






QStreaming 背景
首先在进入主题之前我们先来回顾下经典的大数据 ETL 架构有哪些?
1. Lambda 架构
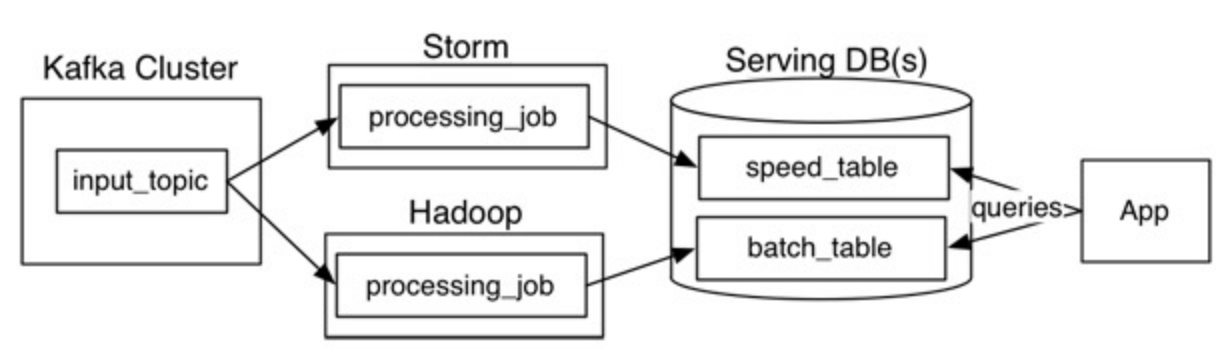
2. Kappa 架构
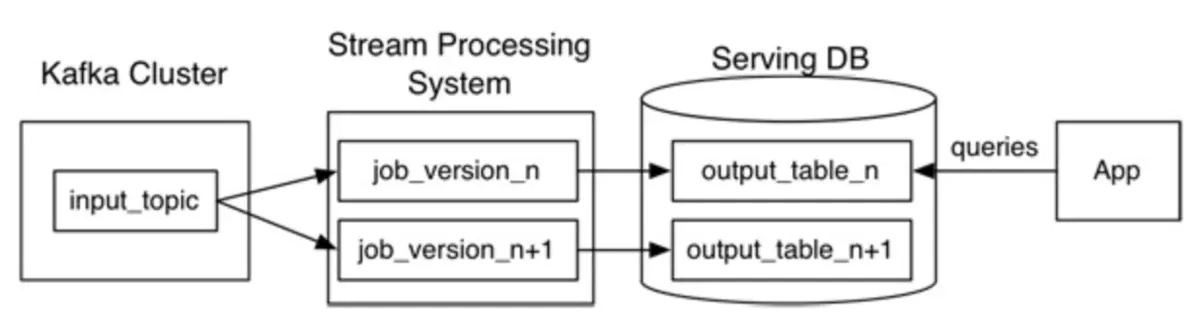
3. 混合架构
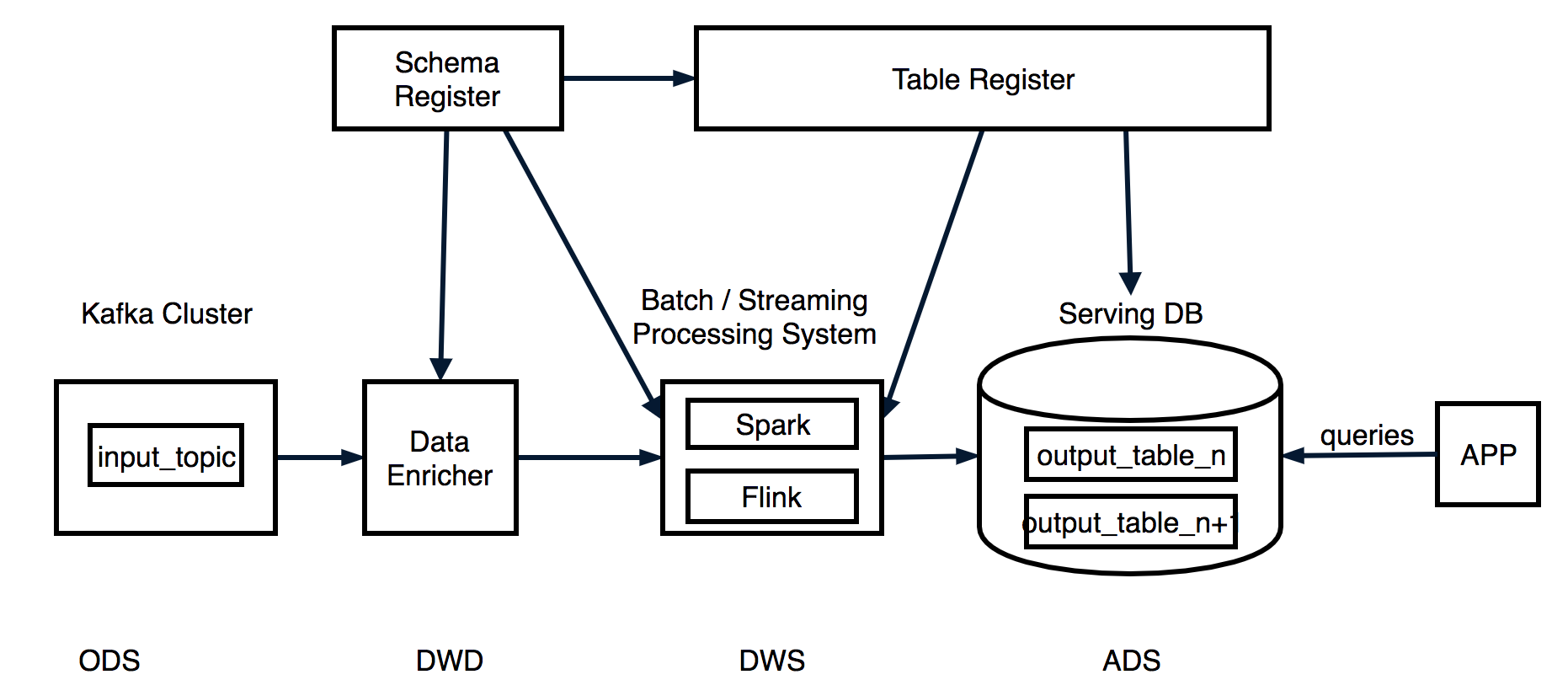
它们之间的区别如下:
| ETL架构 | 优点 | 缺点 |
|---|---|---|
| Lambda架构 |
|
|
| Kappa架构 |
|
|
| 混合架构 |
|
|
七牛的大数据平台在搭建过程中也经历了上面几个架构的变迁,也就是从最早的 Lambda 架构,到尝试使用 Kappa 架构,再到后面的新型混合 ETL 架构,为了满足业务需求,开发人员在这几个架构中进行折中选择,但是我们发现上面几个架构对于大数据的开发人员要求较高,主要体现在下面几个方面:
- 涉及到众多的框架,如流处理框架就有早期的 Apache Storm,到后面的 Apache Spark Streaming,再到 Apache Flink,学习门槛较高
- 不同计算框架对数据源的定义不统一,造成输入输出较难管理
- 数据开发人员新开发一个业务指标,不同开发人员写出的代码风格不统一,开发效率低,很难进行工程化,后期维护也必将困难
为了解决上面的几个问题,团队选择基于 Apache Spark 开发了 QStreaming (https://github.com/qiniu/QStreaming)这套简单轻量级 ETL 开发框架。
QStreaming 特性
数据源支持
- Apache Kafka
- Apache Hbase
- Hadoop HDFS
- Jdbc
- MongoDB
- Apache Hudi
- Elasticsearch
主要功能
- DDL 定义输入源
create stream input table user_behavior(
user_id LONG,
item_id LONG,
