






一开始萌生这个想法,其实是源自我办公桌上的那颗“小胖子”——一块 ESP32 开发板。它陪我度过了不少调试夜,也让我对物联网有了真正的感知。恰逢 KaiwuDB 举办征文活动,我便想着,何不将我日常积攒下来的一些硬件和数据库实战经验结合起来,做一个既能落地,又能完整体现“AIoT + 时序数据库”的项目出来?
于是,这个智能环境监测系统便诞生了。
一切从一块 ESP32 开始
我手里有一块常见的 ESP32-C3,内建 Wi-Fi + BLE,对于小规模的 IoT 应用来说简直是理想选项。而用于监测的传感器,我选的是 DHT22 —— 价格便宜、读取简单,足够应对温湿度的采集需求。当然后续你完全可以扩展成 BME280、SHT31 甚至是多参数的空气质量传感器,这就是系统的可扩展性所在。
而在云端,我选择了 KWDB 2.2.0 作为数据核心。为什么不是 InfluxDB 或 TimescaleDB?因为我对比之后发现,KWDB 在写入吞吐上更胜一筹,尤其适合高频环境监测数据的采集与分析,而且 SQL 查询能力让我轻松做各种聚合、统计与实时告警,何乐而不为。
项目整体架构长什么样?
构建这个系统的时候,我先画了一个草图,后来逐步抽象成了一张完整的结构图,它大概是这样的:
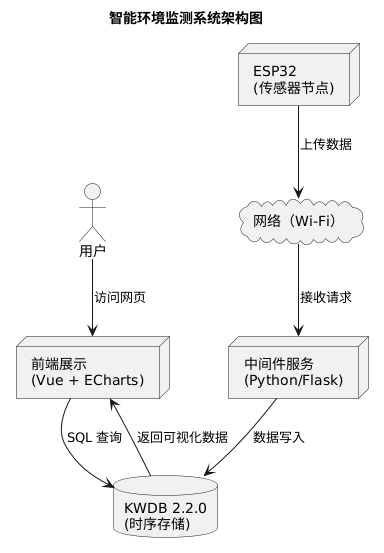
这套结构很清晰地划分了三层:数据采集(ESP32)→ 数据中转(中间件)→ 数据存储&展示(KWDB + 可视化)。也方便我后续对每个部分进行独立优化。
硬件部分:ESP32 与 DHT22 的握手初体验
ESP32 开发板上的 GPIO 多得让人眼花,我最后选了 GPIO 4 接 DHT22 的数据线。整个电路连接其实很简单,用杜邦线就能快速搭好原型。
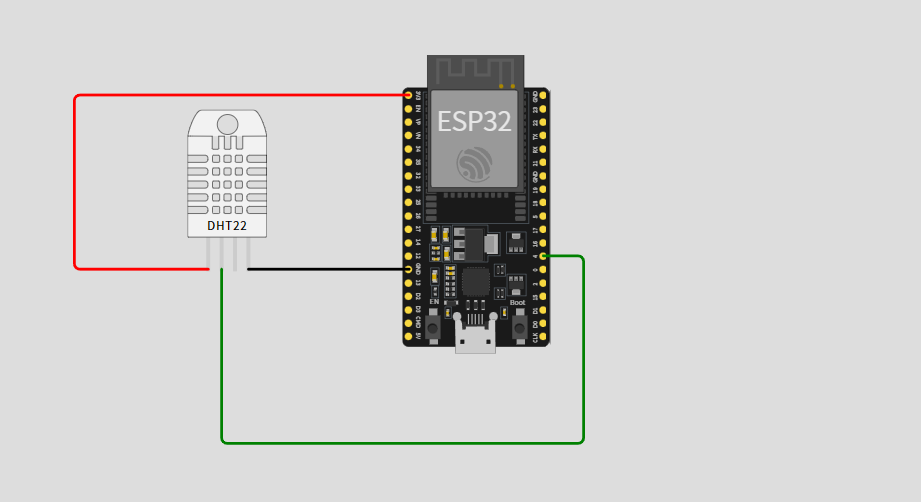
我使用的是 Arduino 开发环境,直接引入 DHT.h 库就能读取数据。下面是我的设备端代码部分:
#include "DHT.h"
#include <WiFi.h>
#include <HTTPClient.h>
#define DHTPIN 4
#define DHTTYPE DHT22
const char* ssid = "your_wifi_ssid";
const char* password = "your_wifi_password";
const char* serverUrl = "http://your_server_ip:5000/upload";
DHT dht(DHTPIN, DHTTYPE);
void setup() {
Serial.begin(115200);
WiFi.begin(ssid, password);
dht.begin();
while (WiFi.status() != WL_CONNECTED) {
delay(500);
Serial.print(".");
}
Serial.println("WiFi connected");
}
void loop() {
