







 字符编码是网络数据传输的基础,从ASCII的单字节表示,到GBK、Unicode的多字节表示,再到UTF-8的变长编码。网络通信中,统一的字符编码至关重要,否则可能导致乱码。例如,UTF-8编码兼容ASCII且节省空间,适用于多语言环境,而GBK编码则主要用于中文。当发送方和接收方编码不一致时,会出现乱码问题。理解字符编码有助于解决网络通信中的字符显示问题。
字符编码是网络数据传输的基础,从ASCII的单字节表示,到GBK、Unicode的多字节表示,再到UTF-8的变长编码。网络通信中,统一的字符编码至关重要,否则可能导致乱码。例如,UTF-8编码兼容ASCII且节省空间,适用于多语言环境,而GBK编码则主要用于中文。当发送方和接收方编码不一致时,会出现乱码问题。理解字符编码有助于解决网络通信中的字符显示问题。
为什么我们在网络中传输数据,需要指定字符编码,例如使用UTF-8、GBK等编码。那么字符编码到底是什么?以前我也很困惑这个问题,但是学习了计算机网络后我们知道,由于底层电路的设计本质,只能是识别0和1两种代码,那么传递的也只能是0和1了。
前面的文章数据包传输、学习路由器、交互机的时候就讲了数据包传输的本质是0和1。
计算机网络-网络包介绍以及网络包如何通过互联网传输
既然计算机只能识别0和1,那怎么才能把0和1转成我们的中文、英语等各种字符语言呢?
首先复习一下基础知识-字节
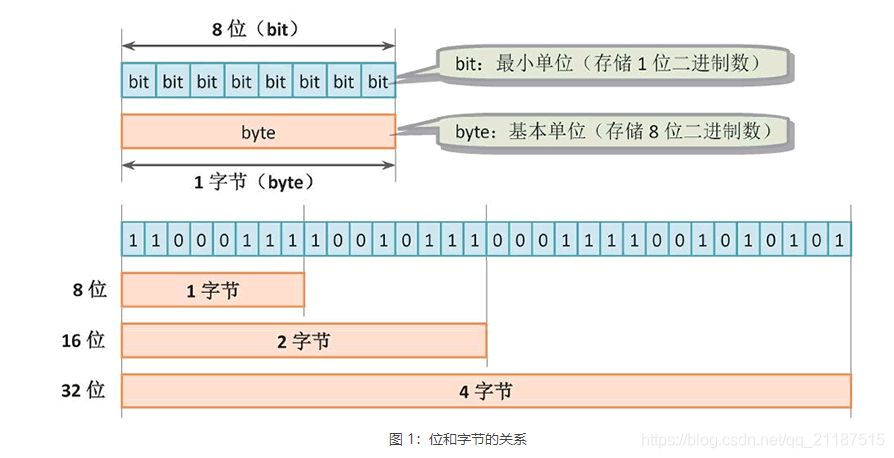
- 计算机内部数据的最小单位是位(bit),我们用二进制数 0 或 1 来表示,即一个bit不是0就是1。
- 在计算机中,把 8 位聚在一起的二进制数称为一个字节(byte),即 1 字节(byte)= 8 位(bit)。
- 字节是计算机中表示数据大小的基本单位。通常字节(byte)用大写字母 B 表示,位(bit)用小写字母 b 表示。