category_id LONG,
behavior STRING
) using kafka(
kafka.bootstrap.servers="kafka:9092",
startingOffsets="earliest",
subscribe="user_behavior",
"group-id"="user_behavior"
);
这里面“stream”关键字代表定义了一个流表,并且是连接到 Kafka 消息中间件。
2. 流处理 Watermark 的 DSL 支持
在 DSL 中添加 Watermark,主要有 2 种方式:
1. 在 DDL 中指定
create stream input table user_behavior(
user_id LONG,
item_id LONG,
category_id LONG,
behavior STRING,
ts TIMESTAMP,
eventTime as ROWTIME(ts,'1 minutes')
) using kafka(
kafka.bootstrap.servers="localhost:9091",
startingOffsets=earliest,
subscribe="user_behavior",
"group-id"="user_behavior"
);
上面中eventTime as ROWTIME(ts,'1 minutes'指定了ts字段为eventTime,并且设置为允许1分钟的延迟
2. 在 create view 语句中指定
create view v_behavior_cnt_per_hour(
waterMark = "eventTime, 1 minutes"
) as
SELECT
window(eventTime, "1 minutes") as window,
COUNT(*) as behavior_cnt,
behavior
FROM user_behavior
GROUP BY
window(eventTime, "1 minutes"),behavior;
