






目录
1、了解决策树
就如字面意思,决策树就是充满决策的树。如下图所示:
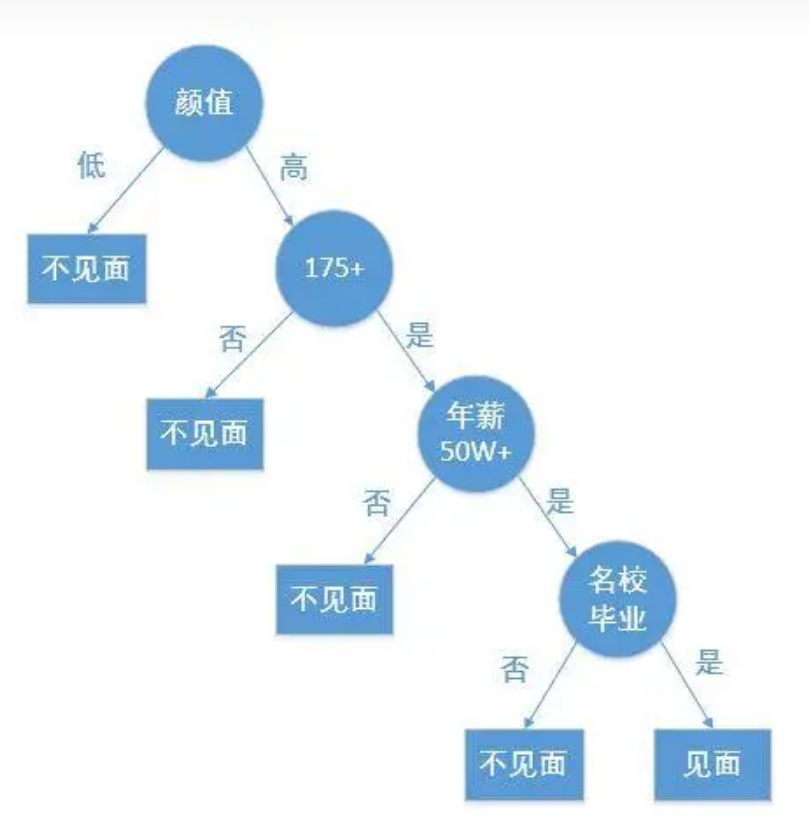
假设一个人要去相亲,那么是否去见面就是一个决策的过程。在最终决定前就要进行许多决策。以上图为例子,他的首要条件是颜值(即根节点),如果不过关,便不再延伸。颜值过关了,该决策树就会长出枝条继续延伸下去,当然也还有其他次要要求(分支节点),直到符合他的某些要求,决策停止。当然不见面也是一个结果(最终决策结果为子节点)。这些所有的决策构成了决策树。
2、基本流程
要让机器来评判哪个是好的哪个是坏的决策。那么我们就要让机器去训练,构造一个决策树。对于测试的数据。能够给出一个决策结果。
3、划分选择

