






本文主要是Pytorch2.0 的小实验,在MacBookPro 上体验一下等优化改进后的Transformer Self Attention的性能,具体的有 FlashAttention、Memory-Efficient Attention、CausalSelfAttention 等。主要是torch.compile(model) 和 scaled_dot_product_attention的使用。
相关代码已上传GitHub:https://github.com/chensaics/Pytorch2DL
原文接:在Mac上体验Pytorch 2.0 自注意力性能提升示例

Pytorch2.0版本来了,带来了很多的新技术。今天创建了Pytorch2DL仓库,主要是使用Jupyter Notebook 结合Pytorch2做一些深度学习的示例。
Pytorch2.0 技术亮点
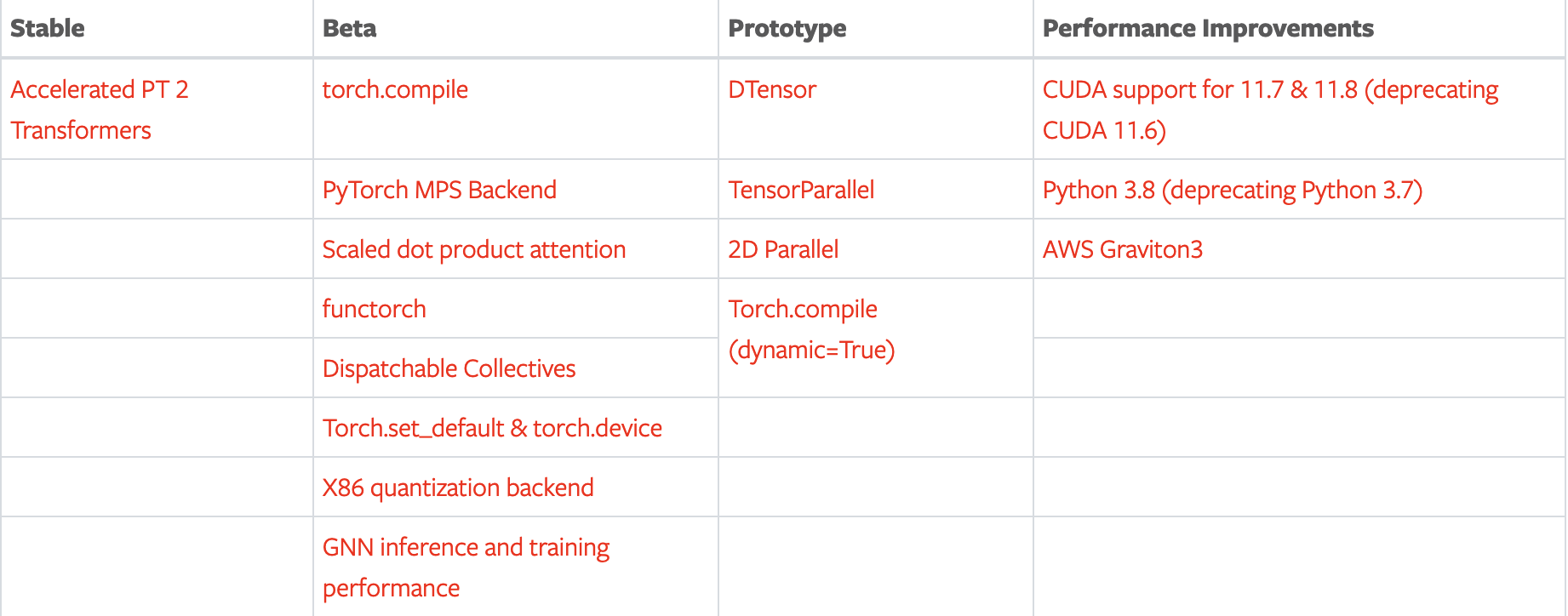
- torch.compile
包装并返回编译后的模型
- Accelerated Transformers
我们可以通过调用新的scaled_dot_product_attention() 函数直接使用缩放点积注意力 (SPDA)内核。以前我们想要加速训练,要使用第三方库,比如 Flash Attention、xFormers等,现在都被原生支持到框架中了,具体的是在 torch.nn.MultiheadAttention 和 TransformerEncoderLayer 中。
下一节我们使用上下文管理器显示调度不同的内核做性能对比。
- Metal Performance Shaders (MPS后端)
在Mac上也能享受GPU加速的PyTorch训练哦!
