







Python字符串处理与数据类型操作
1. 数字类型
十六进制数、八进制数和二进制数分别以下面的方式表示:
#二进制#
>>> 0b10
2
>>> 0b11
3
>>> 0b1101
13
#八进制#
>>> 0o10
8
>>> 0o11
9
>>> 0o1101
577
#十六进制#
>>> 0x10
16
>>> 0x11
17
>>> 0x1101
4353
#十进制#
>>> 10
10
>>> 11
11
>>> 1101
1101
二进制、八进制、十六进制、十进制互相转换的方法:
#其他进制转换二进制#
>>> bin(2) #十进制转换二进制#
'0b10'
>>> bin(0o10) #八进制转换二进制#
'0b1000'
>>> bin(0xf) #十六进制转换二进制#
'0b1111'
#其他进制转换为八进制#
>>> oct(0b101)
'0o5'
>>> oct(0xf)
'0o17'
>>> oct(0o123)
'0o123'
#其他进制转换为十六进制#
>>> hex(0o10)
'0x8'
>>> hex(3)
'0x3'
>>> hex(0b111)
'0x7'
#其他进制转换为十进制#
>>> int(0o10)
8
>>> int(0xf)
15
>>> int(0b10)
2
2. 字符串
回顾第一个代码:
print("Hello, world!")
编程教程通常以类似的程序开篇,问题是我还未全面阐述其工作原理。你已掌握了 print 语句的基本知识
(后面将更详细地介绍它),但 "Hello, world!" 是什么呢?这是一个字符串(string)。几乎所有真实的Python
程序中都有字符串的身影。字符串用途众多,但主要用途是表示一段文本,如感叹句“Hello, world!”。
2.1 单引号字符串以及对引号转义
与数一样,字符串也是值:
>>> "Hello, world!"
'Hello, world!'
在这个示例中,有一点可能让你颇感意外:Python在打印字符串时,用单引号将其括起,而我们使用的是双引号。
这有什么差别吗?其实没有任何差别。
>>> 'Hello, world!'
'Hello, world!'
这里使用的是单引号,结果却完全相同。既然如此,为何同时支持单引号和双引号呢?因为在有些情况下,这可能会有用。
>>> "Let's go!"
"Let's go!"
>>> '"Hello, world!" she said'
'"Hello, world!" she said'
在上述代码中,第一个字符串包含一个单引号(就这里而言,可能称之为撇号更合适),因此不能用单引号将整个
字符串括起,否则解释器将报错(做出这样的反应是正确的)。
>>> 'Let's go!'
SyntaxError: invalid syntax
在这里,字符串为 'Let' ,因此Python不知道如何处理后面的 s (更准确地说是当前行余下的内容)。第二个
字符串包含双引号,因此必须使用单引号将整个字符串括起,原因和前面一样。实际上,并非必须这样做(这样做
只是出于方便考虑)。可使用反斜杠( \ )对引号进行转义,如下所示:
>>> 'Let\'s go!'
"Let's go!"
这样Python将明白中间的引号是字符串的一部分,而不是字符串结束的标志。虽然如此,Python打印这个字符串时还是
使用了双引号将其括起。与你预期的一样,对于双引号可采用同样的处理手法。
>>> "\"Hello, world!\" she said"
'"Hello, world!" she said'
像这样对引号进行转义很有用,且在有些情况下必须这样做。例如,在字符串同时包含单引号和双引号
(如 'Let\'s say "Hello, world!"' )时,如果不使用反斜杠进行转义,该如何办呢?
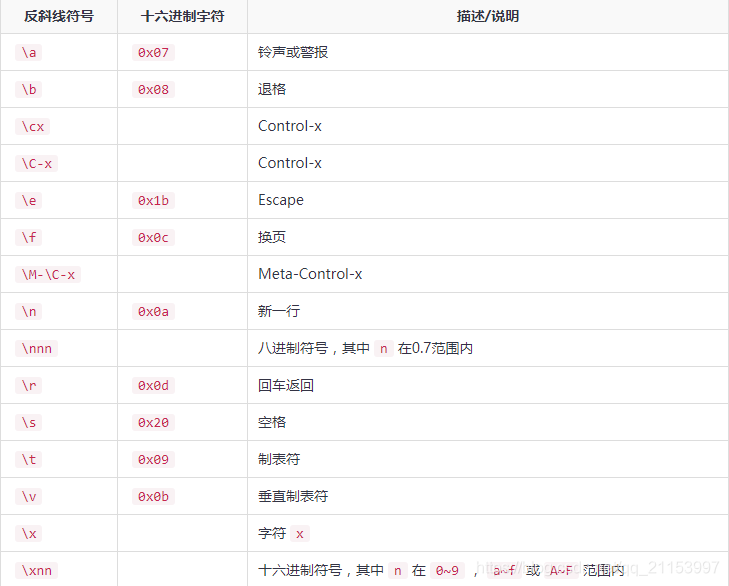
下表是可以用反斜杠表示法表示转义或不可打印字符的列表。单引号以及双引号字符串的转义字符被解析。
2.2 拼接字符串
为处理前述不太正常的示例,来看另一种表示这个字符串的方式:
>>> "Let's say " '"Hello, world!"'
