







keras代码:
https://blog.csdn.net/u012938704/article/details/79904173
https://github.com/ahangchen/keras-dogs
之前在caffe上实现了两个标签的多任务学习,如今换到了tensorflow,也想尝试一下,总的来说也不是很复杂。
建立多任务图
多任务的一个特点是单个tensor输入(X),多个输出(Y_1,Y_2...)。因此在定义占位符时要定义多个输出。同样也需要有多个损失函数用于分别计算每个任务的损失。具体代码如下:
# GRAPH CODE
# ============
# 导入 Tensorflow
import Tensorflow as tf
# ======================
# 定义图
# ======================
# 定义占位符
X = tf.placeholder("float", [10, 10], name="X")
Y1 = tf.placeholder("float", [10, 20], name="Y1")
Y2 = tf.placeholder("float", [10, 20], name="Y2")
# 定义权重
initial_shared_layer_weights = np.random.rand(10,20)
initial_Y1_layer_weights = np.random.rand(20,20)
initial_Y2_layer_weights = np.random.rand(20,20)
shared_layer_weights = tf.Variable(initial_shared_layer_weights, name="share_W", dtype="float32")
Y1_layer_weights = tf.Variable(initial_Y1_layer_weights, name="share_Y1", dtype="float32")
Y2_layer_weights = tf.Variable(initial_Y2_layer_weights, name="share_Y2", dtype="float32")
# 使用relu激活函数构建层
shared_layer = tf.nn.relu(tf.matmul(X,shared_layer_weights))
Y1_layer = tf.nn.relu(tf.matmul(shared_layer,Y1_layer_weights))
Y2_layer = tf.nn.relu(tf.matmul(shared_layer,Y2_layer_weights))
# 计算loss
Y1_Loss = tf.nn.l2_loss(Y1-Y1_layer)
Y2_Loss = tf.nn.l2_loss(Y2-Y2_layer)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