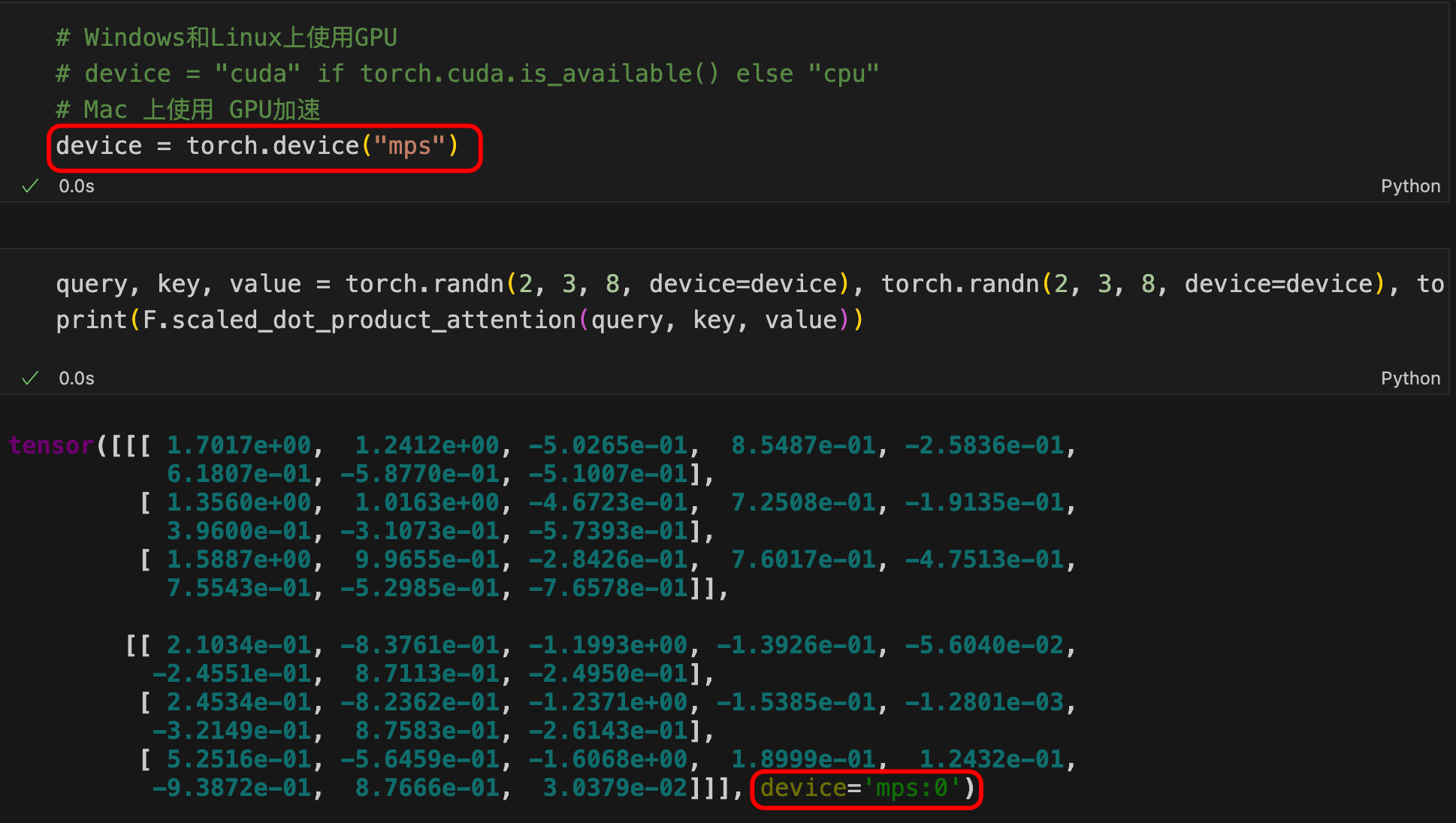
在Windows和Linux上使用GPU还是CPU,我们通常加一句:
device = “cuda” if torch.cuda.is_available() else “cpu”
在Mac上:
device = torch.device(“mps”)
我结合MPS和scaled_dot_product_attention做一个示例:
- 其他新技术
TensorParallel、DTensor、2D parallel、TorchDynamo、AOTAutograd、PrimTorch和TorchInductor
TorchDynamo是借助Python Frame Evaluation Hooks能安全地获取PyTorch程序;
AOTAutograd重载PyTorch autograd engine,作为一个 tracing autodiff,用于生成超前的backward trace。
PrimTorch简化了编写 PyTorch 功能或后端的流程。将 2000+ PyTorch 算子归纳为约 250 个 primitive operator 闭集 (closed set)。
TorchInductor一个深度学习编译器,可以为多个加速器和后端生成 fast code。
性能实验
目前有三种支持scaled_dot_product_attention的:
- FlashAttention
- Memory-Efficient Attention
- PyTorch C++ 公式实现 (MATH)
他们可以通过这几个函数启用禁用:
enable_flash_sdp(): 启用或禁用FlashAttention.
enable_mem_efficient_sdp(): 启用或禁用 Memory-Efficient Attention.
enable_math_sdp(): 启用或禁用 PyTorch C++ implementation.
