






总结如图

1.Redis的基础类型dictEntry和redisObject
2.程序员使用redis时的底层思维
3.String底层数据结构
4.Hash数据结构介绍
5.List数据结构介绍
6.Set数据结构介绍
7.ZSet数据结构介绍
1.Redis的基础类型dictEntry和redisObject
就像我们的JAVA对象,顶层全是Object一样,我们的redis的顶层都是dictEntry,让我们来看这样一段源码(dict.h中):
typedef struct dictEntry {
void *key; //表示字符串 就是redis KV结构中的KEY
union {
void *val; //val指向的是redisObject中
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next; /* Next entry in the same hash bucket. */
void *metadata[]; /* An arbitrary number of bytes (starting at a
* pointer-aligned address) of size as returned
* by dictType's dictEntryMetadataBytes(). */
} dictEntry;
我们以最简单的set k1 v1为例,因为redis是以kv为结构的数据库,每个键值对都是一个dictEntry,这里面指的是key和value的指针,next指向下一个dictEntry。
key是字符串,但是redis没有使用C的char数据,而是使用自定义的sds,value会有不同的类型,redis将这几种基本的类型抽象成了redisObject中,实际上五种常用的数据类型,都是有redisObject来存储。
我们看看redisObject的源码(server.h):
typedef struct redisObject {
unsigned type:4; //当前对象的类型
unsigned encoding:4; //当前对象的底层编码类型
unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or LRU或者LFU的访问时间数据
* LFU data (least significant 8 bits frequency
* and most significant 16 bits access time). */
int refcount; //对象引用计数的次数
void *ptr; //真正指向底层数据结构的指针
} robj;
接下来我们便可用用这张图表示,对redis的存储结构一目了然:
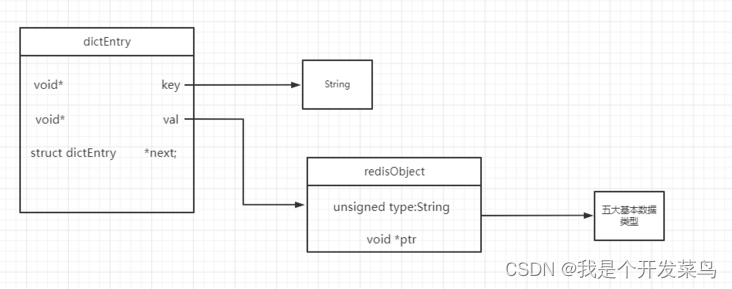
为了便于操作,Redis采用redisObject结构来抽象了不同的数据类型,这样所有的数据类型就可以用相同的形式在函数之间传递,而不是使用特定的类型结构。同时,为了识别不同的数据类型,
redisObject中定义了type和encoding字段对不同的数据类型加以区分。简单地说,redisObject就是String,hash,list,set,zset的父类,可以在函数间传递的时候隐藏具体的基本类型信息,所以作者抽象了redisObject。
程序员使用redis时的底层思维
我们刚开始学习redis的时候,只会调用调用顶层的api,所以我们看到的redis是这个样子的:
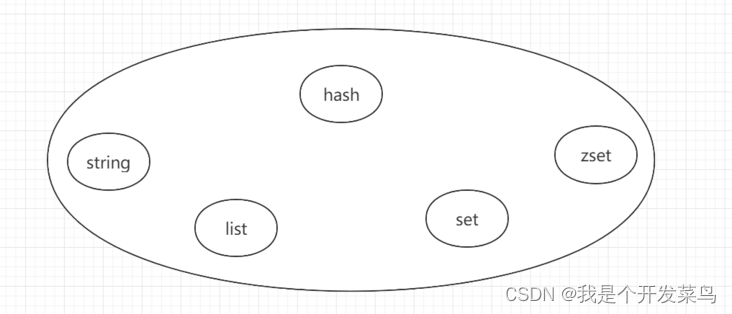
但是我们学习了redis的的底层数据结构后,我们将会看到这样子的redis:
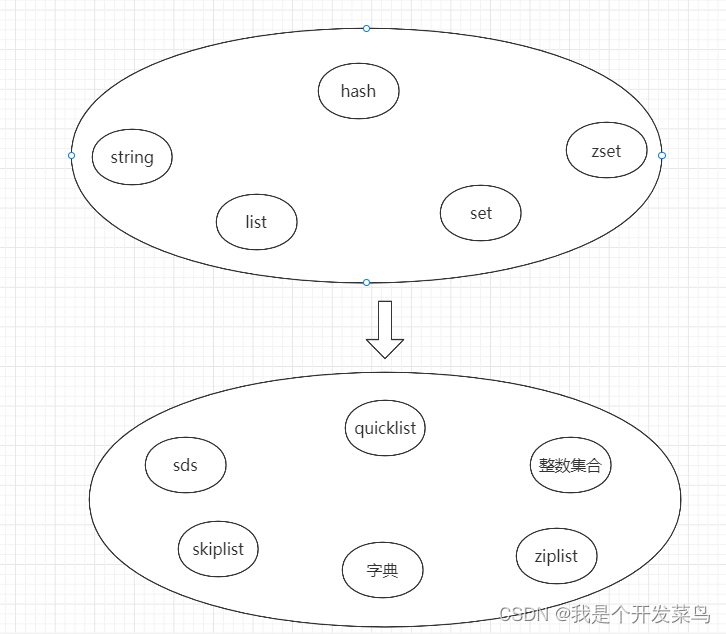
String的底层数据结构
Redis的String类型,其实底层是由三种数据结构组成的:
1)int 整数且小于二十位整数以及以下的数字数据才使用这个类型