上面再create view statement中通过waterMark属性指定了eventTime字段为eventTime,且设置允许1分钟的延迟
3. 动态 UDF
比如下面这个转换一个日期字符串为时间戳格式
create function minuteFormat(requestTime:String) ={
import java.time.format.DateTimeFormatter
val fiveMin = requestTime.toLong /300*300 DateTimeFormatter.ofPattern("yyyyMMddHHmm").withZone(java.time.ZoneId.systemDefault).format(java.time.Instant.ofEpochSecond(fiveMin))
}
4. 流处理的多输出
create stream output table output using kafka(
kafka.bootstrap.servers=<kafkaBootStrapServers>,
topic="topic1"
),kafka(
kafka.bootstrap.servers=<kafkaBootStrapServers>,
topic="topic2"
)TBLPROPERTIES (outputMode = update,checkpointLocation = "behavior_output");
上面这条语句指定了一个结果的多个输出,这个特性主要是通过 Spark Structed Streaming 的 foreachBatch 实现的。
5. 变量渲染
变量渲染经常在一些定时调度批处理中非常有用,如下根据小时读取一个 HDFS 上的parquet 文件。
create batch input table raw_log
USING
parquet(path="hdfs://cluster1/logs/day=<day>/hour=<hour>");
上面语句用<>括起来的参数代表可被运行时替换。
6. 监控
kafka lag 监控