例如:16 位二进制数就是 2 字节(2B),32 位二进制数就是 4 字节(4B)(见图 1)。
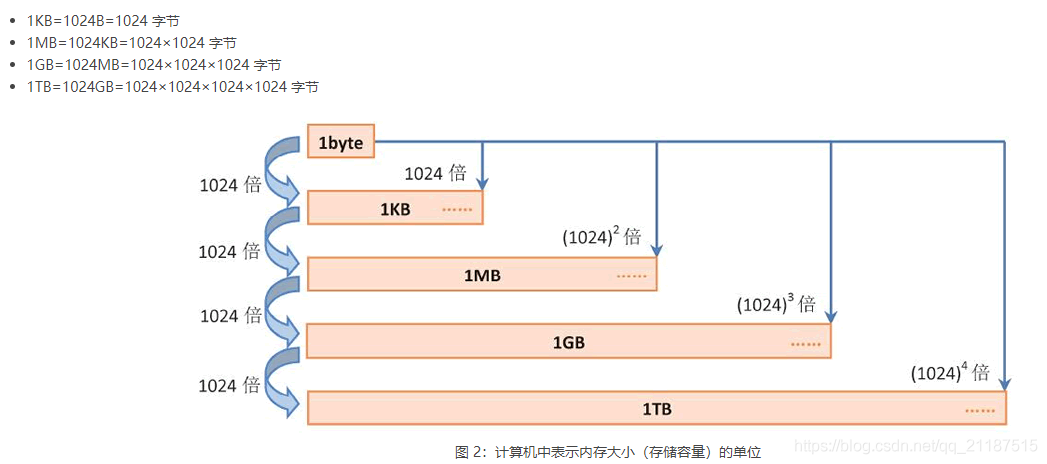
单位转算:
1B(Byte)=8b(bit)
1KB=1024B
1MB=1024KB
1GB=1024MB
综上所述,一个字节就是有8位,即有8个0或1组成的数字顺序就叫一个字节。字节是计算机中表示数据大小的基本单位。 8位转成十进制,即2的8次方(2222222*2)=256,第一个是0开始,所以就一个字节可以表示0-255的数字范围
注:可能有小伙伴有疑问,为什么是8位表示一个字节,10位不行吗?8位是只是目前世界约定好的单位,就像尺子一厘米有多长,为什么是这么长。因为在设计的时候大家约定好就是这样。当然8位也有由来,是跟ASCII编码有关的,8位满足所有ASCII编码的字符对应,有兴趣再查查资料。
再回顾一下网络中的数据包
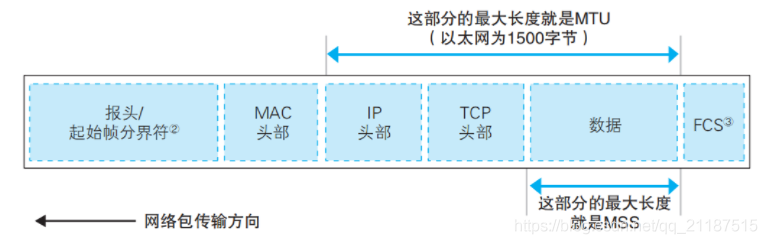
如图,我们数据包的IP头部+TCP头部+数据块,一共有1500个字节,即这一块转成0和1就有1500*8=12000个表示0或1的数字。把这么多0或1的数字通过网络传输到其他计算机上,那么其他计算机接收后,然后传递给应用程序,最后应用程序如何知道这些0和1表示什么意思呢?
字符编码的由来
就是我们需要建立一张映射表,把数字映射出相应的字符信息。我们把获取到的字节表示的数字,根据这个映射表,把数字转成字符。
| 字典编码 | 字典名称 |
|---|---|
| 0 | 否 |
| 1 | 是 |
按我开发程序的角度,这就像我们写成程序时候的字典,例如我们有一个这样的字典:0-否,1-是,我们数据库保存的是字典编码,我们把数字拿到字典中匹对一下,就知道这个数字是什么意思了。
ASCII编码
ASCII编码就是这样的一个映射表,我们先看看ASCII编码的字符集是怎么样的?
