classPointGenCon(nn.Module):def__init__(self, bottleneck_size =2500):
self.bottleneck_size = bottleneck_size
super(PointGenCon, self).__init__()
self.conv1 = torch.nn.Conv1d(self.bottleneck_size, self.bottleneck_size,1)
self.conv2 = torch.nn.Conv1d(self.bottleneck_size, self.bottleneck_size//2,1)
self.conv3 = torch.nn.Conv1d(self.bottleneck_size//2, self.bottleneck_size//4,1)
self.conv4 = torch.nn.Conv1d(self.bottleneck_size//4,3,1)
self.th = nn.Tanh()
self.bn1 = torch.nn.BatchNorm1d(self.bottleneck_size)
self.bn2 = torch.nn.BatchNorm1d(self.bottleneck_size//2)
self.bn3 = torch.nn.BatchNorm1d(self.bottleneck_size//4)defforward(self, x):
batchsize = x.size()[0]# print(x.size())
x = F.relu(self.bn1(self.conv1(x)))
x = F.relu(self.bn2(self.conv2(x)))
x = F.relu(self.bn3(self.conv3(x)))
x = self.th(self.conv4(x))return x
classSVR_AtlasNet(nn.Module):def__init__(self, num_points =2048, bottleneck_size =1024, nb_primitives =5, pretrained_encoder =False, cuda=True):super(SVR_AtlasNet, self).__init__()
self.usecuda = cuda
self.num_points = num_points
self.bottleneck_size = bottleneck_size
self.nb_primitives = nb_primitives
self.pretrained_encoder = pretrained_encoder
self.encoder = resnet.resnet18(pretrained=self.pretrained_encoder, num_classes=1024)
self.decoder = nn.ModuleList([PointGenCon(bottleneck_size =2+self.bottleneck_size)for i inrange(0, self.nb_primitives)])defforward(self, x):
x = x[:,:3,:,:].contiguous()
x = self.encoder(x)
outs =[]for i inrange(0, self.nb_primitives):
rand_grid = Variable(torch.cuda.FloatTensor(x.size(0),2, self.num_points//self.nb_primitives))