由于 Apache spark 消费 Kafka 是使用的低阶 API,默认我们没有办法知道消费的 topic有没有延迟,我们通过指定 group-id 属性,模拟 Kafka consumer 的 subscribe 模式,这样就和普通的 Kafka consumer 高级 API 一样了。
create stream input table user_behavior(
user_id LONG,
item_id LONG,
category_id LONG,
behavior STRING,
ts TIMESTAMP,
eventTime as ROWTIME(ts,'1 minutes')
) using kafka(
kafka.bootstrap.servers="localhost:9091",
startingOffsets=earliest,
subscribe="user_behavior",
"group-id"="user_behavior"
);
通过添加"group-id"这个属性就可以在消费kafka的时候提交消费的Offset到user_behavior这个dummy consumer group。
7. 数据质量
CREATE TEST testName(testLevel=Error,testOutput=testResult) on dataset WITH
numRows()=5 and
isNotNull(id) and
isUnique(id) and
isComplete(productName) and
isContainedIn(priority, ["high", "low"]) and
isNonNegative(numViews) and
containsUrl(description) >= 0.5 and
hasApproxQuantile(numViews, 0.5) <= 10
这个特性主要是用来对数据做单元测试的,比如校验我们 ETL 结果表的准确性。
- 流读批写
这个特性是用来在集成一些第三方spark connector的时候,发现某些connector没有对流的写入支持得很好,只能在批处理场景中使用,那么这个时候就可以用上这个特性。
比如下面这条语句
create stream output table behavior_cnt_per_hour using jdbc(
url=<yourJdbcUrl>,
user=<jdbcUser>,
password=<jdbcPassword>,
dbTable=<jdbcTable>
) TBLPROPERTIES(batchWrite=true)
由于sparkjdbcconnector本身没有对流进行支持,但是我们加上了 TBLPROPERTIES(batchWrite=true),这样就能够在流计算中往数据库写入数据。
9.其他
支持对view或者table的repartition及coalesce操作,这个和spark本身对dataset进行repartition及coalesce时一样支持的。
比如下面这条create view 语句加入了coalesce,代表对结果进行了coalesce操作,并且设置重分区为1个分区。
create view v_request_log with(coalesce=1) as
select
request_time,
domain,
server_ip,
ip_ver,
scheme,
status_code,
hitmiss,
bytes_sent,
response_time
from request_log;
10. 语法
QStreaming 完整的语法特性参考:
(https://github.com/qiniu/QStreaming/blob/master/stream-core/src/main/antlr4/com/qiniu/stream/core/parser/Sql.g4)
QStreaming 架构
架构图
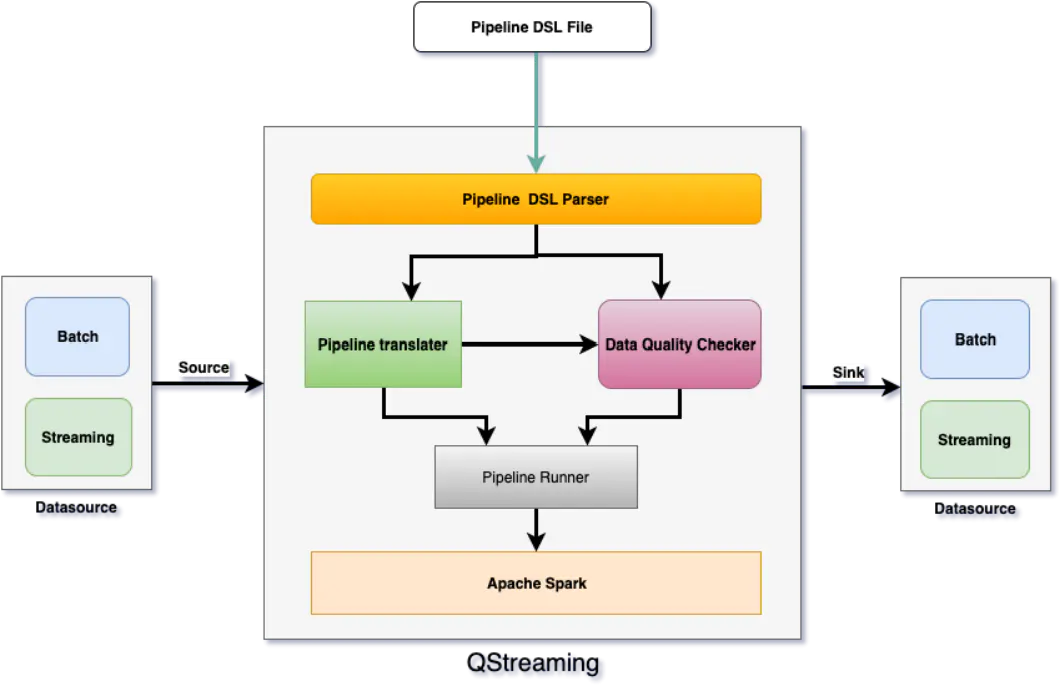
核心组件
从上面的架构图中可以看出 QStreaming 主要有以下几个组件组成:
1. Pipeline DSL