字符集就是该字符编码的所有能表示的字符的集合
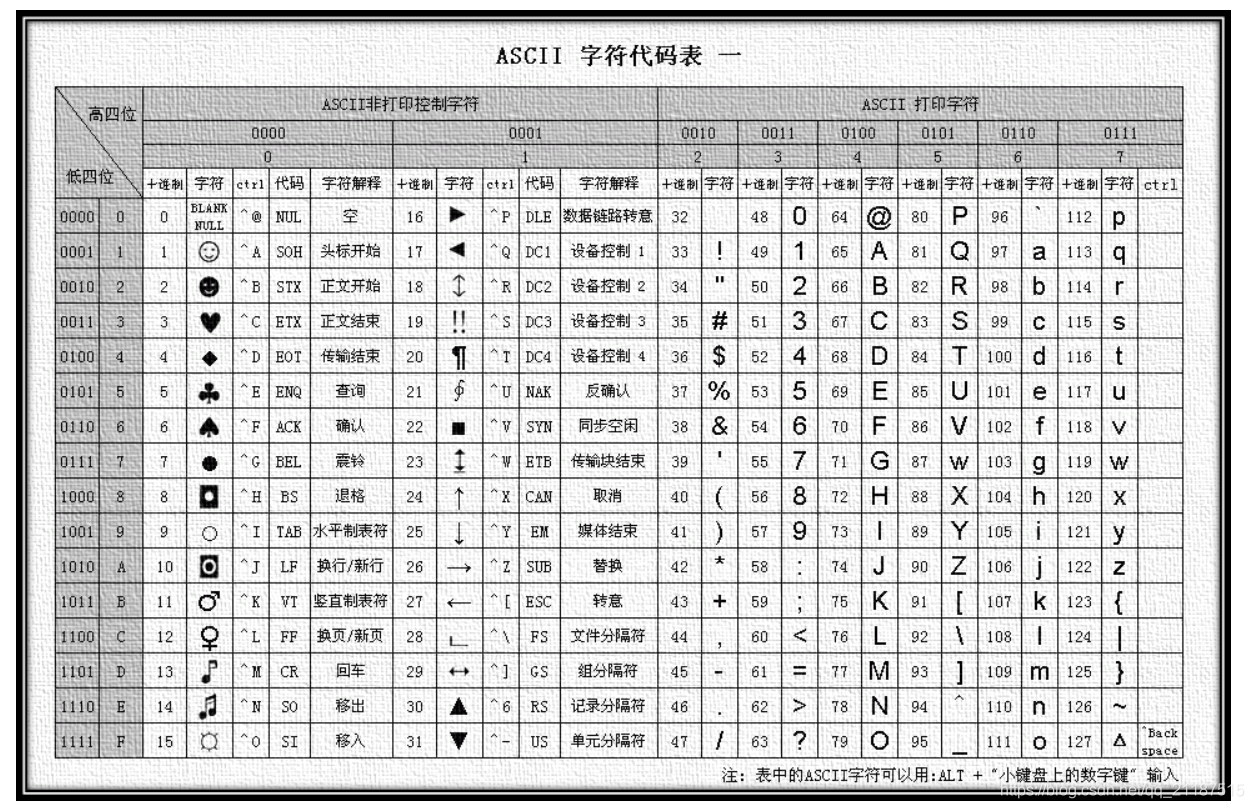
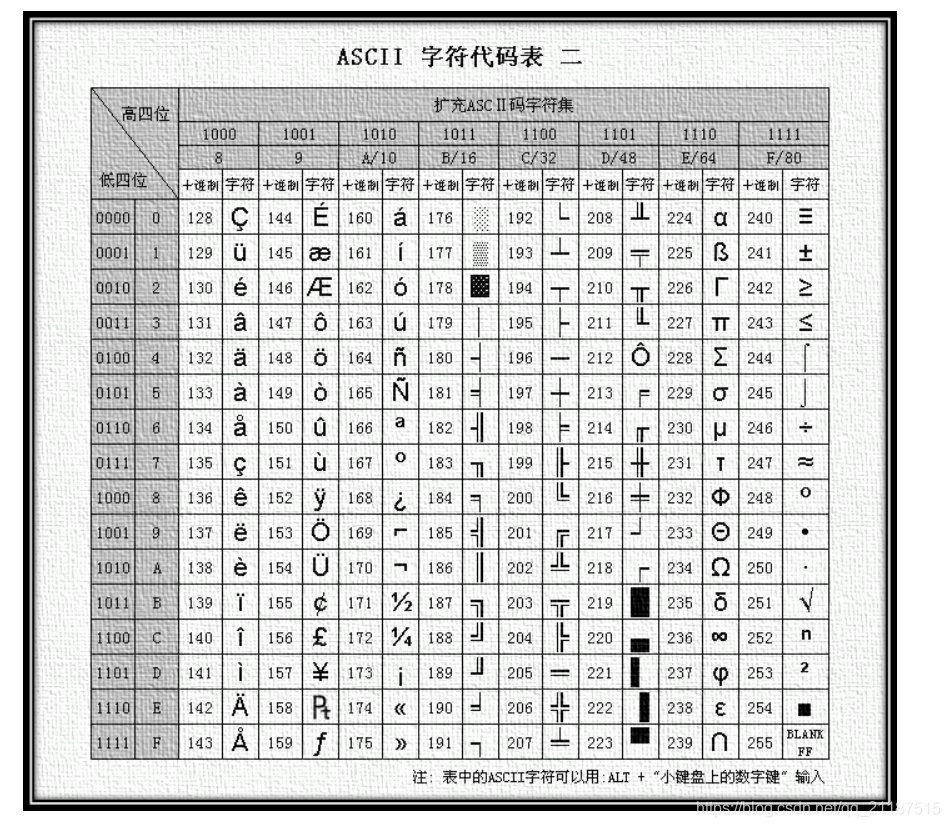
可以看到,在这个ASCII编码的字符集里面,0到255,每个数字表示一个字符。刚好一个字节就可以表示一个字符
ASCII编码的字符集里面,一个字符表示一个字节
这也就是为什么一个字节是8位的由来,美国设计的时候8位就可以在ASCII编码中映射所有英文的字符了,毕竟因为字符也就是26个字母,加上数字和符号,8位可以表示256个数字,就足够了
就是这样的字符编码规则,将字符与二进制对应上了,当你收到了这样的二进制,你根据这个编码规则反过来就知道收到了哪些的字符。
例如,我们收到一个字节为:0100 0001,我们转成10进制就是61,那么我们根据上面的ASCII的字符集编码表查找,61表示的就是A的意思
这就是字符编码的由来,因为计算机只能表示0和1,所以我们需要发送方和接收方都是用同一套字符编码来解析接收到的0和1表示的意思,否则接收到的0和1就没有意义了。
发送方和接收方都需要指定相同的字符集编码,例如ASCII、utf-8或gbk2312等等字符编码
我再来两个我们常见的举例
一个很有意思的微信加密聊天
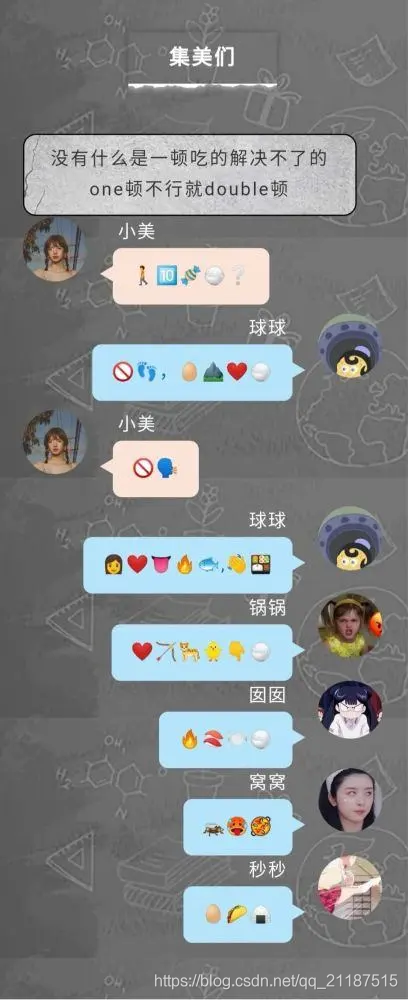
