







布隆过滤器
- 在看此文时强烈希望同仁们能看看散列(哈希)查找这篇文章,对散列查找理解掌握!
- 此文乃对书籍和博客的总结而成!
(一).题目与分析
首先我们来看一个大数据和空间限制的题目
【题目】不安全网页的黑名单里有100亿个数据,每一个网页的URL最多占用64B。要求实现一种过滤系统,可以根据网页的URL判断是否在这个黑名单中。系统允许有万分之一的失误率。且额外的空间不能超过30GB。
如果把所有数据用哈希表存储,那么至少需要100亿*64B 约等于640亿(记住10亿B约等于1G)。不满足要求!
在遇到网页黑名单系统、垃圾邮件过滤系统、爬虫的网址判重系统等问题,又看到系统容忍一定程度的失误率但是对空间要求比较严格时,我们应该想到布隆过滤器!
布隆过滤器代表一个集合,并且可以精确地判断一个元素是否在集合中。
散列(哈希)查找这篇文章详细讲述哈希函数如何设计,产生冲突后应如何解决冲突!接下来我再稍微介绍一下哈希函数的概念:
哈希函数它是个函数,就对应的有输入域和输出域,它的输入域可以是非常大的范围,比如URL,字符串。但是输出域是固定的,假设为D。
1、典型的哈希函数有无限的输入域
2、哈希函数输入相同值,返回相同的值(比如当我们将有重复出现的值进行哈希到不同的文件时,重复的数就不会到其他文件中)
3、哈希函数输入不同值,返回值可能相同,也可能不同(哈希冲突)
4、很多不同的输入值所得到的返回值均匀的分部在D上。
(二).介绍布隆过滤器
首先我们来看一下什么是布隆过滤器:
1.假设一个长度为m的bit类型的数组,把bit类型的数组称为bitMap,即数组的每一个位置只占一个bit,(一个bit只有0或1俩种状态)。
2.假设有k个相互独立且足够优秀(指哈希值分布均匀)的哈希函数。
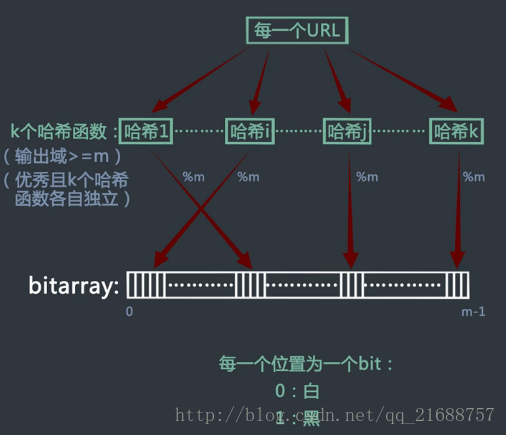
一个输入值经过k个哈希函数后,得到了k个哈希值再%m后将这个值映射到这个bit数组中,有的就涂黑。所给的题就是将100亿个值依次经过上述过程将bit数组涂黑(置为1)。过后将一个网页的URL经过k个哈希函数得到的k个值对应的bit数组是否被涂黑,若涂黑了就认为在黑名单中,如果没有涂黑就肯定不在黑名单中。当然如果m的长度不够长则会导致bit数组全被涂黑。所以这个方法是有一定的错误率的。“宁可错杀三千,不能放过一个”。
读者可以注意到bitMap的大小m对于输入对象的个数n过小,失误率会过大!在此题中我们已知输入对象n,对象n的大小和失误率。每个样本的大小只和哈希函数有关,使用布隆过滤器时可以不用考虑样本大小。
m和哈希函数的数量k为假设,我们需要求出!具体方法看下图:
















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