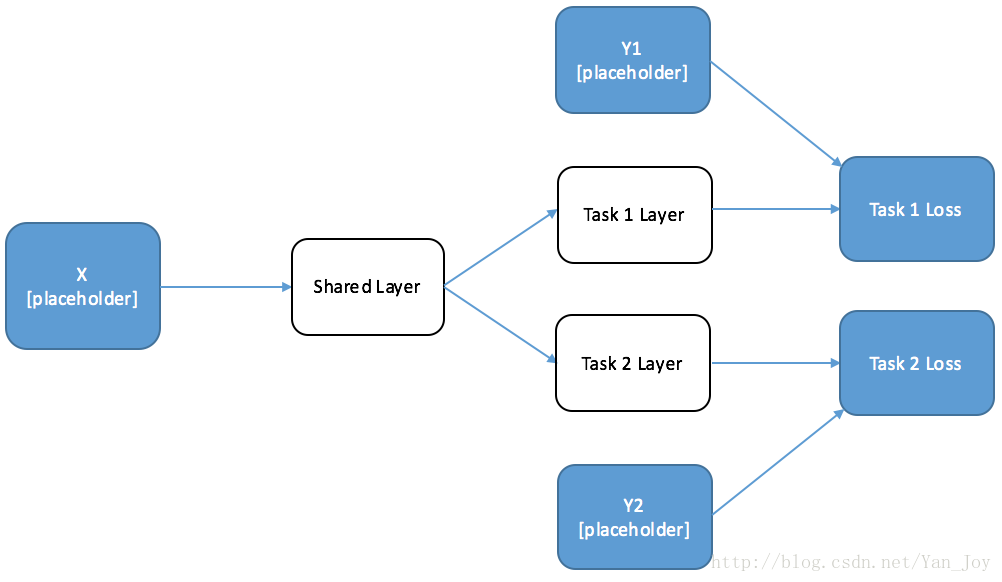
用图表示出来大概是这样的:
Shared_layer的输出分别作为Y1、Y2的输入,并分别计算loss。
训练
有了网络的构建,接下来是训练。有两种方式:
- 交替训练
- 联合训练
下面分别讲一下这两种方式。
交替训练
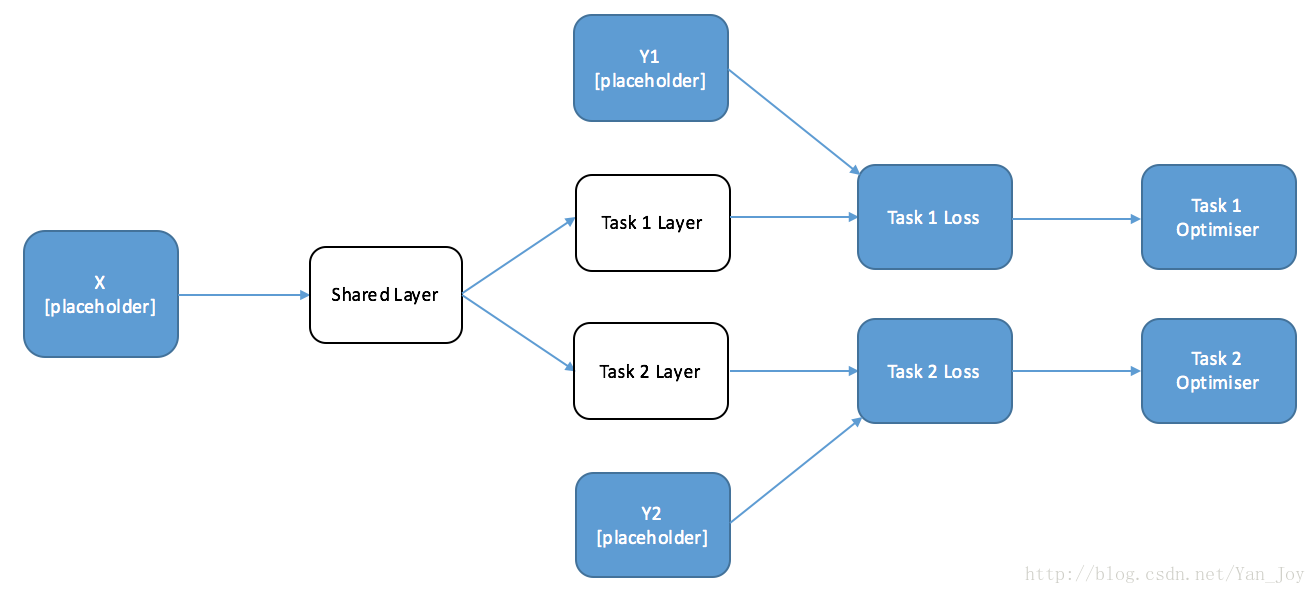
这次先放图,更容易理解:
选择训练需要在每个loss后面接一个优化器,这样就意味着每一次的优化只针对于当前任务,也就是说另一个任务是完全不管的。
# 优化器
Y1_op = tf.train.AdamOptimizer().minimize(Y1_Loss)
Y2_op = tf.train.AdamOptimizer().minimize(Y2_Loss)- 1
- 2
- 3
在训练上面我一开始也有些疑惑,首先是feed数据上面的,是否还需要同时把两个标签的数据都输入呢?后来发现的却需要这样,那么就意味着另一任务还是会进行正向传播运算的。
# Calculation (Session) Code
# ==========================
# open the session
with tf.Session() as session:
session.run(tf.initialize_all_variables())
for iters in range(10):
if np.random.rand() < 0.5:
_, Y1_loss = session.run([Y1_op, Y1_Loss],
{
X: np.random.rand(10,10)*10,
Y1: np.random.rand(10,20)*10,
Y2: np.random.rand(10,20)*10
})
print(Y1_loss)
else:
_, Y2_loss = session.run([Y2_op, Y2_Loss],
{
X: np.random.rand(10,10)*10,
Y1: np.random.rand(10,20)*10,
Y2: np.random.rand(10,20)*10
})
print(Y2_loss)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
由此看来这种方法效率还是有点低。
联合训练
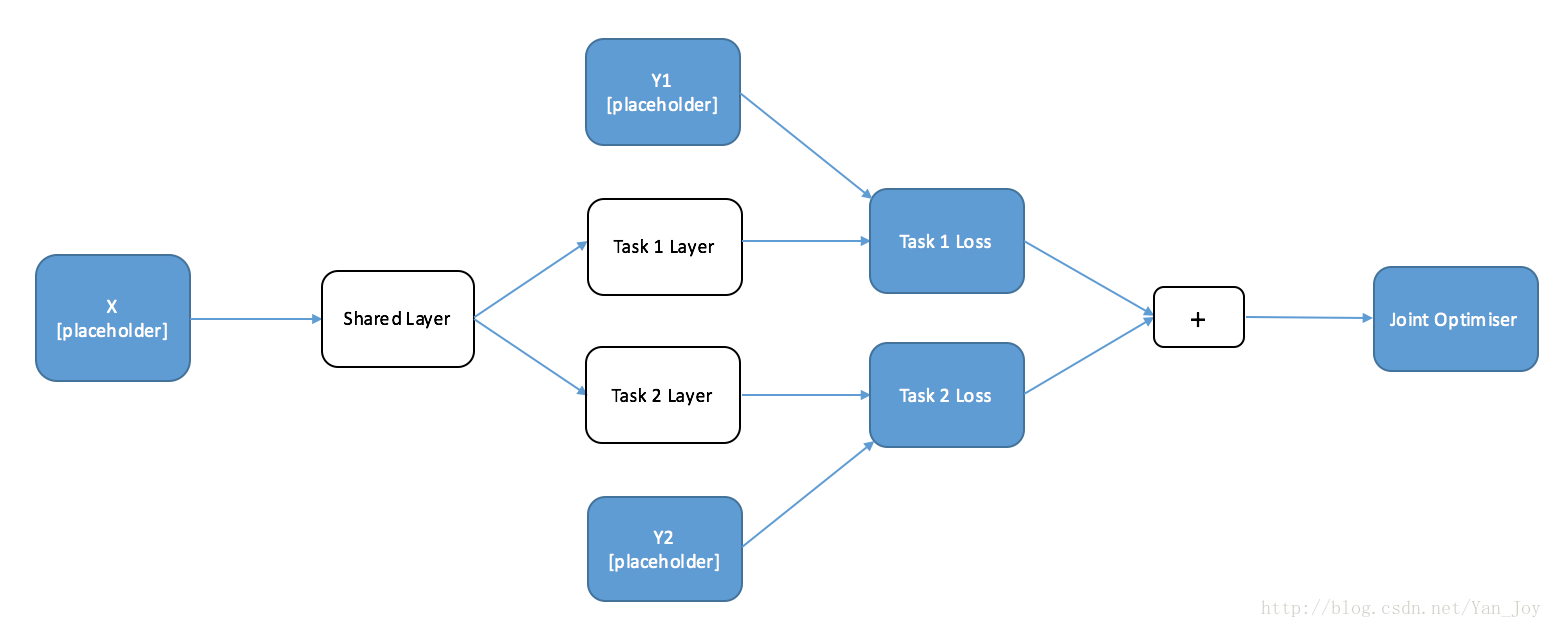
两个优化器需要分别训练,我们把他俩联合在一起,不就可以同时训练了吗?
原理很简单,把两个loss相加即可。得到的图是这样的:
代码:
# 计算Loss
Y1_Loss = tf.nn.l2_loss(Y1-Y1_layer)
Y2_Loss = tf.nn.l2_loss(Y2-Y2_layer)
Joint_Loss = Y1_Loss + Y2_Loss