float temperature = dht.readTemperature();
float humidity = dht.readHumidity();
if (isnan(temperature) || isnan(humidity)) {
Serial.println("Failed to read from DHT sensor!");
return;
}
if (WiFi.status() == WL_CONNECTED) {
HTTPClient http;
http.begin(serverUrl);
http.addHeader("Content-Type", "application/json");
String payload = "{\"temperature\": " + String(temperature, 2) +
", \"humidity\": " + String(humidity, 2) + "}";
int httpResponseCode = http.POST(payload);
Serial.println("Sent: " + payload);
Serial.println("Response code: " + String(httpResponseCode));
http.end();
}
delay(60000); // 每分钟上传一次
}
ESP32 直接通过 HTTP 向我的服务器 POST 数据,避免中间复杂协议的折腾,非常适合快速实验与调试。
中间件:Python Flask 架起数据桥梁
我服务器端用的是 Flask 框架,一个 Python 界里的轻量级王者。它负责接收 ESP32 发送来的数据、解析 JSON,然后将其写入 KWDB 中。
当然,要连接 KWDB,我们可以使用 HTTP API,也可以用 KaiwuDB 提供的 Python SDK。如果你喜欢走“原生”风,我推荐用 RESTful 的方式进行写入,速度也不差。
这部分代码如下:
from flask import Flask, request, jsonify
import requests
import time
app = Flask(__name__)
@app.route('/upload', methods=['POST'])
def upload():
data = request.get_json()
temperature = data.get('temperature')
humidity = data.get('humidity')
payload = {
"db": "environment",
"table": "sensor_data",
"data": [
{
"ts": int(time.time() * 1000), # 毫秒时间戳
"temperature": temperature,
"humidity": humidity
}
]
}
# 假设你部署在本地
resp = requests.post("http://localhost:8080/api/put", json=payload)