Pipeline DSL 是一个定义时的 Job 任务描述文件,类似于 SQL 语法,对 Spark SQL 完全兼容,语法支持通过ANTLR (https://www.antlr.org)解析,主要包含了3个部分的statement
- 定义输入表
- 流式输入(create stream input table xxx)
- 批输入(create batch input table xxx)
- 定义输出表
- 流式输出(create stream output table xxx)
- 批示输出(create batch output table xxx)
- 指标计算
- create view as
2. Pipeline DSL Parser
Pipeline DSL Parser 组件负责解析 Pipeline DSL 并且转换 ANTLR AST 为 Pipeline Domain Models。

Pipeline Domain Models
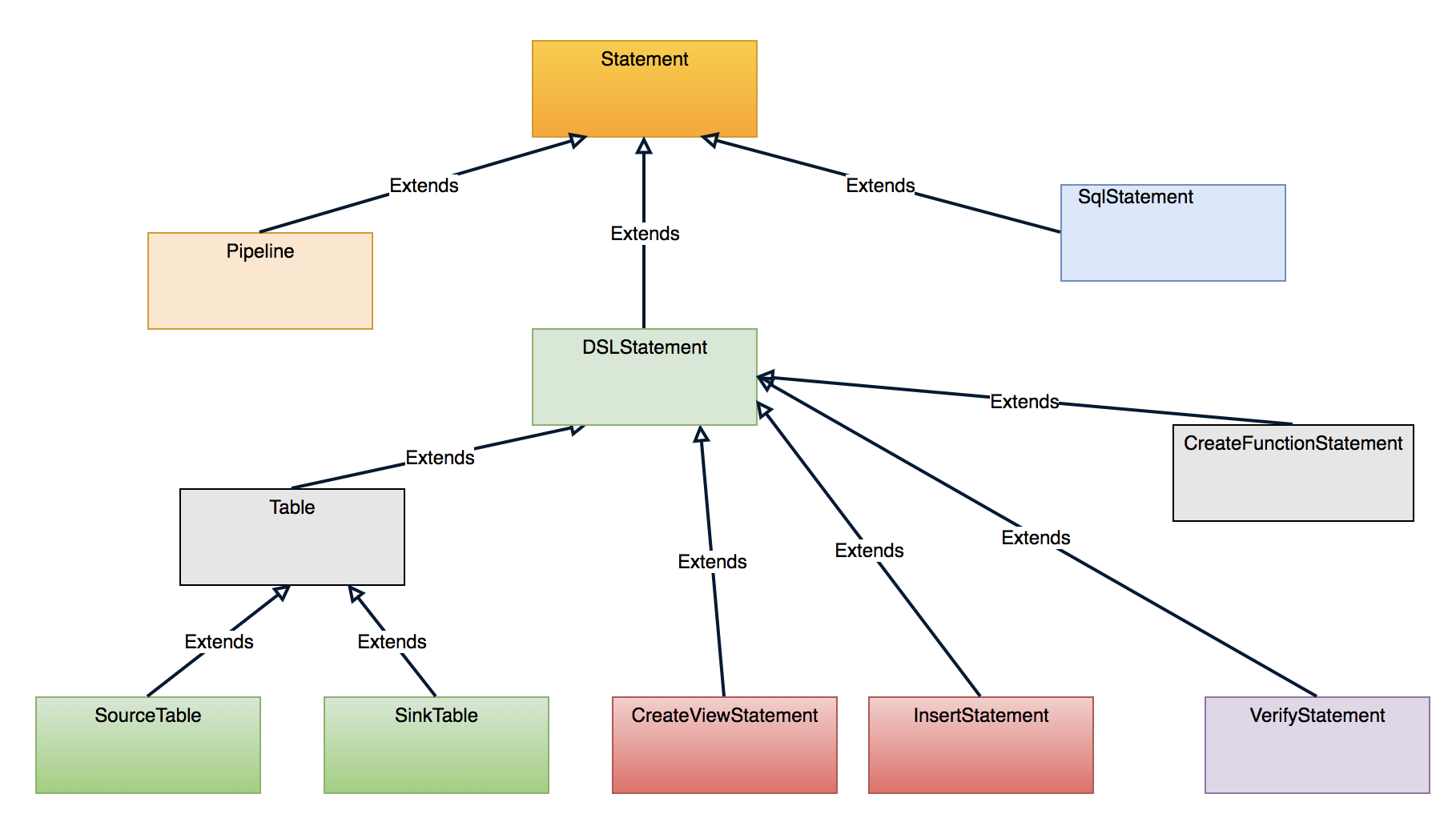
3. Pipleine Translator
Pipeline Translator 进一步将 Pipeline domain model 转换为 Spark transformations and actions。

4. Data Quality Checker
Data Quality Check 负责解析单元测试语句,使用 Amazon Deequ 库并且翻译为 Deequ 的 Verification Suite。

5. Pipeline Runner
这个组件负责构建 Pipeline 启动上下文,协同 Pipeline Parser 和 Pipeline Translator一起工作,根据配置启动流或者批处理 Application。
QStreaming 使用场景
场景一
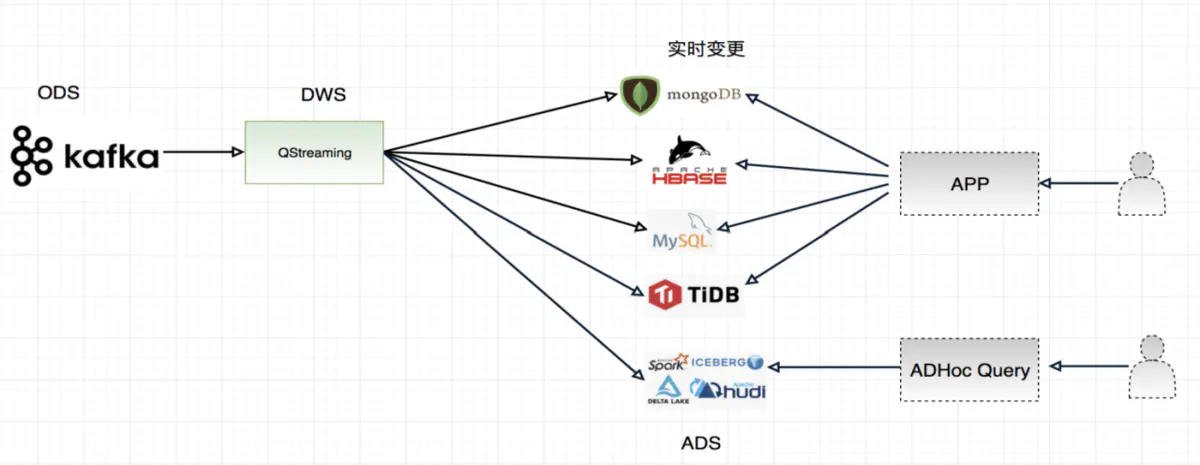
