






目录
1.任务类型
1. CPU密集型任务
CPU密集型任务主要是用来发挥CPU的功能,加解密,计算等任务时推荐线程数是CPU核数的1-2倍。
2. IO密集型任务
IO密集型任务是主要用于读写的任务,文件读写,数据库读写,通信等任务等,一般情况下推荐线程数是CPU核数的很多倍。
线程数计算方法公式:线程数=CPU核数*(1+平均等待时间/平均工作时间)
最终的线程数结果需要压测获得,监测JVM的运行情况以及CPU的负载情况。
1.1 算法题:如何计算一个大数组的和?
1.单线程相加
public class SumTest {
public static void main(String[] args) {
//定义一个存储1亿个整型数字的数组
int[] sum = new int[100000000];
Random random = new Random();
int temp = 0;
int result = 0;
for(int i=0;i < sum.length;i++){
temp = random.nextInt(100);
result +=temp;
}
System.out.println(result);
}
}2. 多线程拆分组合得出最后的值
import java.time.Duration;
import java.time.Instant;
import java.util.Random;
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Future;
public class SumThreadTest {
private static int SUM = 10000000;//每个任务计算粒度,任务粒度太小会造成计算过慢
private static int initArrLength = 100000000;//1亿个数组长度
public static void main(String[] args) throws Exception{
int result = 0;//最终结果
//0.定义1亿个长度的数组
int[] arr = new int[initArrLength];
Random random = new Random();
for (int i=0;i < arr.length;i++){
arr[i] = random.nextInt(100);
}
Instant now = Instant.now();
//1.定义一个固定线程池
int numThread = arr.length / SUM >0?arr.length / SUM : 1;
ExecutorService executorService = Executors.newFixedThreadPool(numThread);
//2.定义一个继承callable接口的任务计算类
//切分任务提交到线程池中
Task[] tasks = new Task[numThread];
Future<Long>[] taskFuture = new Future[numThread];
for(int j =0 ;j<numThread;j++){
tasks[j] = new Task(arr, j*SUM,(j+1)*SUM);
taskFuture[j] = executorService.submit(tasks[j]);
}
//3.统计线程池中的线程算出的和得出总和
for(int n =0;n < numThread;n++){
result += taskFuture[n].get();
}
System.out.println("执行时间:"+ Duration.between(now,Instant.now()).toMillis());
System.out.println("最终的结果"+result);
//关闭线程池
executorService.shutdown();
}
}
class Task implements Callable<Long>{
private int[] arr;//存储数组
private int beginSum = 0;//初始计算粒度
private int endSum = 0;//初始计算粒度
public Task(int[] arr,int beginSum,int endSum){
this.arr = arr;
this.beginSum = beginSum;
this.endSum = endSum;
}
@Override
public Long call() throws Exception {
Long result = 0L;
//计算数组的值
for(int i=beginSum;i < endSum;i++){
result += arr[i];
}
return result;
}
}1.2 forkjoin-分治思想计算
分治思想:1.分解任务 2.计算任务 3.汇总任务
适合于计算密集型任务处理
应用场景:
1. 算法中快速排序,归并排序,二分法查找
2. 大数据领域框架MapReduce
3.java提供了Fork/Join框架,实现类叫ForkJoin,重点介绍这个
ForkJoin构造方法核心参数:
int parallelism 并行线程数
ForkJoinWorkerThreadFactory factory 工作线程工厂类
UncaughtExceptionHandler handler 异常处理
boolean asyncMode(两种模式,FIFO_QUEUE(先进先出) : LIFO_QUEUE(默认,后进先出))
ForkJoinTask是ForkjoinPool的核心之一,它是任务的载体之一,是一个抽象类,里面有两个比较重要的方法: 1. fork() 提交任务 2. join() 获取任务执行结果通常我们不需要自己实现ForkJoinTask,而只需要根据场景使用以下三个继承的抽象类即可。
1. RecursiveAction 用于递归执行但不需要返回结果的任务
2. RecursiveTask 用于递归执行需要返回结果的任务,通过实现
protected abstract V compute()3. CountedCompleter<T> 在任务执行完成时会触发一个自定义的钩子函数,通过实现
public void onCompletion(CountedCompleter<?> caller)方法可以实现