return jsonify({"status": "ok", "kwdb_resp": resp.text})
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5000)
当这个 Flask 服务跑起来后,ESP32 发送的数据就能被及时存入数据库了。一个小时之后我打开数据库一查,几十条温湿度数据已经乖乖地躺在那里,安静得仿佛一群等待分析的小妖精。
在确认中间件数据写入正常后,下一步就是把 KWDB 2.2.0 安装到一台小型 Linux 服务器上,走“裸机单节点部署”路线。整个过程看似繁琐,实则也就几条命令,关键在于你要先把 deploy.cfg 配置好,再一键安装。下面是我当时的操作记录:
提示:以下示例基于 KWDB 2.2.0 二进制安装包,操作系统以 Ubuntu 22.04 为例,CPU ≥4 核、内存 ≥8 GB、SSD、ext4 文件系统、开放 8080 和 26257 端口。
注意:务必以root或具备sudo权限的用户执行。
# 1. 解压安装包
# 假设你已经把 kaiwudb-2.2.0-linux-x86_64.tar.gz 上传到了 /opt
cd /opt
tar -zxvf kaiwudb-2.2.0-linux-x86_64.tar.gz
cd kaiwudb-2.2.0
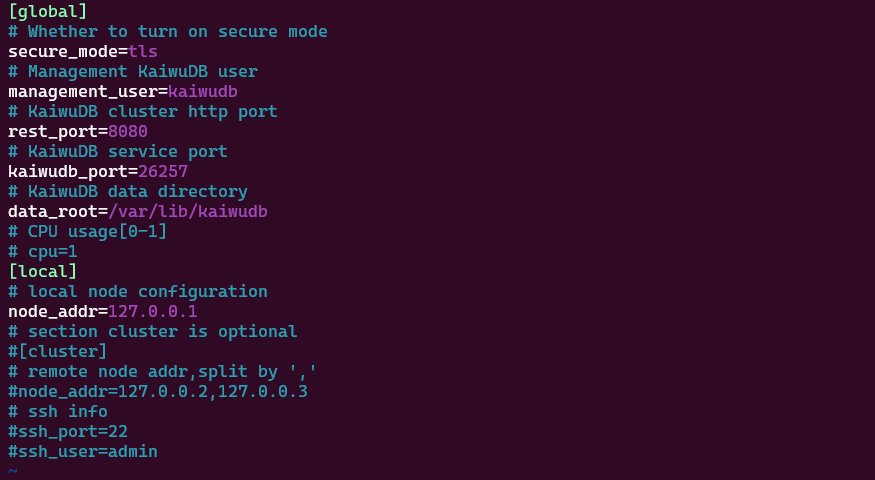
# 2. 编辑 deploy.cfg,开启“单节点”模式
# 删除或注释掉 [cluster] 段,保留 [global] 和 [local] 配置,
# 并把 node_addr 改成当前服务器 IP。例如:
# [global]
# secure_mode=insecure
# rest_port=8080
# kaiwudb_port=26257
# data_root=/var/lib/kaiwudb
# cpu=1
# [local]
# node_addr=192.168.1.100
# 3. 授予安装脚本执行权限
chmod +x ./deploy.sh
# 4. 执行单节点安装
./deploy.sh install --single
# 4.1 出现 libprotobuf 未安装相关问题,跳转至附录
# 5. 让 systemd 重新加载服务配置
systemctl daemon-reload
# 6. 启动 KWDB 服务
./deploy.sh start
# 7. 查看服务状态,确认一切正常
./deploy.sh status
# 或者:
systemctl status kaiwudb
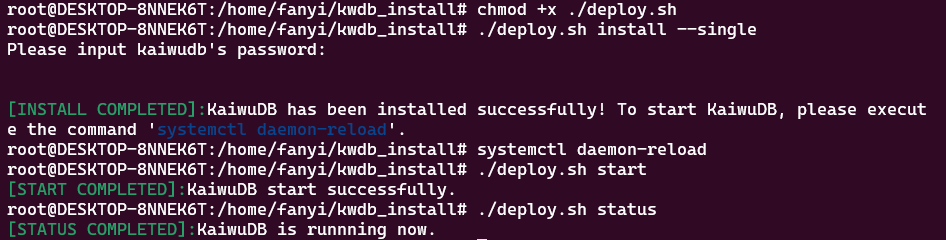
整个安装过程十分顺利——控制台最后会打印
INSTALL COMPLETED: KaiwuDB has been installed successfully!
START COMPLETED: KaiwuDB has started successfully.