rand_grid.data.uniform_(0,1)
y = x.unsqueeze(2).expand(x.size(0), x.size(1), rand_grid.size(2)).contiguous()
y = torch.cat((rand_grid, y.type_as(rand_grid)),1).contiguous()
outs.append(self.decoder[i](y))return torch.cat(outs,2).contiguous().transpose(2,1).contiguous()defdecode(self, x):
outs =[]for i inrange(0, self.nb_primitives):
rand_grid = Variable(torch.cuda.FloatTensor(x.size(0),2, self.num_points//self.nb_primitives))
rand_grid.data.uniform_(0,1)
y = x.unsqueeze(2).expand(x.size(0), x.size(1), rand_grid.size(2)).contiguous()
y = torch.cat((rand_grid, y.type_as(rand_grid)),1).contiguous()
outs.append(self.decoder[i](y))return torch.cat(outs,2).contiguous().transpose(2,1).contiguous()defforward_inference(self, x, grid):
x = self.encoder(x)
outs =[]for i inrange(0, self.nb_primitives):if self.usecuda:
rand_grid = Variable(torch.cuda.FloatTensor(grid[i]))else:
rand_grid = Variable(torch.FloatTensor(grid[i]))
rand_grid = rand_grid.transpose(0,1).contiguous().unsqueeze(0)
rand_grid = rand_grid.expand(x.size(0), rand_grid.size(1), rand_grid.size(2)).contiguous()# print(rand_grid.sizerand_grid())
y = x.unsqueeze(2).expand(x.size(0), x.size(1), rand_grid.size(2)).contiguous()
y = torch.cat((rand_grid, y),1).contiguous()
outs.append(self.decoder[i](y))return torch.cat(outs,2).contiguous().transpose(2,1).contiguous()defforward_inference_from_latent_space(self, x, grid):
outs =[]for i inrange(0, self.nb_primitives):
rand_grid = Variable(torch.cuda.FloatTensor(grid[i]))
rand_grid = rand_grid.transpose(0,1).contiguous().unsqueeze(0)
