub上下载,将下载的文件名称设为“abe-all.jar”。
然后新建一个文本文件(.txt),在其中输入以下代码:
@echo off
color b
echo.
set bakFile=%1
if defined bakFile (goto javas) else set /p bakFile=请拖入修改后的Bak文件:
:javas
java -jar "%~dp0\abe-all.jar" unpack %bakFile% %bakFile%.tar
echo.
echo 操作结束...
pause>nul保存文件,并将后缀名改为(.bat)。这个文件和先前的jar文件应处于同一文件夹下。
双击打开bat文件,按提示将bak文件拖入程序窗口内,按下回车,等待一会儿就可以找到与bak文件同名的tar文件了。
3 找到数据文件
使用解压工具解压tar文件,找到文件夹apps/com.xiaomi.hm.health/db ,按文件大小排序,最大的文件应当是我们所需的文件,名称是origin_db_xxxx,没有任何后缀。
我接着从“读取文件”部分开始介绍:
4 读取文件
原文中读取文件推荐使用SQLite Database Browser,但我使用的是SQLite Expert Personal。
使用软件打开origin_db_xxxx,效果如下:
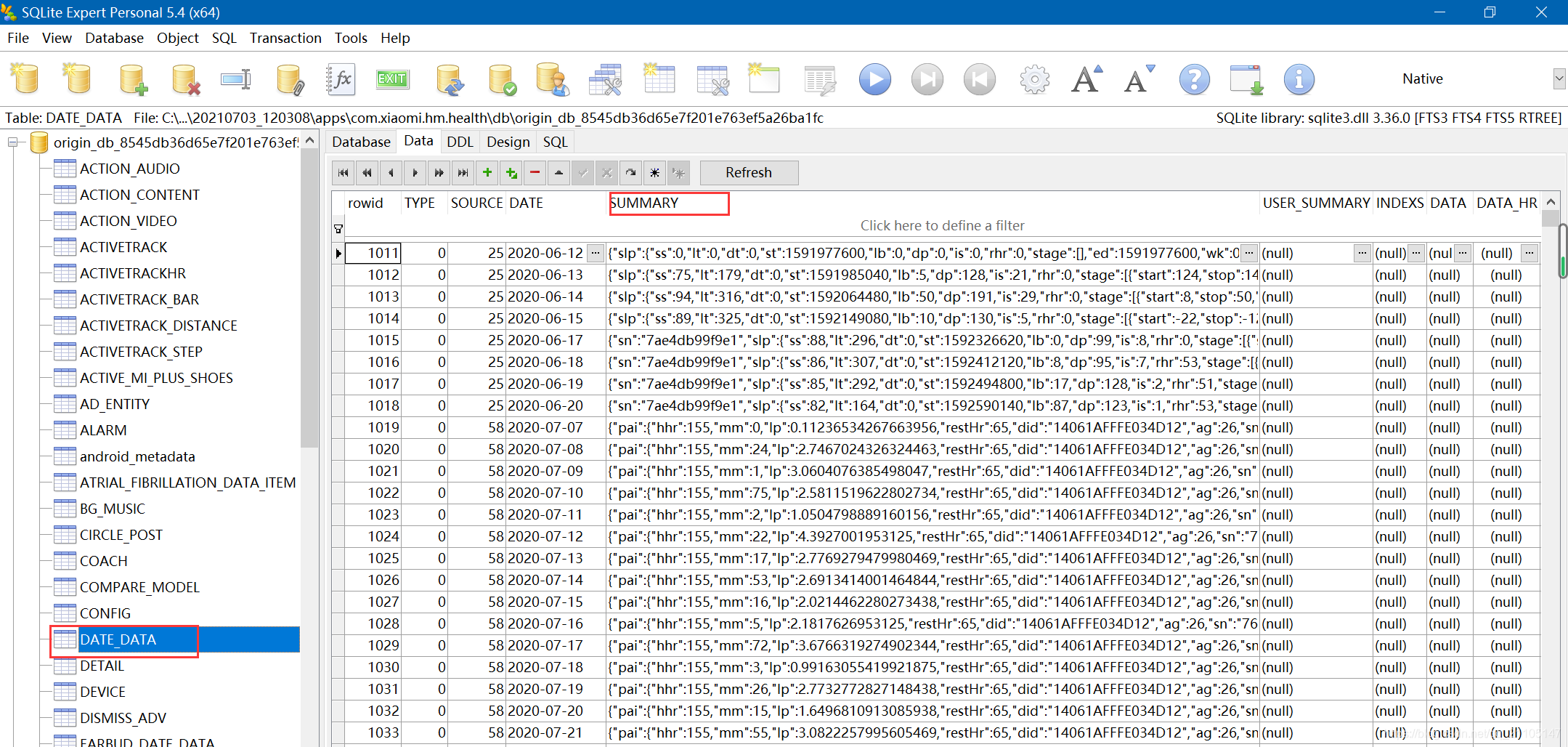
这个文件其实是一个库,而我们的睡眠数据是保存在这个库底下的表“date_data”底下的字段“summary”,也就是睡眠数据其实是以文本日志的形式存放的,并且这个日志中还有步数、运动量等等数据,于是就涉及到日志的解读和数据的提取。
summary的解读
我复制了几个summary到Notepad++,并且跟自己手机上面的小米运动数据进行比对,最后总结如下:
1.summary首先看起来就像一个python字典;
2.睡眠就保存在字典里面的key"slp"底下;
3.而"slp"本身的value本身也是一个字典,
3.1."st"代表睡眠开始时间,以数字形式存储时间;
3.2."ed"代表睡眠结束时间,以数字形式存储时间;
以上2个时间是以1970/1/1 8:00开始,计算秒的数量,由于有些人可能需要用excel分析,所以这里附上这个数字在excel里面的转换公式:=X/(60*60*24)+25569.3333333333
为何是用这个公式,留给大家自己思考。
3.3."dp"代表深睡时间,深睡的分钟数;
3.4."lt"代表浅睡时间,浅睡的分钟数;
3.5."wk"代表清醒时间,清醒的分钟数;
3.6."dt"代表REM时间,REM的分钟数;
3.7."odd_stage"代表小睡数据,是一个list,里面每个元素保持一个阶段的小睡数据,每个元素都是 一个字典,该字典key解读如下:
3.7.1."start"代表小睡开始时间,从昨日凌晨开始算起的分钟数;
3.7.2."stop"代表小睡结束时间,从昨日凌晨开始算起的分钟数;
在我后面的分析中,我会把这个时间转化了以今日凌晨开始算起的小时数,转换公式为:X/60-24。
既然,以上数据长得这么像一个python字典,我自然选用python开始数据提取:
Python数据提取与导出
import sqlite3 as db # sqlite3数据库连接的包
import pandas as pd
import numpy as np
import ast # 字符串转为字典的包
import datetime
# 控制台输出不省略
pd.set_option('display.max_columns', 1000)
pd.set_option('display.width', 500)
# pd.set_option('display.max_colwidth', 1000)
# 从SQLite文件中读取数据
def readFronSqllite(db_path, exectCmd):
conn = db.connect(db_path) # 该 API 打开一个到 SQLite 数据库文件 database 的链接,如果数据库成功打开,则返回一个连接对象
cursor = conn.cursor() # 该例程创建一个 cursor,将在 Python 数据库编程中用到。
conn.row_factory = db.Row # 可访问列信息
cursor.execute(exectCmd) # 该例程执行一个 SQL 语句
rows = cursor.fetchall() # 该例程获取查询结果集中所有(剩余)的行,返回一个列表。当没有可用的行时,则返回一个空的列表。
table = pd.DataFrame(rows, columns=['DATE', 'SUMMARY'])
return table
# print(rows[0][2]) # 选择某一列数据
# 解析ARPA 单帧信息,我的代码没有用到这块
def readfromAppaFrame(ARPAFrame):
subARPA = ARPAFrame.split(',')
