







@Data
public class A {
private int id;
private String name;
}package com.example.demo2.config;
import java.util.HashMap;
import java.util.HashSet;
import java.util.Map;
import java.util.Set;
class Solution {
public static void main(String[] args) {
A a=new A();
a.setId(1);
a.setName("张三");
A b=new A();
b.setId(1);
b.setName("张三");
System.out.println(a.hashCode());
System.out.println(b.hashCode());
Set<A> set=new HashSet<A>();
set.add(a);
set.add(b);
System.out.println(set.size());
}
}使用@Data的场景
当使用了@Data这个注解,发现2个相同的对象内容,打印的hashcode竟然一样
是因为底层进行了重写hashcode和equals的方法
那么这时候插入的数据在set里面就会变成1条

我们进入set的添加源码,可以看到,set的底层是map
在hashmap的源码中,会重新计算hash值
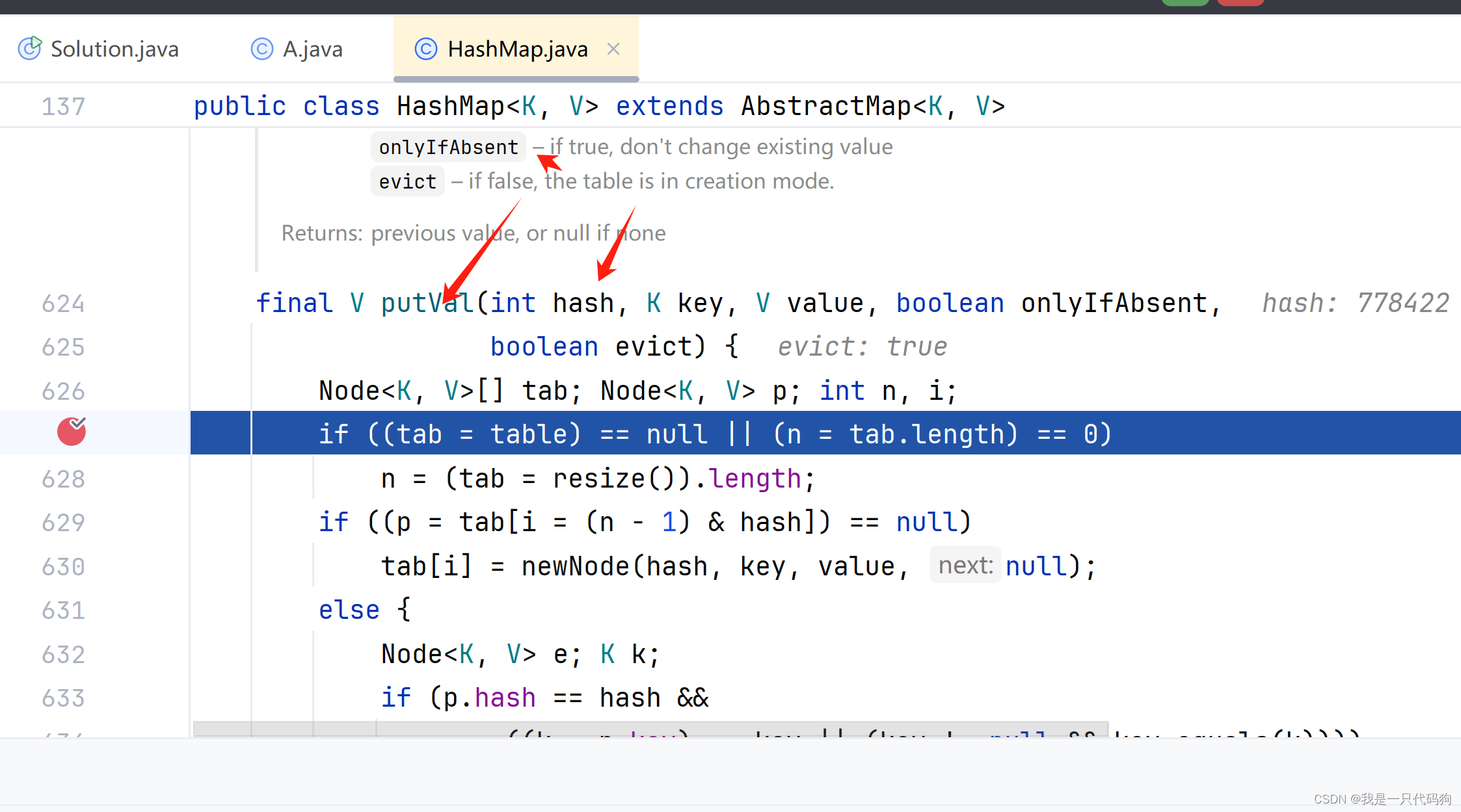
如果hash值一样,并且key一样,就是2个相同的对象内容组成了一个key
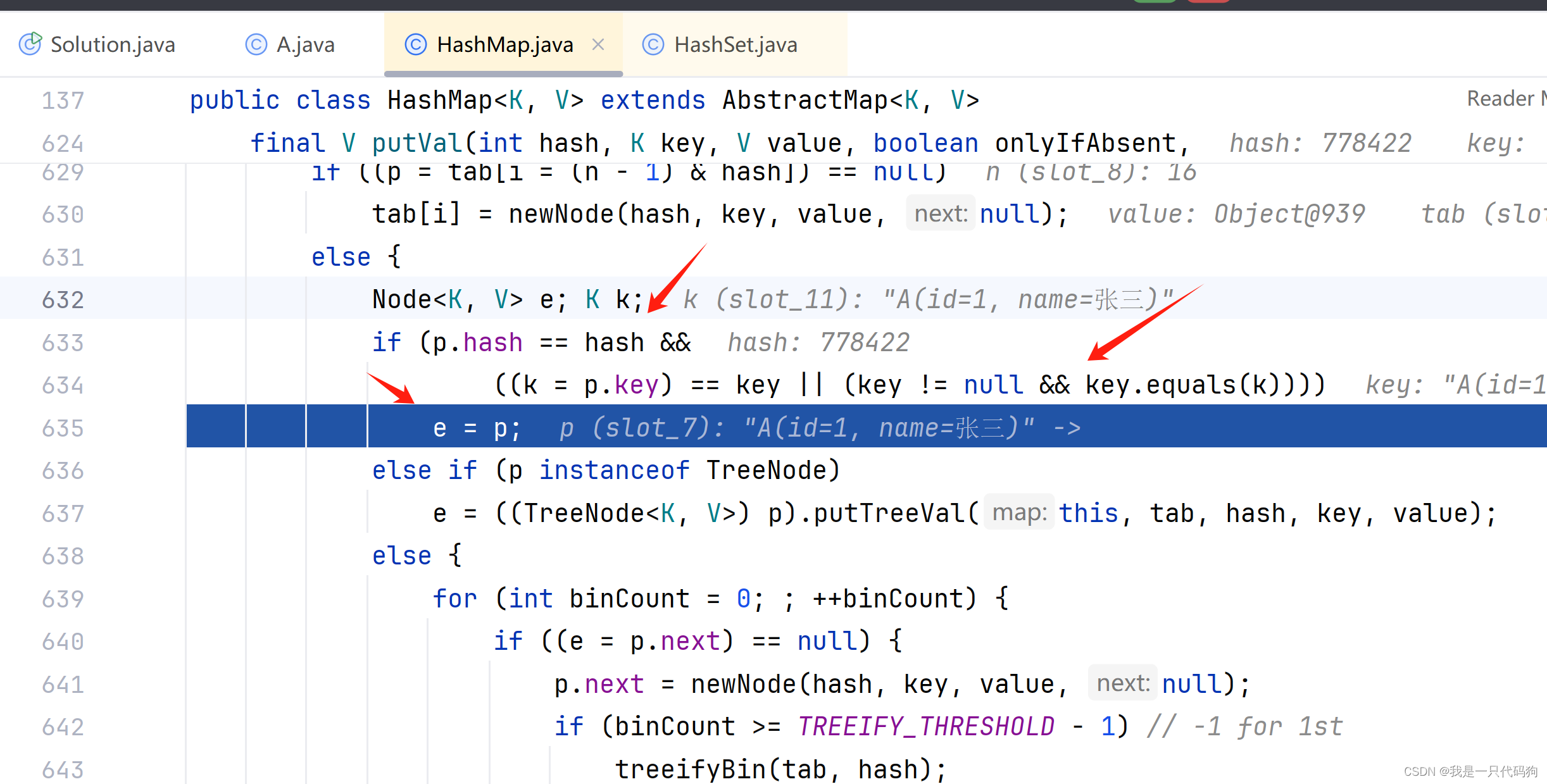
在这里直接更新value,.并没有插入数据,所以 最终插入的是只有1条数据,这就是@Data的坑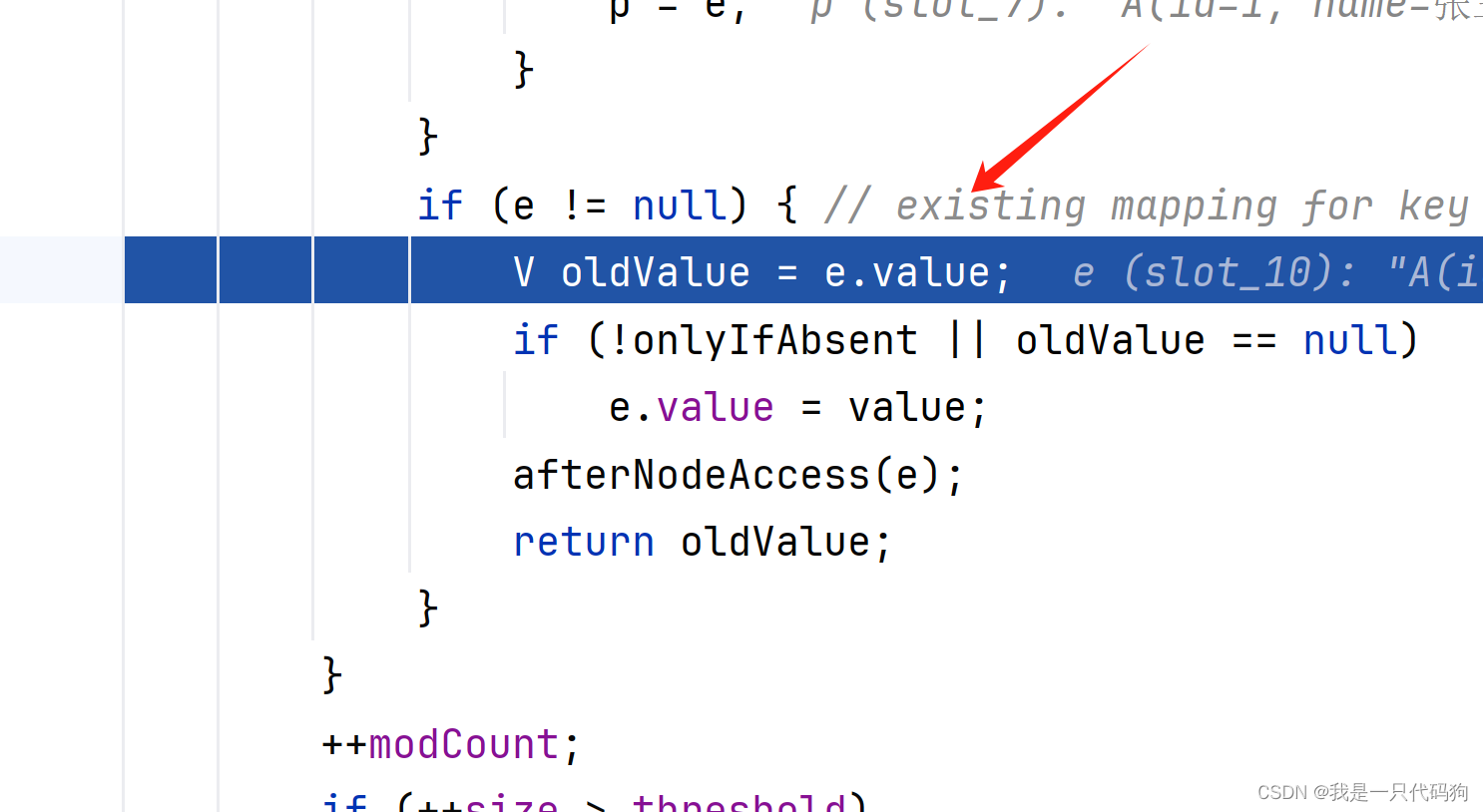
@Data注释掉场景
 第一个对象计算的hash值
第一个对象计算的hash值
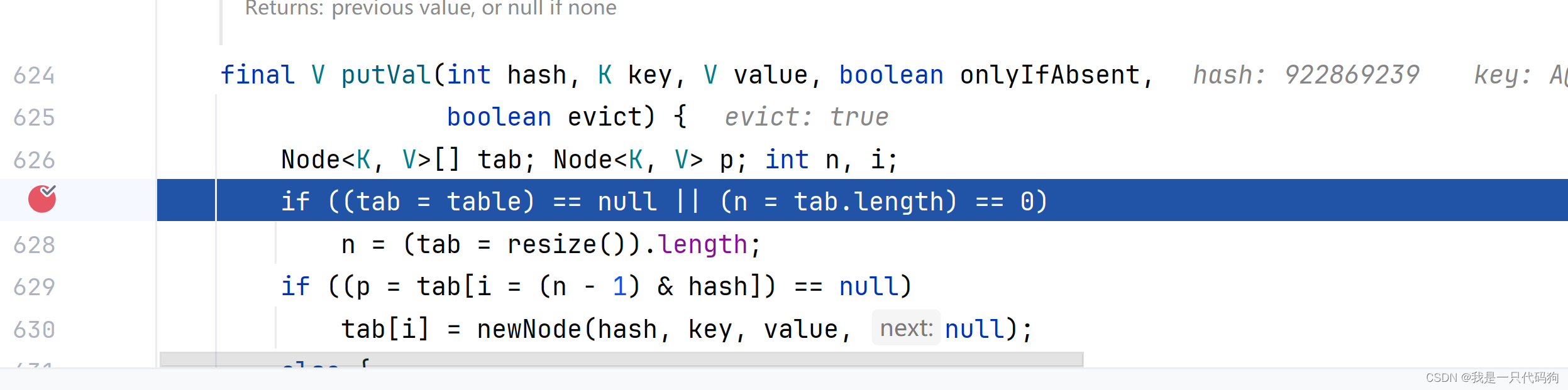