在这一个场景中,QStreaming 主要通过消费 Kafka,然后进行预聚合,预聚合可以进行开窗口计算,比如 1 分钟的窗口,然后在把窗口聚合的结果写入下游数据存储中,这里面很重要的一个特性就是数据订正功能
场景二
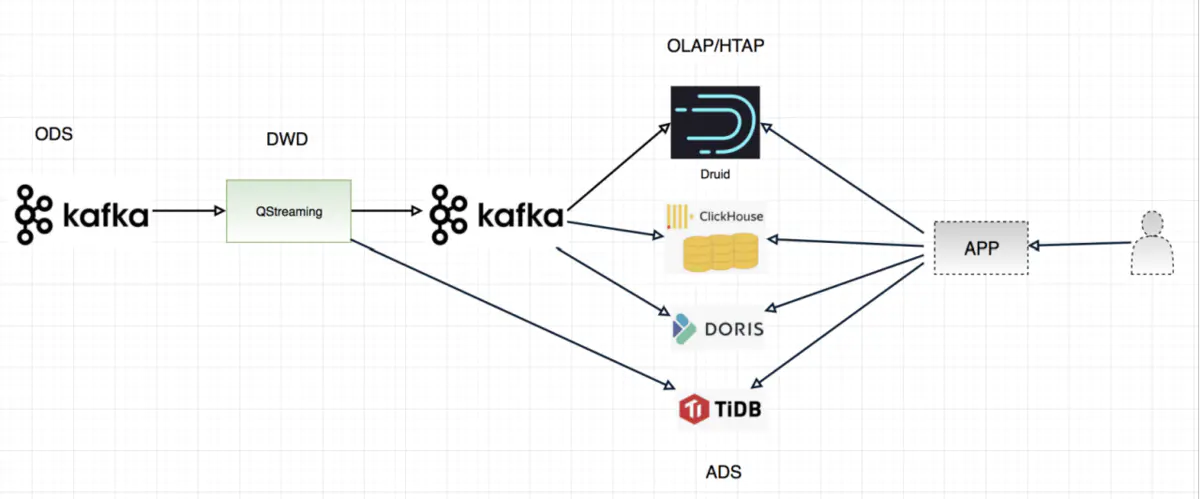
在这个场景中,QStreaming 扮演了一层很薄的角色,比如对数据进行加工,但是不对数据进行聚合,保留了明细,预聚合的功能交给了下游支持 OLAP 的引擎,比如支持 RollUp 功能的 Apache Druid,Apache Doris,Clickhouse 等,另外如果使用 Apache Doris 还可以保留明细功能。
场景三
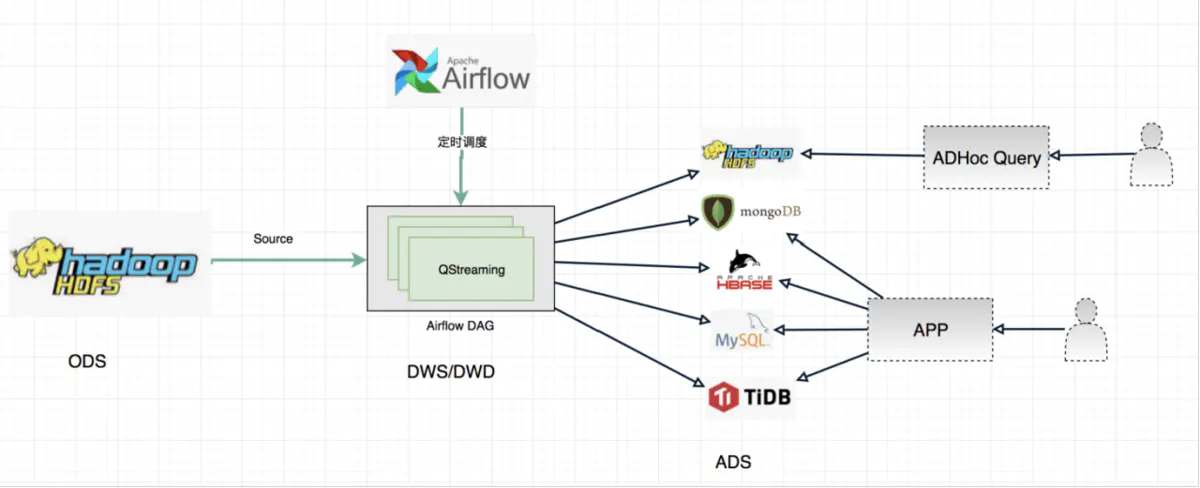
在这个场景中,QStreaming 主要是通过 Apache Airflow 进行调度的,ODS 对接 Apache Hive 数据仓库,然后可以做 DWS 或者是 DWD 操作,再把结果写入 Hive 数据仓库中,提供离线即席查询,或者是聚合的结果写入 RDS,NOSQL 等数据库,上层对其结果封装为 API,供用户使用。
场景四
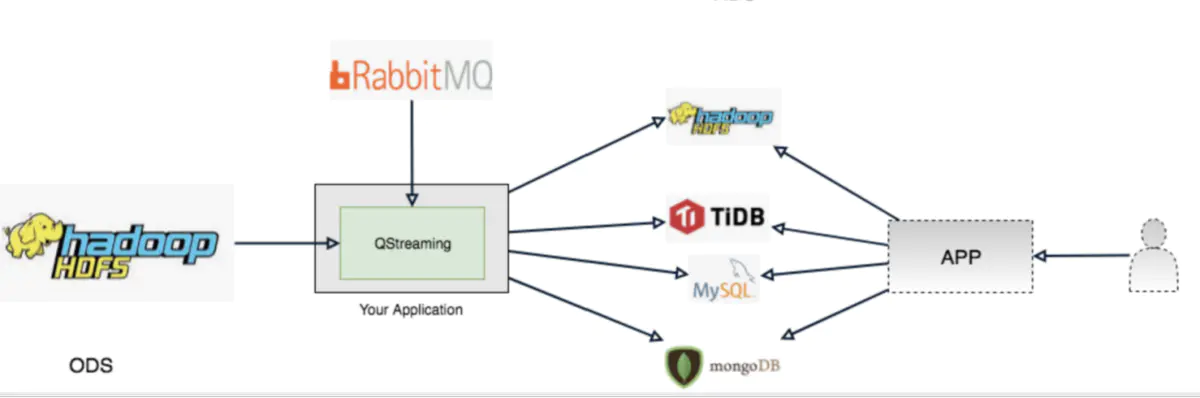
这个场景主要是消息驱动的,通过上游业务方发送消息到消息中间件,然后消费消息驱动 QStreaming ETL 任务。
QStreaming 总结
整体上 QStreaming 可以从 三点简单概况:
- 架构层面:可用于 Lambda架构,Kappa架构,混合架构三种架构中,并且灵活切换。
- 开发层面:只需要掌握 SQL 即可。
- 运维层面:能够实现统一部署和管理。
QStreaming 规划
QStreaming 还非常年轻,后期还会有进一步的规划,规划的特性包括完善数据源支持(如 Delta Lake,Apache Hudi 等),数据血缘功能和机器学习 Pipeline















 2696
2696











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