这里大家发的都是一些表情,别人怎么知道是什么意思呢?这就需要发送的人和接收的人都有同一个解析的表情对应表,即我们上面说的字符编码。其他人看到,但是他没有这个字符集编码,那他就不能解析这里面的内容是什么。(当然也可以靠我们的聪明才智去破译)
电报机的通讯
例如我们看抗日战争剧,经常看到用电报机通讯,电报机在滴滴答答的响,也经常看到破译了对方的电报内容的场景,还有密码本被盗的场景。电报机是怎么通讯的?其实电报机就是利用电流发送电磁波,对方监听的波长与发报波长一致即可收到。电报收下来一般都是数码例如一份报是1234 2234 3234,接收方收到了这些数字,怎么知道是什么意思呢?这时候接收方会那出密码本,查询一下每个数字对应的字符,然后再把这些字符拼接起来,就能还原出原来通讯的内容了。
这里的密码本也是上面说的字符集编码
还有为什么能经常看到说破译了对方的报文?如何破译?就是发送方发送的电磁波,监听的波长与发报波长一致即可收到,即敌我双方都能接收到,但是别人没有密码本,解析不出来报文的内容,但是可以分析多个报文(就像大数据一样),看看哪些多次出现的数字,再合理分析可能表达的意思。最后就有可能分析出一些有用内容。
好像扯远了,上面的举例主要是想形象说明网络中的通讯,为什么需要字符集编码,字符集编码的由来。就是要把接收到的0和1表示的数字转成对应的字符信息。
为什么会乱码
大家是否看到过类似这样的乱码"“бЇЯАзЪСЯ”、“�???”?" ,为什么前端传输过来的数据,后端接收后会显示乱码?或者为什么后端的数据,保存到数据库后乱码?