第二个对象计算的hash值
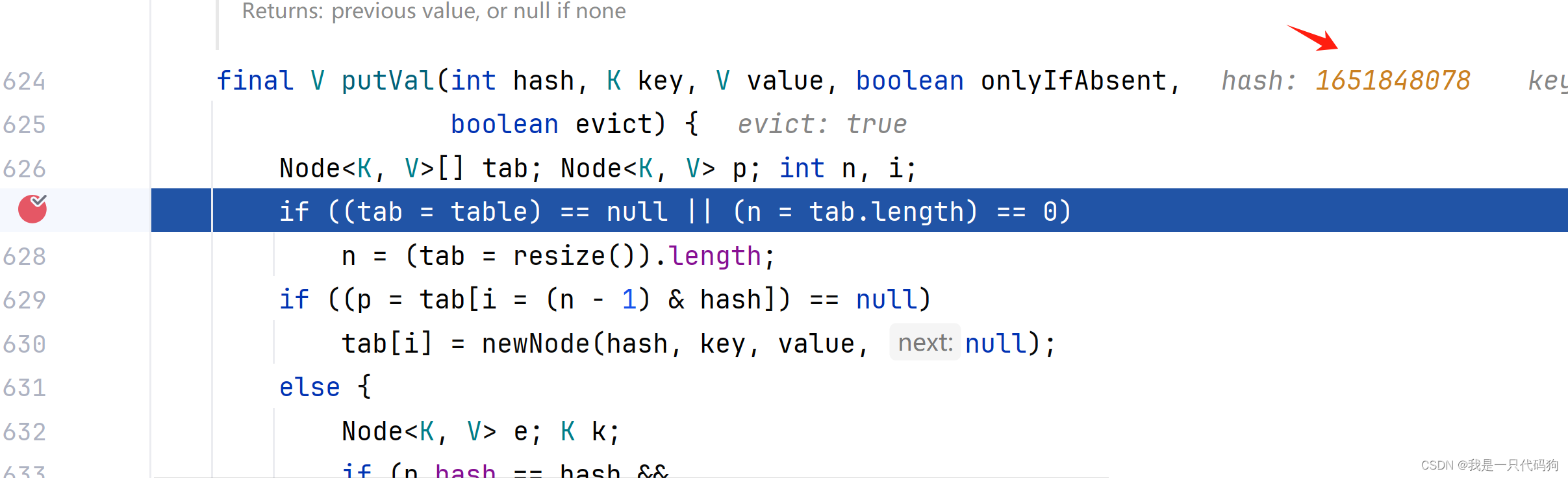
对象自带的hashcode 不一样,计算的hash值也不一样,比较的是地址值,
所以在不使用@Data注解的时候,即使对象的内容一样,也会在set插入2条数据
因为hashcode不一样
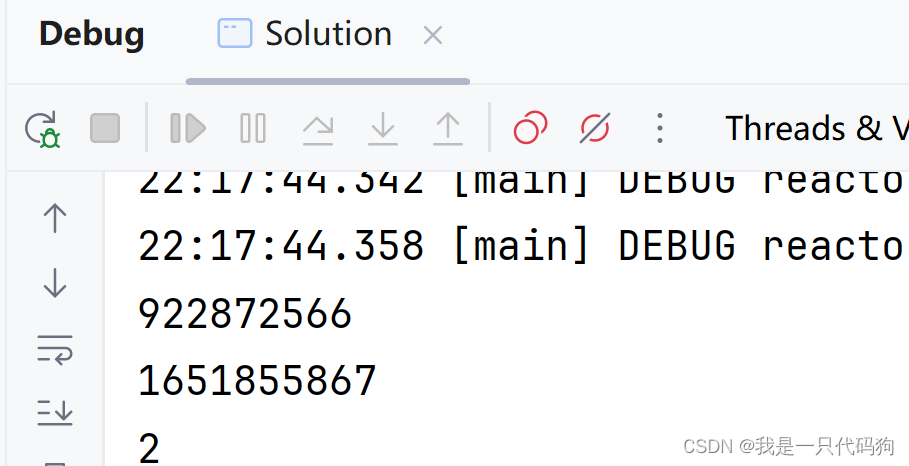















 1310
1310











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