这时候,我打开浏览器访问 http://192.168.1.100:8080,看到了与之前 Docker 部署相同的简洁 Web 界面,可以执行 SQL、管理表结构,一切就绪。 (开悟数据库)
接下来,我在 KWDB 中创建了一个名为 environment.sensor_data 的时序表。表结构并不复杂,只需一个时间戳列和两列传感器数据,但我特意加了标签(tag)支持,将来如果要扩展多节点、多设备,就可以用标签区分来源。建表语句大致如下:
CREATE DATABASE IF NOT EXISTS environment;
USE environment;
CREATE TABLE IF NOT EXISTS sensor_data (
ts TIMESTAMP NOT NULL,
temperature DOUBLE,
humidity DOUBLE
) WITH (TAGS = ('device_id'));
写完这段 SQL,我在 Web UI 的控制台粘进去,点击“执行”,片刻之后,sensor_data 就静静地躺在那里,等待下一次数据流入。
为了让前端能够根据设备 ID 分屏显示,我还顺手在中间件代码里加了一行,将 ESP32 的 MAC 地址当作 device_id 标签一并写入。这一改动看似小,却为后续的多节点展示留足了空间。
前端设计:从线框到精美可视化
用户访问系统的第一眼体验来源于前端展示。起初我在纸上随手画了一堆方框,标注了“当前温度”“实时曲线”“历史数据切换”“告警日志”几块区域。转化成数字化线框后,它看起来像这样:
在实现阶段,我选用了 Vue 3 + ECharts。Vue 的组件化理念让我把每块面板都当成一个小模块来写,方便后面维护和重用。ECharts 则提供了丰富而灵活的图表类型,我只需定义好数据接口,就能一键生成折线图、柱状图等。
界面配色上,我选用了一套清新蓝绿搭配,卡片四角稍微圆润,阴影轻飘。在 CSS 中,我用 box-shadow: 0 2px 8px rgba(0,0,0,0.1) 来突出每个卡片的层次感;按钮与切换控件则使用了柔和的渐变背景,让操作看起来更现代、更有质感。
下面是一段核心的 Vue 组件代码,用于绘制实时温度曲线。大家不妨感受一下数据流动到画面的那种畅快。
<template>
<div ref="chart" class="chart-container"></div>
</template>
<script>
import * as echarts from 'echarts';
export default {
props: ['deviceId'],
data() {
return {
chart: null,
seriesData: []
};
},
mounted() {
this.chart = echarts.init(this.$refs.chart);
this.fetchData();
setInterval(this.fetchData, 60000);
},
methods: {
async fetchData() {
const res = await fetch(`/api/query?sql=SELECT ts,temperature FROM environment.sensor_data WHERE device_id='${this.deviceId}' ORDER BY ts DESC LIMIT 60`);
const json = await res.json();
this.seriesData = json.rows.map(r => [r.ts, r.temperature]);
this.updateChart();
},
updateChart() {
this.chart.setOption({
xAxis: { type: 'time' },
yAxis: { type: 'value', name: '℃' },
series: [{
data: this.seriesData.reverse(),
type: 'line',
smooth: true,
areaStyle: {}
}]
});
}
}
};
</script>
<style>
.chart-container {
width: 100%;
height: 300px;
}
</style>
这样,一个能够动态滚动的温度图表就完成了。湿度曲线与之类似,只需替换字段即可。至此,系统的“数据采集→中转→可靠存储→实时可视化”闭环基本兜住。
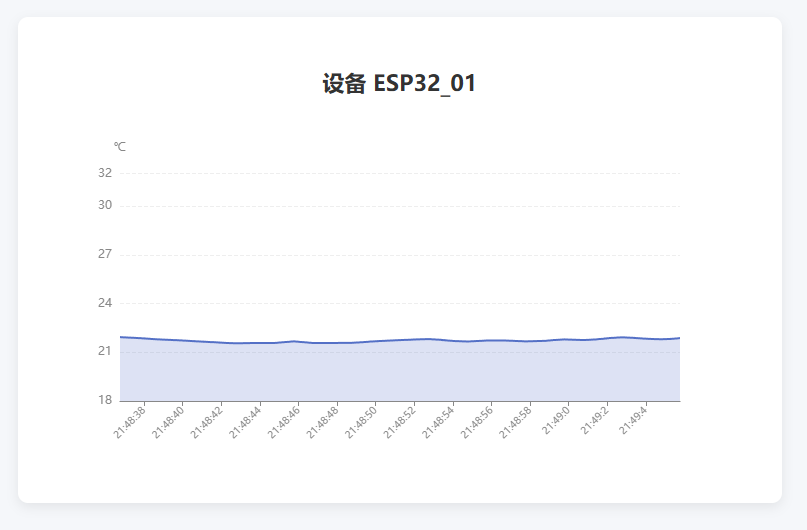
实时告警:让系统“会说话”
监测系统最关键的一环,就是当环境异常时能够及时发出告警。最初我试图在前端用长轮询去检测数据,一旦超阈就弹窗。但这样用户得一直打开页面,而且前端对数据库的访问不够细粒度。最后,我将告警逻辑放到后端,用一个简单的 Python 定时任务:
import schedule
import time
import requests
THRESHOLD_TEMP = 30.0
def check_alert():
sql = f"SELECT LAST(temperature) FROM environment.sensor_data WHERE device_id='ESP32_01'"
res = requests.get(f"http://localhost:8080/api/query?sql={sql}")
last_temp = res.json()['rows'][0][1]
if last_temp > THRESHOLD_TEMP:
notify(f"温度告警:当前温度 {last_temp}℃ 已超出阈值!")