'Let\'s say "Hello, world!"'
我依次输入了两个字符串,而Python自动将它们拼接起来了(合并为一个字符串)。这种机制用得不多,但有时候很有用。
然而,仅当你同时依次输入两个字符串时,这种机制才管用。
>>> x = "Hello, "
>>> y = "world!"
>>> x y
SyntaxError: invalid syntax
换而言之,这是一种输入字符串的特殊方式,而非通用的字符串拼接方法。那么应该如何拼接字符串呢?就像将数相加一样,
将它们相加:
>>> "Hello, " + "world!"
'Hello, world!'
>>> x = "Hello, "
>>> y = "world!"
>>> x + y
'Hello, world!'
2.3 字符串表示 str 和 repr
Python打印所有的字符串时,都用引号将其括起。你可能通过前面的示例发现了这一点。这是因为Python打印值时,
保留其在代码中的样子,而不是你希望用户看到的样子。但如果你使用print ,结果将不同。
>>> "Hello, world!"
'Hello, world!'
>>> print("Hello, world!")
Hello, world!
如果再加上表示换行符的编码 \n ,差别将更明显。
>>> "Hello,\nworld!"
'Hello,\nworld!'
>>> print("Hello,\nworld!")
Hello,
world!
通过两种不同的机制将值转换成了字符串。你可通过使用函数 str 和 repr直接使用这两种机制。使用 str 能以合理
的方式将值转换为用户能够看懂的字符串。例如,尽可能将特殊字符编码转换为相应的字符。然而,使用 repr 时,通常
会获得值的合法Python表达式表示。
>>> print(repr("Hello,\nworld!"))
'Hello,\nworld!'
>>> print(str("Hello,\nworld!"))
Hello,
world!
2.4 长字符串、原始字符串和字节
有一些独特而有用的字符串表示方式。例如,有一种独特的语法可用于表示包含换行符或反斜杠的字符串(长字符串和
原始字符串)。对于包含特殊符号的字符串,Python 2还提供了一种专用的表示语法,结果为Unicode字符串。这种语法
现在依然管用,但是多余,因为在Python 3中,所有的字符串都是Unicode字符串。Python 3还引入了一种新语法,用于
表示大致相当于老式字符串的字节对象。你将看到,在处理Unicode编码方面,这种对象依然扮演着重要的角色。
1. 长字符串
要表示很长的字符串(跨越多行的字符串),可使用三引号(而不是普通引号)。
print('''This is a very long string. It continues here.
And it's not over yet. "Hello, world!"
Still here.''')
还可使用三个双引号,如 """like this""" 。请注意,这让解释器能够识别表示字符串开始和结束位置的引号,因此字符串
本身可包含单引号和双引号,无需使用反斜杠进行转义。
常规字符串也可横跨多行。只要在行尾加上反斜杠,反斜杠和换行符将被转义,即被忽略。例如,如果编写如下代码:
print("Hello, \ world!")
它将打印 Hello, world! 。这种处理手法也适用于表达式和语句。
>>> 1 + 2 + \
4 + 5
12
>>> print \
('Hello, world')
Hello, world
2. 原始字符串
原始字符串不以特殊方式处理反斜杠,因此在有些情况下很有用。在常规字符串中,反斜杠扮演着特殊角色:它对字符进行
转义,让你能够在字符串中包含原本无法包含的字符。例如,
你已经看到可使用 \n 表示换行符,从而像下面这样在字符串中包含换行符:
>>> print('Hello,\nworld!')
Hello,
world!
这通常挺好,但在有些情况下,并非你想要的结果。如果你要在字符串中包含 \n 呢?例如,
你可能要在字符串中包含DOS路径C:\nowhere。
>>> path = 'C:\nowhere'
>>> path
'C:\nowhere'
这并非你想要的结果,不是吗?那该怎么办呢?可对反斜杠本身进行转义。
>>> print('C:\\nowhere')
C:\nowhere
这很好,但对于很长的路径,将需要使用大量的反斜杠。
path = 'C:\\Program Files\\fnord\\foo\\bar\\baz\\frozz\\bozz'
3. Unicode、 bytes 和 bytearray
Python字符串使用Unicode编码来表示文本。对大多数简单程序来说,这一点是完全透明的,因此如果你愿意,可跳过
本节,需要时再学习这个主题。然而,鉴于处理字符串和文本文件的Python代码很多,大致浏览一下本节至少不会有什么坏处。
大致而言,每个Unicode字符都用一个码点(code point)表示,而码点是Unicode标准给每个字符指定的数字。这让你能够
以任何现代软件都能识别的方式表示129个文字系统中的12万个以上的字符。当然,鉴于计算机键盘不可能包含几十万个键,
因此有一种指定Unicode字符的通用机制:使用16或32位的十六进制字面量(分别加上前缀 \u 或 \U )或者使用字符的
Unicode名称( \N{ name } )。
>>> "\u00C6"
'Æ'
>>> "\U0001F60A"
'?'