print(subARPA)
if __name__ == "__main__":
table = readFronSqllite(
'C:\\Users\\Meaon\\Desktop\\20210703_120308\\apps\\com.xiaomi.hm.health\\db\\origin_db_8545db36d65e7f201e763ef5a26ba1fc',
"select DATE,SUMMARY from DATE_DATA order by date")
# 以下空列表用于保存将要加入dataframe的每列数据
st = []
ed = []
dp = []
lt = []
wk = []
dt = []
# 我这里有6个列来保存每日3段小睡的数据,实际上这里最好用动态分配内存的方式来做会更加灵活
o_st1=[]
o_st2=[]
o_st3=[]
o_ed1=[]
o_ed2=[]
o_ed3=[]
for SUMMARY in table["SUMMARY"]: # 循环遍历每一行的SUMMARY
# 保持字典各个层级的相关数据到空列表
st.append(datetime.datetime.fromtimestamp(ast.literal_eval(SUMMARY)["slp"]["st"]))
ed.append(datetime.datetime.fromtimestamp(ast.literal_eval(SUMMARY)["slp"]["ed"]))
dp.append(ast.literal_eval(SUMMARY)["slp"]["dp"])
lt.append(ast.literal_eval(SUMMARY)["slp"]["lt"])
wk.append(ast.literal_eval(SUMMARY)["slp"]["wk"])
# 由于不是每天都有REM数据,所以需要进行一个判断,没有REM的保存为0
if (ast.literal_eval(SUMMARY)["slp"].get("dt")):
dt.append(ast.literal_eval(SUMMARY)["slp"]["dt"])
else:
dt.append(0)
# 由于不是每天都有小睡数据,所以需要进行一个判断,没有REM的保存为0
if (ast.literal_eval(SUMMARY)["slp"].get("odd_stage")):
ii=0
for i,odd_stage in enumerate(ast.literal_eval(SUMMARY)["slp"]["odd_stage"]):
if i==0:
o_st1.append(odd_stage["start"])
o_ed1.append(odd_stage["stop"])
ii = i
elif i==1:
o_st2.append(odd_stage["start"])
o_ed2.append(odd_stage["stop"])
ii = i
elif i==2:
o_st3.append(odd_stage["start"])
o_ed3.append(odd_stage["stop"])
ii = i
if ii==0:
o_st2.append(0)
o_st3.append(0)
o_ed2.append(0)
o_ed3.append(0)
elif ii==1:
o_st3.append(0)
o_ed3.append(0)
else:
o_st1.append(0)
o_st2.append(0)
o_st3.append(0)
o_ed1.append(0)
o_ed2.append(0)
o_ed3.append(0)
# datafram新增列,把我们提取的数据拷贝进去
table["st"] = st
table["ed"] = ed
table["dp"] = dp
table["lt"] = lt
table["wk"] = wk
table["dt"] = dt
table["o_st1"] = o_st1
table["o_ed1"] = o_ed1
table["o_st2"] = o_st2
table["o_ed2"] = o_ed2
table["o_st3"] = o_st3
table["o_ed3"] = o_ed3
print(table[-10:])
# 将datafram保存成excle,后面的数据分析将在excel里面进行
table.to_excel("sleep.xlsx",index=False)以上代码涉及两个参考:
1.对sqlite3数据库的连接:
https://www.cnblogs.com/DHUtoBUAA/p/7389125.html
2.字符串转换为字典:
https://www.cnblogs.com/xiao-xue-di/p/11414210.html
数据分析
后面的数据分析以及更为灵活的加工就在excel里面进行,这里就不加赘言。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