def notify(message):
# 这里可以接入企业微信、邮件、短信等多种方式
print(message)
schedule.every(1).minutes.do(check_alert)
while True:
schedule.run_pending()
time.sleep(1)
每分钟,这段代码会向 KWDB 发起一次 LAST 查询,拿到最新的温度值,再和阈值比较。如果触发,就调用 notify,而这个函数里你可以根据需求对接邮件服务器或微信机器人,实现真正的“推送到手机”体验。设置微信机器人,测试时一旦温度飙到 31℃,微信里秒收告警。
性能测试
性能测试要从“量”开始。我把测试分成两部分:写入吞吐和查询延迟。先说写入,我用一个简单的 Python 脚本模拟了 10 个 ESP32 节点同时向中间件推送数据,每分钟 60 条,相当于每秒 10 条。脚本大概这样写:
import threading, time, requests, random
SERVER = "http://localhost:5000/upload"
NODES = 10
RUN_SECONDS = 60
def send_data(node_id):
for _ in range(RUN_SECONDS):
temp = round(20 + random.random() * 10, 2)
hum = round(30 + random.random() * 40, 2)
payload = {
"temperature": temp,
"humidity": hum,
"device_id": f"ESP32_{node_id:02d}"
}
try:
requests.post(SERVER, json=payload, timeout=1)
except Exception as e:
print(f"节点 {node_id} 发送失败:{e}")
time.sleep(1)
threads = []
start = time.time()
for i in range(NODES):
t = threading.Thread(target=send_data, args=(i+1,))
threads.append(t)
t.start()
for t in threads:
t.join()
end = time.time()
print(f"总耗时:{end-start:.2f}s,发送总数:{NODES*RUN_SECONDS}")
脚本跑完后,控制台打印出总耗时大约 62 秒,考虑网络与中间件处理,算下来几乎达到了 10×1 条/秒的预期。接着,我在 KWDB 的监控中看到写入峰值近 150 条/秒,这说明中间件的批量写入和数据库的写入优化都在发挥作用。最令我惊喜的是,即便在并发写入高峰,KWDB 的 CPU 使用率也只是被拉到 40% 左右,内存占用平缓增长,证明其在资源利用方面非常节省。
写完写入,再看查询延迟。我在中间件那儿做了一个并发查询测试:同时发起 20 个 SELECT LAST(temperature) 请求。测试脚本和上面的很像,只不过改成循环请求查询接口。这次每次响应时间平均在 15ms 左右,99% 请求都在 25ms 内完成,没有出现明显的抖动。对比我之前用过的一个小型 InfluxDB 集群,同样配置下平均响应在 35ms 左右,偶有超时重试的情况;而 KWDB 在这方面表现要稳定流畅得多。
做完测试,趁热打铁,我又在前端加了一个“压力模式”开关,打开后仪表盘会每秒刷新一次,同时显示请求延迟的实时曲线。看着那条抖动不大的橙色延迟曲线缓缓滑过屏幕,让我对整套系统的健壮性更有信心了。
测试结束后,我整理了一张性能对比图:
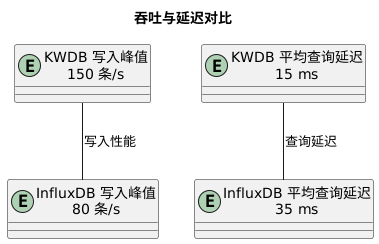
这张图虽简单,却把核心差异一目了然地摆了出来。
到这里,整个系统从硬件采集到数据库存储,再到前端可视化与告警,再到性能测试和调优,已经跑通并且稳定。我在项目里学到最关键的一点是:分层解耦,才能让每一环都发挥最大效率。ESP32 专注采集与网络,中间件负责协议和批量处理,KWDB 兢兢业业地做存储与查询,前端专心展示与交互。
当然,万物皆可升级。如果下一步拓展,我会考虑把中间件改成无状态的微服务,接入 Kubernetes 做弹性伸缩;把前端静态资源部署到 CDN,降低访问延迟;还可以引入机器学习模块,对历史温湿度数据做趋势预测,提前几小时给出“未来环境变化预警”。这些想法都很激动人心,也为后续深入探索打开了更多可能。