ForkJoin是对传统线程池ThreadPoolExecutor的补充,传统线程池不适合计算密集型任务,不具备任务窃取的能力,这也是与普通线程池的区别之一,也是其性能保证的原因之一。
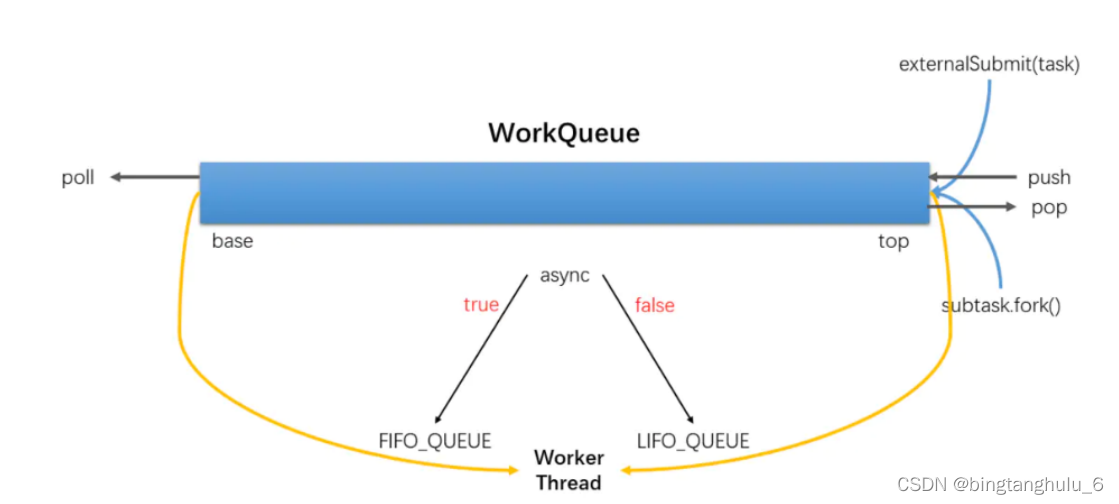
Forkjoin内有两个对象:线程对象,工作队列(双端队列)。其中的任务操作:push(向队列推送任务),pop(从队列取任务),poll(队列尾部偷取任务)。其中在线程内的队列空闲时,会去繁忙队列中的尾部偷取任务,而繁忙线程内的队列取任务会从头部取,这样是为了减少竞争的可能,加快并行计算效率。
1.2.1 fork/join实战代码
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.ForkJoinTask;
import java.util.concurrent.RecursiveTask;
public class LongSum extends RecursiveTask<Long> {
// 任务拆分最小阈值
static final int SEQUENTIAL_THRESHOLD = 10000;
int low;
int high;
int[] array;
public LongSum(int[] arr, int min, int max){
this.array = arr;
this.low = min;
this.high = max;
}
@Override
protected Long compute() {
//当任务拆分到小于等于阀值时开始求和
if (high - low <= SEQUENTIAL_THRESHOLD) {
long sum = 0;
for (int i = low; i < high; ++i) {
sum += array[i];
}
return sum;
} else { // 任务过大继续拆分
int mid = low + (high - low) / 2;
LongSum left = new LongSum(array, low, mid);
LongSum right = new LongSum(array, mid, high);
// 提交任务
left.fork();
right.fork();
//获取任务的执行结果,将阻塞当前线程直到对应的子任务完成运行并返回结果
long rightAns = right.join();
long leftAns = left.join();
return leftAns + rightAns;
//优化:第二种方式
// left.fork();
// //获取任务的执行结果,将阻塞当前线程直到对应的子任务完成运行并返回结果
// long leftAns = left.join();
// return leftAns + right.compute();
}
}
}
class Test2{
public static void main(String[] args) throws Exception{
long sum = 0L;
//100亿个数
int[] array = new int[100000001];
for(int i =0;i<100000000;i++){
array[i] = i;
}
long begin = System.currentTimeMillis();
//递归任务 用于计算数组总和
LongSum ls = new LongSum(array, 0, array.length);
// 构建ForkJoinPool
ForkJoinPool fjp = new ForkJoinPool();
//ForkJoin计算数组总和
ForkJoinTask<Long> submit = fjp.submit(new LongSum(array, 0, array.length));
System.out.println("计算总数"+submit.get());
long end = System.currentTimeMillis();
System.out.println("用时:"+(end-begin)/1000+"秒");
}
}1.2.2 fork/join源码分析
关注点:
1. 线程绑定一个队列
volatile WorkQueue[] workQueues; final ForkJoinWorkerThreadFactory factory; DefaultForkJoinWorkerThreadFactory实现类绑定队列2.提交任务到工作队列
public <T> ForkJoinTask<T> submit(ForkJoinTask<T> task)--> externalPush(task); workQueues = new WorkQueue[n];//创建工作队列看不懂,好像没什么必要看
1.2.3 jdk8并行流实战计算
使用jdk8特性计算数组性能要比forkjoin要差,而且可能出现活锁现象,其他业务线程干扰计算性能的问题。
import java.util.Random;
import java.util.stream.IntStream;
public class jdk8Test {
public static void main(String[] args) {
//定义一个1亿个数字数组
int[] sumArr = new jdk8Test().getSum(100000000);
int sum = IntStream.of(sumArr).parallel().sum();
System.out.println(sum);
}
public int[] getSum(int length){
int[] sum = new int[length];
Random random = new Random();
for(int i=0;i<length;i++){
sum[i] = random.nextInt(100);
}
return sum;
}
}















 2503
2503











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