2)embstr(嵌入式的String)代表embstr格式SDS 保存长度小于44字节的字符串。
3)raw保存长度大于44的字符串
我们先对上面这个案例做一个测试:
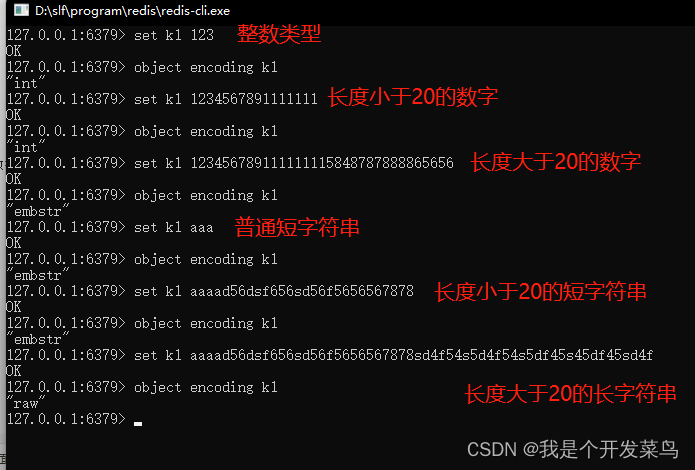
我们发现保存的数据内容,会随着保存内容的变化而发生变化。
这里是redis中,String类型都没有直接使用c语言的字符串,而是使用新建的SDS,在redis数据库中,包含字符串的键值对都是有SDS实现的。
我们点开sds.h,发现sds由多种类型构成
struct __attribute__ ((__packed__)) sdshdr5 { //被废弃
unsigned char flags; /* 3 lsb of type, and 5 msb of string length */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* used */ //已用长度
uint8_t alloc; /* excluding the header and null terminator */ //字符串最大字节长度
unsigned char flags; /* 3 lsb of type, 5 unused bits */ //用来展示的sds类型
char buf[]; //真正有效的字符串数据,长度由alloc控制
};
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 {
uint32_t len; /* used */
uint32_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr64 {
uint64_t len; /* used */
uint64_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};```
4.Hash数据结构介绍
在查看Hash的数据结构之前,我们先来看这样的一个配置:

我们可能看不太懂,我来给解释一下:
hash-max-ziplist-entries:使用压缩列表保存哈希集合中的最大元素个数。
hash-max-ziplist-value:使用压缩列表保存时哈希集合中单个元素的最大长度。
可能我们这么说还是不太懂,上案例:

Hash数据类型也和String有相似之处,到达了一定的阈值之后就会对数据结构进行升级。
数据结构:
1)hashtable 就是和java当中使用的hashtable一样,是一个数组+链表的结构。
2)ziplist 压缩链表
我们先来看一下 压缩链表的源码:

ziplist是一种比较紧凑的编码格式,设计思路是用时间换取空间,因此ziplist适用于字段个数少,且字段值也较小的场景。压缩列表内存利用率高的原因与其连续性内存特性是分不开的。
当一个hash对象,只包含少量的键,且每个键值对的值都是小数据,那么ziplist就适合做为底层实现。
ziplist的结构:
它是一个经过特殊编码的双向链表,它虽然是双向链表,但它不存储指向上一个链表节点和指向下一个链表节点的指针,而是存储上一个节点的长度和当前节点的长度,通过牺牲部分读写性能,来换取高空间利用率。

zlbytes 4字节,记录整个压缩列表占用的内存字节数。
zltail 4字节,记录压缩列表表尾节点的位置。
zllen 2字节,记录压缩列表节点个数。
zlentry 列表节点,长度不定,由内容决定。
zlend 1字节,0xFF 标记压缩的结束。
节点的结构源码:

因为保存了这个结构,可以让ziplist从后往前遍历。
为什么有链表了,redis还要整出一个压缩链表?
1)普通的双向链表会有两个前后指针,在存储数据很小的情况下,我们存储的实际数据大小可能还没有指针占用的内存大。而ziplist是一个特殊的双向链表,并没有维护前后指针这两个字段,而是存储上一个entry的长度和当前entry的长度,通过长度推算下一个元素在什么地方。牺牲读取的性能,获取高效的空间利用率,因为(简短KV键值对)存储指针比存储entry长度更费内存,这是典型的时间换空间。
2)链表是不连续的,遍历比较慢,而ziplist却可以解决这个问题,ziplist将一些必要的偏移量信息都记录在了每一个节点里,使之能跳到上一个节点或者尾节点节点。
3)头节点里有头结点同时还有一个参数len,和SDS类型类似,这就是用来记录链表长度的。因此获取链表长度时不再遍历整个链表,直接拿到len值就可以了,获取长度的时间复杂度是O(1)。
遍历过程:
通过指向表尾节点的位置指针zltail,减去节点的previous_entry_length,得到前一个节点的起始地址的指针。如此循环,从表尾节点遍历到表头节点。
5.List数据结构介绍
我们先来看一下list的默认配置:

ziplist压缩配置 :list-compress-depth 0
表示一个quicklist两端不被压缩的节点个数,这里的quicklist(下文会解释)是指quickList双向链表的节点,而不是指ziplist里面的数据项个数。
参数取值含义:
0:是个特殊值,表示都不压缩,这是redis的默认值。
1: 表示quicklist两端各有1个节点不压缩,中间的节点压缩。
2: 表示quicklist两端各有2个节点不压缩,中间的节点压缩。
3: 表示quicklist两端各有3个节点不压缩,中间的节点压缩。
依此类推…
(2) ziplist中entry配置:list-max-ziplist-size -2
当取正值的时候,表示按照数据项个数来限定每个quicklist节点上的ziplist长度。比如当这个配置为5的时候,ziplist里最多有5个数据项。
当取负值的时候,表示按照占用字节数来限定quicklist节点上的ziplist长度。这时,它只能取-1~-5这几个值。
-5: 每个quicklist节点上的ziplist大小不能超过64 Kb。(注:1kb => 1024 bytes)
-4: 每个quicklist节点上的ziplist大小不能超过32 Kb。
-3: 每个quicklist节点上的ziplist大小不能超过16 Kb。
-2: 每个quicklist节点上的ziplist大小不能超过8 Kb。(-2是Redis给出的默认值)
-1: 每个quicklist节点上的ziplist大小不能超过4 Kb。
quicklist结构介绍:
list用quicklist来存储,quicklist存储了一个双向链表,每一个节点都是一个ziplist。

!

源码:


6.Set数据结构介绍
我们来看一下set的配置:

set-max-intset-entries
set数据类型集合中,如果没有超出了这个数量,且数据元素都是整数的话,类型为intset,否则为hashtable。

intset类型:

看到源码后,我们可以得出,结论,intset的数据结构本质是一个数组。而且**存储数据的时候是有序的,因为在查找数据的时候是通过二分查找来实现的。

我们稍微分析一下set的单个元素的添加流程。
如果set已经是hashtable的编码,那么走hashtable的添加流程。
如果原来是intset:
1)能转化为int对象,就用intset保存。
2)如果长度超过设置,就用hashtable保存
3)其它情况统一用hashtable保存。
7.ZSet数据结构介绍
我们看一下ZSet的配置:

当有序集合中包含的元素数量超过服务器属性 zset_max_ziplist_entries 的值(默认值为 128 ),
或者有序集合中新添加元素的 member 的长度大于服务器属性zset_max_ziplist_value 的值(默认值为 64 )时,redis会使用跳跃表(下文会解释)作为有序集合的底层实现。
否则会使用ziplist作为有序集合的底层实现。
看一下源码:


当元素个数大于设置的个数或者元素的列表本来就是skiplist编码的时候,用skiplist存储,否则就用ziplist存储。
skiplist(跳表)是什么:
跳表是一种以空间换取时间的结构。
由于链表是无法进行二分查找的,因此借鉴了数据库索引的思想,提取出链表中关键节点(索引),现在关键节点上进行查找,再进入链表进行查找。
提取了很多关键节点,就形成了跳表。

因为跳表是以一种跳跃式的数据存在,当我们查询‘14’这个数据的时候,可以跳过很多无用的数据,减少遍历的次数。
跳表是一个典型的空间换时间的解决方案,而且只有在数据量较大的情况下才能体现出来优势。还是要读多写少的情况才适合使用,所以它的适用范围还是比较有限的,新增或者删除的时候要把所有数据都更新一遍。















 140
140











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