通过上面的内容我们可以知道,网络传输的基本单位是字节,字节是0和1的数据,我们把接收到的数据要根据字符集编码来解析内容。但是如果客户端发送用的是utf-8编码,但是我们服务器接收用的是iso-8859-1来解码,这个时候在utf-8编码里面对应数字表达的字符但在iso-8859-1的字符集里面找到的不一样或者没找到,那么服务器解析出来的内容就会乱码
UTF-8收编的汉字一般占3个字节,严格地用iso8859-1无法表示汉字,只能转为问号
如果发送方用的是ASCII编码,我们用UTF-8来解析也没问题,为什么呢?因为UTF-8编码兼容了ASCII编码,即ASCII编码表内容在UTF-8编码表里面是一样的,但是UTF-8可以展示更多内容。集合关系:UTF-8包含ASCII
常见的乱码场景
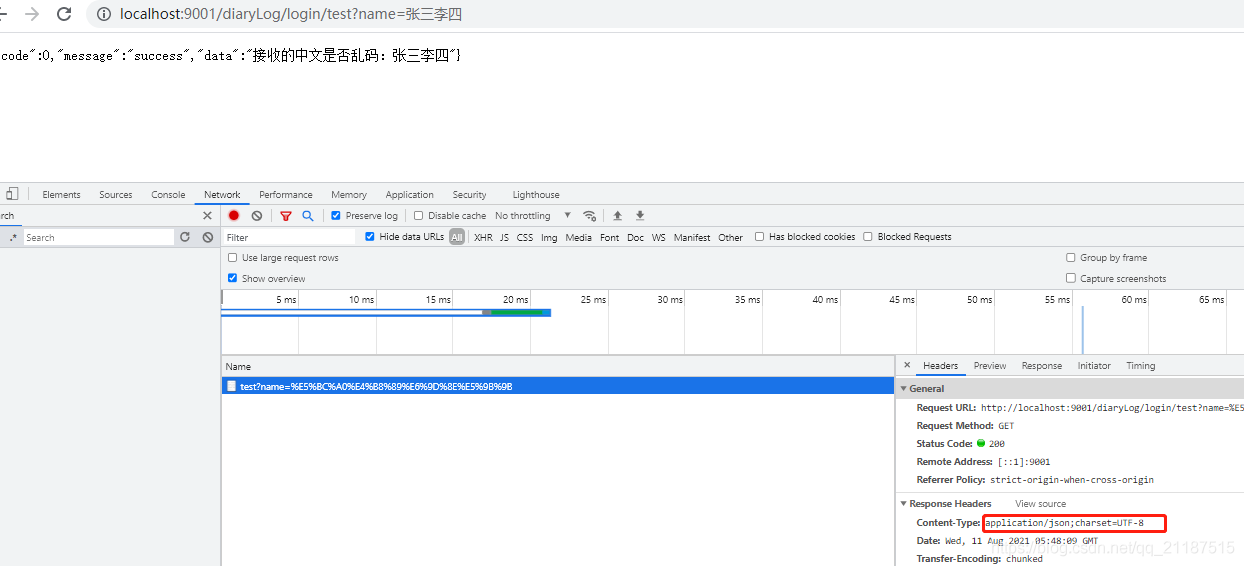
例如开发过程遇到的get请求时候参数中含有“中文”时,传到后端接收中文就会乱码。为什么乱码?遇到乱码的场景不要慌,先分析原因,必定是因为客户端发送的编码和后端服务器接收的编码不一致导致的。
例如我们GET请求前端用了UTF-8编码,有些服务器(例如tomcat)按照默认的iso-8859-1进行解码,这时候就有中文乱码。
这种场景的解决方案:最简单的是统一编码,服务端将解码格式直接配置为utf-8(修改tomcat服务器上的编码)
我们写一个接口验证看看,可以看到只要客户端和服务器字符编码一致,get请求带中文入参也不会乱码

ASCII、Unicode、GBK和UTF-8字符编码的由来
ASCII编码是美国设计,但是他们可能没想到还有亚洲国家也会有一天用上计算机,ASCII编码没有我们的中文汉字对应的字符。而且ASCII编码一个字符一个字节,最大映射的字符数就是256个。而我们的汉字的数量大约将近十万个,常用汉字也有好几千字。
所以等中国人们得到计算机时,已经没有可以利用的字节状态来表示汉字,况且有6000多个常用汉字需要保存呢,于是我们建了一个自己的字符集编码,一个字节不够对应我们的汉字,所以我们用了两个字节表示一个汉字字符,发明了GB2312这些汉字编码。这样我们就可以组合出大约7000多个简体汉字了。
GBK2312:一个小于127的数字的意义与原来ASCII字符相同,但两个大于127的字符连在一起时,就表示一个汉字;
原来在127号以下的那些就叫“半角”字符了。大于127以上叫“全角”字符