rand_grid = rand_grid.expand(x.size(0), rand_grid.size(1), rand_grid.size(2)).contiguous()# print(rand_grid.sizerand_grid())
y = x.unsqueeze(2).expand(x.size(0), x.size(1), rand_grid.size(2)).contiguous()
y = torch.cat((rand_grid, y),1).contiguous()
outs.append(self.decoder[i](y))return torch.cat(outs,2).contiguous().transpose(2,1).contiguous()
K是三维点集
训练使用 Chamfer Distance
L
c
d
=
∑
x
∈
K
min
y
∈
K
∗
∥
x
−
y
∥
2
2
+
∑
y
∈
K
∗
min
x
∈
K
∥
x
−
y
∥
2
2
\mathcal{L}_{c d}=\sum_{x \in K} \min _{y \in K^{*}}\|x-y\|_{2}^{2}+\sum_{y \in K^{*}} \min _{x \in K}\|x-y\|_{2}^{2}
Lcd=x∈K∑y∈K∗min∥x−y∥22+y∈K∗∑x∈Kmin∥x−y∥22
Laplacian smoothness 来保证连续性
L
l
a
p
=
∑
x
∈
K
∥
x
−
1
∣
N
(
x
)
∣
∑
p
∈
N
(
x
)
p
∥
2
\mathcal{L}_{l a p}=\sum_{x \in K}\left\|x-\frac{1}{|\mathcal{N}(x)|} \sum_{p \in \mathcal{N}(x)} p\right\|_{2}
Llap=x∈K∑∥∥∥∥∥∥x−∣N(x)∣1p∈N(x)∑p∥∥∥∥∥∥2
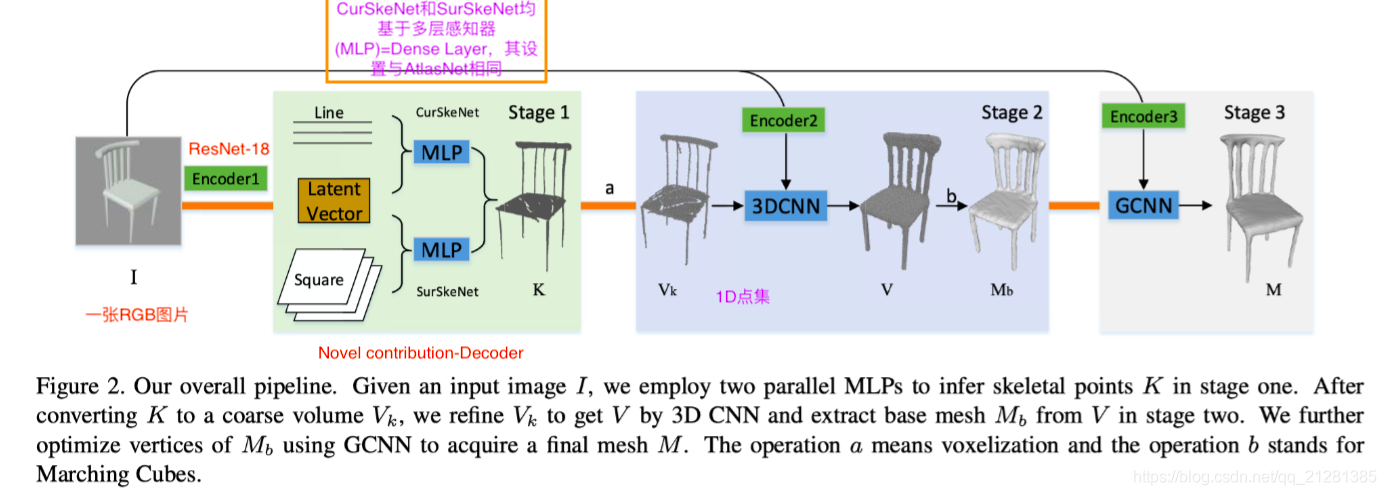
第二阶段 从骨架到基础网格
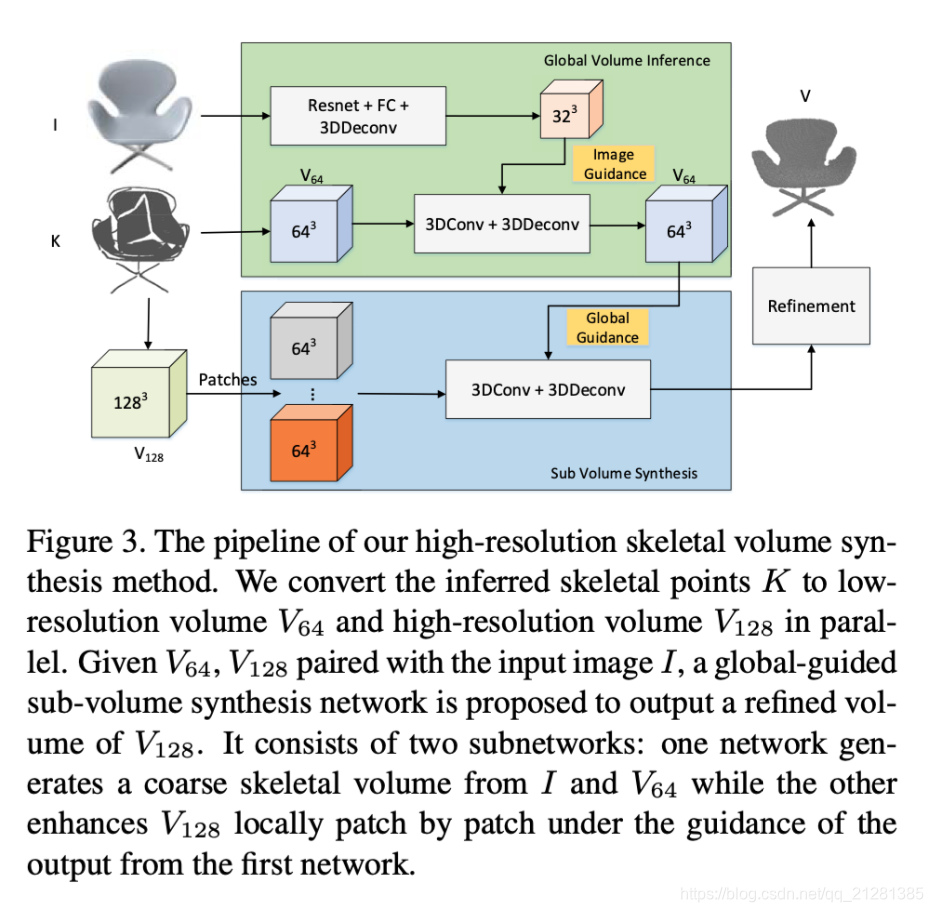
首先把三维骨架点集转换为体积表示
V
k
V_k
Vk
V
k
V_k
Vk通过3DCNN转换为
V
V
V,本文还提到要通过原图像
I
I
I来校正累计阶段预测误差。
基础网络的存储格式是点集合
P
=
{
I
∈
R
3
}
P=\{I\in R^3 \}
P={I∈R3}+面集合
S
=
{
Q
∈
R
3
}
S=\{Q\in R^3 \}
S={Q∈R3}。平面用法向量去表示。在三维中,平面可以由法向量(a,b,c)表示,因为平面可以表示成
a
x
+
b
y
+
c
z
=
0
ax+by+cz=0
ax+by+cz=0。
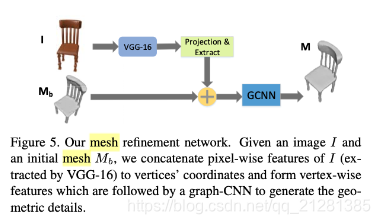
第三阶段 网格改良
M
b
M_b
Mb lack surface details
GCNN网格变形
基于图的卷及网络
h
p
l
+
1
=
w
0
h
p
l
+
∑
q
∈
N
(
p
)
w
1
h
q
l
h_{p}^{l+1}=w_{0} h_{p}^{l}+\sum_{q \in \mathcal{N}(p)} w_{1} h_{q}^{l}
hpl+1=w0hpl+q∈N(p)∑w1hql

























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