我在Mac上做了一个 scaled_dot_product_attention 结合 sdp_kernel() 上下文管理器来显式调度(指定、启用/禁用)其中一个融合内核运行 的实验:
import torch
import torch.nn as nn
import torch.nn.functional as F
from rich import print
from torch.backends.cuda import sdp_kernel
from enum import IntEnum
import torch.utils.benchmark as benchmark
# Windows和Linux上使用GPU
# device = "cuda" if torch.cuda.is_available() else "cpu"
# Mac 上使用 GPU加速:
# device = torch.device("mps")
device = "mps" if torch.backends.mps.is_built() else "cpu"
# 超参数定义
batch_size = 64
max_sequence_len = 256
num_heads = 32
embed_dimension = 32
dtype = torch.float16
# 模拟 q k v
query = torch.rand(batch_size, num_heads, max_sequence_len, embed_dimension, device=device, dtype=dtype)
key = torch.rand(batch_size, num_heads, max_sequence_len, embed_dimension, device=device, dtype=dtype)
value = torch.rand(batch_size, num_heads, max_sequence_len, embed_dimension, device=device, dtype=dtype)
# 定义一个计时器:
def torch_timer(f, *args, **kwargs):
t0 = benchmark.Timer(
stmt="f(*args, **kwargs)", globals={"args": args, "kwargs": kwargs, "f": f}
)
return t0.blocked_autorange().mean * 1e6
# torch.backends.cuda中也实现了,这里拿出了为了好理解backend_map是啥
class SDPBackend(IntEnum):
r"""
Enum class for the scaled dot product attention backends.
"""
ERROR = -1
MATH = 0
FLASH_ATTENTION = 1
EFFICIENT_ATTENTION = 2
# 使用上下文管理器context manager来
# 其他三种方案,字典映射
backend_map = {
SDPBackend.MATH: {
"enable_math": True,
"enable_flash": False,
"enable_mem_efficient": False},
SDPBackend.FLASH_ATTENTION: {
"enable_math": False,
"enable_flash": True,
"enable_mem_efficient": False},
SDPBackend.EFFICIENT_ATTENTION: {
"enable_math": False,
"enable_flash": False,
"enable_mem_efficient": True}
}
# 基本版,不指定
print(f"基本对照方案 运行时间: {torch_timer(F.scaled_dot_product_attention, query, key, value):.3f} microseconds")
# 基本对照方案 运行时间: 17542.618 microseconds
with sdp_kernel(**backend_map[SDPBackend.MATH]):
print(f"math 运行时间: {torch_timer(F.scaled_dot_product_attention, query, key, value):.3f} microseconds")
# math 运行时间: 18869.076 microseconds
with sdp_kernel(**backend_map[SDPBackend.FLASH_ATTENTION]):
try:
print(f"flash attention 运行时间: {torch_timer(F.scaled_dot_product_attention, query, key, value):.3f} microseconds")
except RuntimeError:
print("FlashAttention is not supported")
# flash attention 运行时间: 42313.492 microseconds
with sdp_kernel(**backend_map[SDPBackend.EFFICIENT_ATTENTION]):
try:
print(f"Memory efficient 运行时间: {torch_timer(F.scaled_dot_product_attention, query, key, value):.3f} microseconds")
except RuntimeError:
print("EfficientAttention is not supported")
# Memory efficient 运行时间: 42347.333 microseconds
因果自注意力
nanoGPT
中使用了因果自注意力,就是如果我们Pytorch版本>=2.0,torch.nn.functional有 scaled_dot_product_attention 的功能,那么我们就使用它。
接下来,我利用了 scaled_dot_product_attention 和 torch.compile(model) 做一个性能试验。
这个是 CausalSelfAttention 模块的代码:
class CausalSelfAttention(nn.Module):
def __init__(self, num_heads: int, embed_dimension: int, bias: bool=False, dropout:float=0.0):
super().__init__()
assert embed_dimension % num_heads == 0
# key, query, value projections for all heads, but in a batch
self.c_attn = nn.Linear(embed_dimension, 3 * embed_dimension, bias=bias)
# output projection
self.c_proj = nn.Linear(embed_dimension, embed_dimension, bias=bias)
# regularization
self.attn_dropout = nn.Dropout(dropout)
self.resid_dropout = nn.Dropout(dropout)
self.num_heads = num_heads