一个字节数字低于127的则和ASCII一样,两个大于127的则表示中文以及其他字符。所以在GBK2312中,英文是一个字节,中文是两个字节,
GB2312 是对 ASCII 的中文扩展。兼容ASCII编码127以下的字符
这样的话,各个国家都有一套自己的字符编码规则,所以一个国际组织决定着手解决这个问题,为了统一全球国家的字符集编码,制定了Unicode编码。但是Unicode编码全部使用双字节或使用最长的字节,即如果传一个中文是两个字节,传英文也是两个字节(但是英文本来一个字节就可以了,第二个高字节全是0),就会造成空间浪费。
在Unicode中,一个字符就是两个字节,只有Unicode编码时所有字符才一视同仁。
再后来就出现了UTF-8来实现unicode编码,UTF-8是可变字节的编码。
UTF-8就是在互联网上使用最广的一种unicode的实现方式,这是为传输而设计的编码,并使编码无国界,这样就可以显示全世界上所有文化的字符了。
UTF-8最大的一个特点,就是它是一种变长的编码方式。
它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度,当字符在ASCII码的范围时,就用一个字节表示,保留了ASCII字符一个字节的编码做为它的一部分,(注意的是unicode一个中文字符占2个字节,而UTF-8一个中文字符一般占3个字节)。
为什么UTF-8的中文字符是一般三个字节?还有可能其他情况吗?有,实际上可能有四个字节。
UTF-8编码是变长的,1—6个字节。其中汉字编码,是3个或4个字节。查一下UTF-8字符映射表,就可以看到以下结果:占用3个字节的范围,合计: 52156 个,占用4个字节的范围共 64029 个。所以会有不常用的中文汉字是四个字节的。
ASCII、Unicode、GBK和UTF-8字符编码区别
- ASCII:一个字符一个字节
- GBK2312:127一下的表示一个字节,两个大于127的字节表示中文汉字(即一个英文一个字节,一个中文两个字节)
- Unicode:所有字符都是双字节
- UTF-8:可变长字节,兼容ASCII,根据字符在UTF-8字符集的位置,可用一到多个字节表示,一个英文一个字节,一个中文汉字一般三个字节
参考:
计算机中,到底什么是字符编码?
字节(Byte)是什么?
【编码】ASCII、Unicode、GBK和UTF-8字符编码的区别联系


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