# 优化器
Optimiser = tf.train.AdamOptimizer().minimize(Joint_Loss)
Y1_op = tf.train.AdamOptimizer().minimize(Y1_Loss)
Y2_op = tf.train.AdamOptimizer().minimize(Y2_Loss)
# 联合训练
# Calculation (Session) Code
# ==========================
# open the session
with tf.Session() as session:
session.run(tf.initialize_all_variables())
_, Joint_Loss = session.run([Optimiser, Joint_Loss],
{
X: np.random.rand(10,10)*10,
Y1: np.random.rand(10,20)*10,
Y2: np.random.rand(10,20)*10
})
print(Joint_Loss)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
这是原文的代码,其中定义的Y1_op和Y2_op并没有使用,应该是多此一举了。
如何选择?
什么时候交替训练好?
Alternate training is a good idea when you have two different datasets for each of the different tasks (for example, translating from English to French and English to German). By designing a network in this way, you can improve the performance of each of your individual tasks without having to find more task-specific training data.
当对每个不同的任务有两个不同的数据集(例如,从英语翻译成法语,英语翻译成德语)时,交替训练是一个好主意。通过以这种方式设计网络,可以提高每个任务的性能,而无需找到更多任务特定的训练数据。
这里的例子很好理解,但是“数据集”指的应该不是输入数据X。我认为应该是指输出的结果Y_1、Y_2关联不大。
什么时候联合训练好?
交替训练容易对某一类产生偏向,当对于相同数据集,产生不同属性的输出时,保持任务的独立性,使用联合训练较好。
这两种方式在实际中也成功实现了,不过目前准确率还不是很高,有待改进。
Multi-Task Learning in Tensorflow: Part 1
multi-task-part-1-notebook














 1198
1198











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