self.embed_dimension = embed_dimension
self.dropout = dropout
# flash attention make GPU go brrrrr but support is only in PyTorch >= 2.0
self.flash = hasattr(torch.nn.functional, 'scaled_dot_product_attention')
if not self.flash:
print("WARNING: using slow attention. Flash Attention requires PyTorch >= 2.0")
# causal mask to ensure that attention is only applied to the left in the input sequence
self.register_buffer("bias", torch.tril(torch.ones(block_size, block_size))
.view(1, 1, block_size, block_size))
def forward(self, x):
B, T, C = x.size() # batch size, sequence length, embedding dimensionality (embed_dimension)
# calculate query, key, values for all heads in batch and move head forward to be the batch dim
q, k ,v = self.c_attn(x).split(self.embed_dimension, dim=2)
k = k.view(B, T, self.num_heads, C // self.num_heads).transpose(1, 2) # (B, nh, T, hs)
q = q.view(B, T, self.num_heads, C // self.num_heads).transpose(1, 2) # (B, nh, T, hs)
v = v.view(B, T, self.num_heads, C // self.num_heads).transpose(1, 2) # (B, nh, T, hs)
# causal self-attention; Self-attend: (B, nh, T, hs) x (B, nh, hs, T) -> (B, nh, T, T)
if self.flash:
# efficient attention using Flash Attention CUDA kernels
y = F.scaled_dot_product_attention(q, k, v, attn_mask=None, dropout_p=self.dropout, is_causal=True)
else:
# manual implementation of attention
att = (q @ k.transpose(-2, -1)) * (1.0 / math.sqrt(k.size(-1)))
att = att.masked_fill(self.bias[:,:,:T,:T] == 0, float('-inf'))
att = F.softmax(att, dim=-1)
att = self.attn_dropout(att)
y = att @ v # (B, nh, T, T) x (B, nh, T, hs) -> (B, nh, T, hs)
y = y.transpose(1, 2).contiguous().view(B, T, C) # re-assemble all head outputs side by side
# output projection
y = self.resid_dropout(self.c_proj(y))
return y
其他部分的代码:
import torch
import torch.nn as nn
import torch.nn.functional as F
from rich import print
import torch.utils.benchmark as benchmark
import math
# Windows和Linux上使用GPU
# device = "cuda" if torch.cuda.is_available() else "cpu"
# Mac 上使用 GPU加速:
# device = torch.device("mps")
device = "mps" if torch.backends.mps.is_built() else "cpu"
# 设置超参数:
batch_size = 32
max_sequence_len = 128
num_heads = 8
heads_per_dim = 64
embed_dimension = num_heads * heads_per_dim
block_size = 1024
dtype = torch.float16
# 定义计时器:
def torch_timer(f, *args, **kwargs):
t0 = benchmark.Timer(
stmt="f(*args, **kwargs)", globals={"args": args, "kwargs": kwargs, "f": f}
)
return t0.blocked_autorange().mean * 1e6
# 实例化我们上面的 CausalSelfAttention 类
model = CausalSelfAttention(num_heads=num_heads,
embed_dimension=embed_dimension,
bias=False,
dropout=0.1).to("mps").to(dtype).eval() # mps / cuda
print(model)
# 模拟数据
x = torch.rand(batch_size,
max_sequence_len,
embed_dimension,
device=device,
dtype=dtype)
print(f"原始model 运行时间: {torch_timer(model, x):.3f} microseconds")
# 原始model 运行时间: 9169.492 microseconds
# 编译模型
torch._dynamo.config.suppress_errors = True
torch._dynamo.config.verbose=True
compiled_model = torch.compile(model)
compiled_model(x)
print(f"compiled model 运行时间: {torch_timer(compiled_model, x):.3f} microseconds")
# compiled model 运行时间: 6786.322 microseconds
CausalSelfAttention 结构参数:

从打印的结果可以看出,torch.compile(model)加速了很多,提高了25%呢!
本次的分享就到这里了,Pytorch 2.x版本的新性能还是让人很兴奋的!能提升大模型训练和推理速度、占用更少算力资源!
本文首发于公众号:美熙科技说 ID:meixi_tech


















 2007
2007

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