>>> "This is a cat: \N{Cat}"
'This is a cat: ?'
要获悉字符的Unicode码点和名称,可在网上使用有关该字符的描述进行搜索,也可参阅特定的网站,如
http://unicode-table.com。Unicode的理念很简单,却带来了一些挑战,其中之一是编码问题。在内存和磁盘中,所有对象
都是以二进制数字(0和1)表示的(这些数字每8个为一组,即1字节),字符串也不例外。在诸如C等编程语言中,这些字节完
全暴露,而字符串不过是字节序列而已。为与C语言互操作以及将文本写入文件或通过网络套接字发送出去,Python提供了两种
类似的类型:不可变的 bytes和可变的 bytearray 。如果需要,可直接创建 bytes 对象(而不是字符串),方法是使用前缀
b :
>>> b'Hello, world!'
b'Hello, world!'
bytearray ,它是 bytes 的可变版。从某种意义上说,它就像是可修改的字符串——常规字符串是不能修改的。然而,
bytearray 其实是为在幕后使用而设计的,因此作为类字符串使用时对用户并不友好。例如,要替换其中的字符,必须将其
指定为0~255的值。因此,要插入字符,必须使用 ord 获取其序数值(ordinal value)。
>>> x = bytearray(b"Hello!")
>>> x[1] = ord(b"u")
>>> x
bytearray(b'Hullo!')
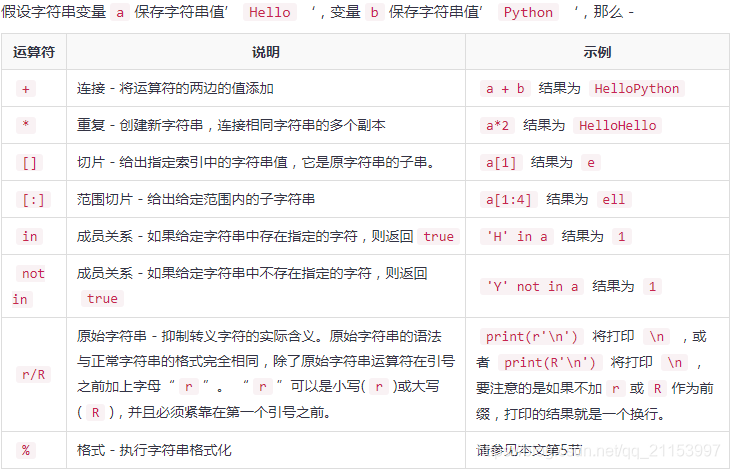
2.5 字符串特殊运算符
2.6 字符串格式化运算符
Python最酷的功能之一是字符串格式运算符%。 这个操作符对于字符串是独一无二的,弥补了C语言中 printf()系列函数。
以下是一个简单的例子 -
#!/usr/bin/python3
print ("My name is %s and weight is %d kg!" % ('Maxsu', 71))
Python
当执行上述代码时,会产生以下结果 -
My name is Maxsu and weight is 71 kg!
Shell
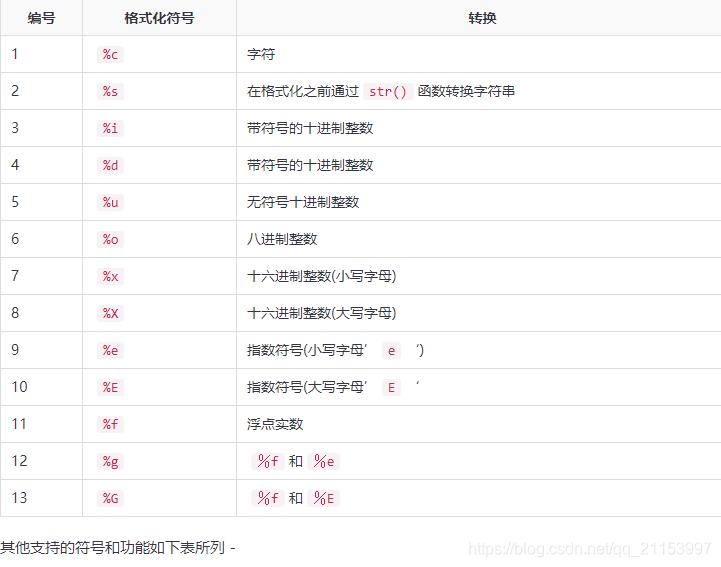
以下是可以与%符号一起使用的完整符号集列表

2.7 Unicode字符串
在Python 3中,所有的字符串都用Unicode表示。在Python 2内部存储为8位ASCII,因此需要附加’u‘使其成为Unicode,而现在
不再需要了。内置字符串方法

















 92
92











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









