







一、背景
在自测的时候,发现有个函数统计的数据很少,但是耗时比同类型复杂函数更多。然后用Django调试models输出的SQL语句,发现该函数在统计数据时,用了很多count()操作,产生了很多sql查询操作。
二、分析
考虑到代码安全,以下代码都是经过脱敏处理的。不过不影响我们的性能分析效果。
优化前
代码片段:
def get_obj_static_data(bk_object_key, username="admin"):
# 对象下,有权限的,并且已经巡检的实例
start = datetime.now()
check_obj, inst_obj = get_inst_by_obj(bk_object_key, username=username)
xxxx
# 资源总数
count["resource_num"] = inst_obj.count()
# 已开启周期任务的实例
count["has_interval"] = inst_obj.filter(is_interval=True).count()
# 未开启周期任务的实例
count["no_interval"] = inst_obj.filter(is_interval=False).count()
# 资源未扫描
count["no_scan"] = inst_obj.filter(latest_poll__isnull=True).distinct().count()
# 已扫描资源
inst_obj = inst_obj.filter(latest_poll__isnull=False).distinct()
xxxx
job_result_obj = JobResultAnalyze.objects.filter(
bk_object_key=check_obj.bk_object_key,
key__in=index_key_list,
is_dimension=False,
).filter(filter_list)
# 正常指标
success_keys = job_result_obj.filter(compare_result=JobResultAnalyze.SUCCESS).values_list("key", flat=True)
error_job_result = job_result_obj.filter(compare_result=JobResultAnalyze.ERROR)
error_keys = error_job_result.values_list("key", flat=True)
count["success"] = len(set(success_keys) - set(error_keys))
# 配置差异
count["config_error"] = (error_job_result.filter(index_type=IndexTemplate.CONFIG_INDEX)
.values("key", "risk_rate").distinct().count())
# 危险和警告指标
count["danger"] = (error_job_result.filter(risk_rate=IndexTemplate.DANGER)
.values("key", "risk_rate").distinct().count())
count["warning"] = (error_job_result.filter(risk_rate=IndexTemplate.WARNING)
.values("key", "risk_rate").distinct().count())
print((datetime.now() - start).total_seconds())
return count
结果分析:
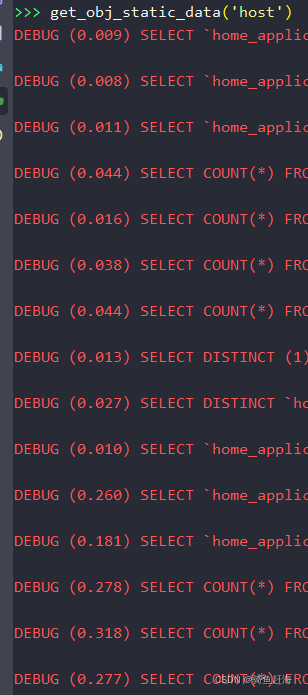
下图是该段代码的运行情况:
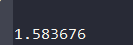
总共查询数据库15次,耗时1.58s
优化后
代码片段:
def get_obj_static_data_new(bk_object_key, username="admin"):
# 对象下,有权限的,并且已经巡检的实例
start = datetime.now()
check_obj, inst_obj = get_inst_by_obj(bk_object_key, username=username)
xxx
# 已扫描实例
has_scan_inst = []
for inst in inst_obj:
# 资源总数
count["resource_num"] += 1
if inst.is_interval is True:
# 已开启周期任务的实例
count["has_interval"] += 1
else:
# 未开启周期任务的实例
count["no_interval"] += 1
if hasattr(inst, "latest_poll"):
has_scan_inst.append(inst)
else:
# 资源未扫描
count["no_scan"] += 1
xxx
job_result_obj = JobResultAnalyze.objects.filter(
bk_object_key=check_obj.bk_object_key,
key__in=index_key_list,
is_dimension=False,
).filter(filter_list)
# 正常指标keys
success_keys = set()
# 异常指标keys
error_keys = set()
# 配置差异指标
config_error_set = set()
# 危险和告警指标
danger_set = set()
warning_set = set()
for job_result in job_result_obj:
xxx
# 正常指标
count["success"] = len(set(success_keys) - set(error_keys))
# 配置差异
count["config_error"] = len(config_error_set)
# 危险和警告指标
count["danger"] = len(danger_set)
count["warning"] = len(warning_set)
print((datetime.now() - start).total_seconds())
return count
结果分析:
下图是代码改进后的运行结果。
改进后,查询数据库的次数变成6次(可能还有优化空间),运行时间降低到0.93s

三、总结
从上面的例子可以看出,即使是count这样简单的数据库操作,也是消耗一定的时间的。当一个函数中有大量的count的时候,耗时就变的相当可观。
所以,我们还是要尽量减少操作数据库,有助于提高函数性能。















 2139
2139











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