Ent(D)的值越小,则D的纯度越高
计算信息熵时约定:若p = 0,则plog2p=0
Ent(D)的最小值为0,最大值为log2|y|
(1)信息增益
离散属性a(比如色泽)有V个可能的取值{a1, a2, ..., aV}(比如青色、绿色等),用a来进行划分,则会产生V个分支结点,其中第v个分支结点包含了D中所有在属性a上取值为av的样本,记为Dv。则可计算出用属性a对样本集D进行划分所获得的“信息增益”: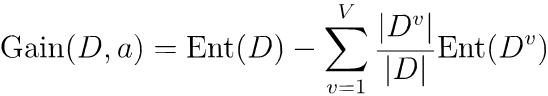
一般而言,信息增益越大,则意味着使用属性a来进行划分所获得的“纯度提升”越大。
(2)增益率
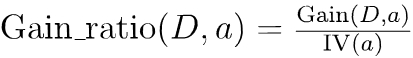
其中
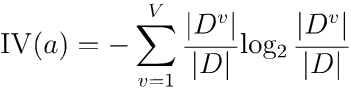
称为属性a的“固有值” [Quinlan, 1993] ,属性a的可能取值数目越多(即V越大),则IV(a)的值通常就越大。
(3)基尼指数
定义:分类问题中,假设D有K个类,样本点属于第k类的概率为𝑝𝑘,则p_k,则概率分布的基尼值定义为:
![]()
Gini(D)越小,数据集D的纯度越高。
给定数据集D,属性a的基尼指数定义为: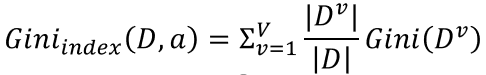
那么做这些的目的是为了选择一个最优属性作为根节点,其他属性依次作为分支节点。在最开始我们可以认为的去选择最优。那么机器它对于一个给定的数据集合需要去学习一个最优解。通过这些标准去评判最终构造一个决策树。
4、剪枝
剪枝的主要目的是防止过拟合。过拟合主要是指机器在一个训练数据集上训练太好但在其他数据集上表现一般。那么剪枝又分为预剪枝和后剪枝。
(1)预剪枝
通过提前停止树的构建而对树剪枝。主要方法有:
(2)后剪枝
后剪枝就是首先构造一棵完整的树然后自底向上去分析计算。如果对于整个决策树的性能有提升的保留,下降的剪掉。
5、python代码
# 定义节点类
class Node:
def __init__(self, predicted_class):
self.predicted_class = predicted_class # 预测的类别
self.feature_index = 0 # 特征索引
self.threshold = 0 # 阈值
self.left = None # 左子树
self.right = None # 右子树
# 定义决策树分类器
class DecisionTreeClassifier:
def __init__(self, max_depth=None):
self.max_depth = max_depth # 树的最大深度
# 训练模型
def fit(self, X, y):
self.n_classes_ = len(set(y)) # 类别的数量
self.n_features_ = len(X[0]) # 特征的数量
self.tree_ = self._grow_tree(X, y) # 构建决策树
# 预测新的数据点
def predict(self, X):
return [self._predict(inputs) for inputs in X]
# 寻找最佳分裂点
def _best_split(self, X, y):
m = len(y)
if m <= 1:
return None, None
num_parent = [y.count(c) for c in range(self.n_classes_)]
best_gini = 1.0 - sum((n / m) ** 2 for n in num_parent)
best_idx, best_thr = None, None
for idx in range(self.n_features_):
thresholds, classes = zip(*sorted([(X[i][idx], y[i]) for i in range(m)]))
num_left = [0] * self.n_classes_
num_right = num_parent.copy()
for i in range(1, m):
c = classes[i - 1]
num_left[c] += 1
num_right[c] -= 1
gini_left = 1.0 - sum(
(num_left[x] / i) ** 2 for x in range(self.n_classes_)
)
gini_right = 1.0 - sum(
(num_right[x] / (m - i)) ** 2 for x in range(self.n_classes_)
)
gini = (i * gini_left + (m - i) * gini_right) / m
if thresholds[i] == thresholds[i - 1]:
continue
if gini < best_gini:
best_gini = gini
best_idx = idx
best_thr = (thresholds[i] + thresholds[i - 1]) / 2
return best_idx, best_thr
# 构建决策树
def _grow_tree(self, X, y, depth=0):
num_samples_per_class = [y.count(i) for i in range(self.n_classes_)]
predicted_class = num_samples_per_class.index(max(num_samples_per_class))
node = Node(predicted_class=predicted_class)
if depth < self.max_depth:
idx, thr = self._best_split(X, y)
if idx is not None:
indices_left = [i for i in range(len(X)) if X[i][idx] < thr]
X_left, y_left = [X[i] for i in indices_left], [y[i] for i in indices_left]
X_right, y_right = [X[i] for i in range(len(X)) if i not in indices_left], [y[i] for i in range(len(y)) if i not in indices_left]
node.feature_index = idx
node.threshold = thr
node.left = self._grow_tree(X_left, y_left, depth + 1)
node.right = self._grow_tree(X_right, y_right, depth + 1)
return node
# 预测新的数据点
def _predict(self, inputs):
node = self.tree_
while node.left:
if inputs[node.feature_index] < node.threshold:
node = node.left
else:
node = node.right
return node.predicted_class
# 创建数据集
X = [[1, 2], [1, 3], [2, 3], [2, 2], [3, 1], [3, 2]]
y = [0, 0, 1, 1, 2, 2]
# 创建决策树分类器
clf = DecisionTreeClassifier(max_depth=2)
# 训练模型
clf.fit(X, y)
# 预测新的数据点
print(clf.predict([[2, 2]])) # 输出:[1]
newbing生成,简单了解就好0.0















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