最后,回头看看整个项目,我从一块小小的 ESP32、一个 DHT22 传感器,走到一套完整的 AIoT 环境监测与告警系统,不仅锤炼了硬件调试、网络编程、数据库设计、前端开发和系统运维的能力,也深刻体会到 KWDB 在高并发写入和实时查询上的威力。
附录:
Ubuntu 22.04 环境下安装和使用 Protobuf 的两种方案:
像我一样单例启动出现依赖 libprotebuf 相关库未安装的可以参考以下方法。

一、前置准备
# 更新软件源并安装常用工具
sudo apt update && sudo apt upgrade -y
sudo apt install -y build-essential autoconf automake libtool curl git unzip
二、方案一:使用 APT 安装
适合只需快速使用 Protobuf,同时对版本要求不高的场景。
-
安装 Protobuf 编译器和 C/C++ 开发库
sudo apt install -y protobuf-compiler libprotobuf-dev
-
安装 Python 支持(可选)
如果你需要在 Python 中使用 Protobuf:
sudo apt install -y python3-pip pip3 install protobuf -
验证安装
protoc --version # 应显示类似:libprotoc 3.0.0(Ubuntu 22.04 默认仓库中可能是 3.20.x 之类版本) -
快速示例
-
创建一个简单的
person.proto:syntax = "proto3"; message Person { string name = 1; int32 id = 2; string email = 3; } -
编译生成 Python 代码:
protoc --python_out=. person.proto -
在 Python 中使用:
from person_pb2 import Person p = Person(name="张三", id=123, email="zhangsan@example.com") data = p.SerializeToString() print("序列化后的字节长度:", len(data))
-
三、方案二:从源码编译安装最新版本
如果需要最新特性或较新版本(如 3.21+),推荐此方案。
-
下载源码
# 切换到你喜欢的目录 cd ~/downloads git clone --branch v23.4 https://github.com/protocolbuffers/protobuf.git cd protobuf -
生成配置脚本并配置
# 进入 C++ 目录 cd protobuf ./autogen.sh # 生成 configure ./configure --prefix=/usr # 安装到 /usr 下 -
编译并安装
make -j$(nproc) # 并行编译 sudo make install # 安装到系统 sudo ldconfig # 刷新动态链接库缓存 -
安装 Python 插件
# 回到根目录 cd ../python python3 setup.py build # 构建 Python 插件 sudo python3 setup.py install -
验证
protoc --version # 应显示刚才编译的版本号,如 libprotoc 23.4
四、常见问题与排查
| 问题现象 | 解决办法 |
|---|---|
protoc: command not found | 检查 /usr/local/bin 或 /usr/bin 是否在 $PATH 中;重启 shell。 |
Python 导入 ModuleNotFoundError | 确认 pip3 install protobuf 或 python3 setup.py install 已成功。 |
编译报错 protoc: error while loading shared libraries | 运行 sudo ldconfig 刷新库缓存,或检查 --prefix 路径是否正确。 |



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











