









目录
描述
Bloom Filter是一种空间效率很高的随机数据结构,它利用位数组很简洁地表示一个集合,并能判断一个元素是否属于这个集合。Bloom Filter的这种高效是有一定代价的:在判断一个元素是否属于某个集合时,有可能会把不属于这个集合的元素误认为属于这个集合(false positive)。因此,Bloom Filter不适合那些“零错误”的应用场合。而在能容忍低错误率的应用场合下,Bloom Filter通过极少的错误换取了存储空间的极大节省。
最近正好用到bloomfilter,所以查询了些资料,整理如下,本文将从原理与数学公式等角度进行讲述,涉及到基本初等函数、微积分与概率论的知识,相关的知识请各位自行获取,本文默认各个读者有一定的数学基础。
算法描述
bloom filter是一个有m bits的bit array,每一个bit位都初始化为0。并且定义有k个不同的hash function,每个都以uniform random distribution将元素hash到m个不同位置中的一个。n为要添加到bloomfilter里面的元素。p为错误率。所以相关的参数为:m n k p(后续详细说明)
很多人说,后端工程师是“添删改查”工程师,那么我也不能免俗,下面从“添删改查”角度来进行阐述:
-
添加过程:首先,用k个hash function将它hash得到bloom filter中k个bit位,之后将这k个bit位置1。
-
查询过程:即判断它是否在集合中,用k个hash function将它hash得到k个bit位。若这k bits全为1,则此元素在集合中;若其中任一位不为1,则此元素比不在集合中
-
删除过程:不允许remove元素,因为那样的话会把相应的k个bits位置为0,而其中很有可能有其他元素对应的位。因此remove会引入false negative,这是绝对不被允许的。
-
修改过程:删除都不允许了,修改更不允许,读者自行脑补吧。
误判率计算和证明
下面高潮来了,用数学公式来进行推倒证明:假设布隆过滤器中的hash function使每个元素都等概率地hash到m个slot中的任何一个,与其它元素被hash到哪个slot无关(独立性)。若m为bit数,则对某一特定bit位在一个元素由某特定hash function插入时没有被置位为1的概率为:

从上式中可以看出,当m增大或n减小时,都会使得误判率减小,这也符合直觉。
现在计算对于给定的m和n,k为何值时可以使得误判率最低。设误判率为k的函数为:

这说明了若想保持某固定误判率不变,布隆过滤器的bit数m与被add的元素数n应该是线性同步增加的。
三 如何设计bloomfilter
首先,需要确定需要add的元素的个数与希望的误差率,这个是整个系统需要输入的参数,其他的参数有系统自动计算,并且建立bloomfilter。

此概率为某bit位在插入n个元素后未被置位的概率。因此,想保持错误率低,布隆过滤器的空间使用率需为50%。
bloomfilter的各个参数的错误率
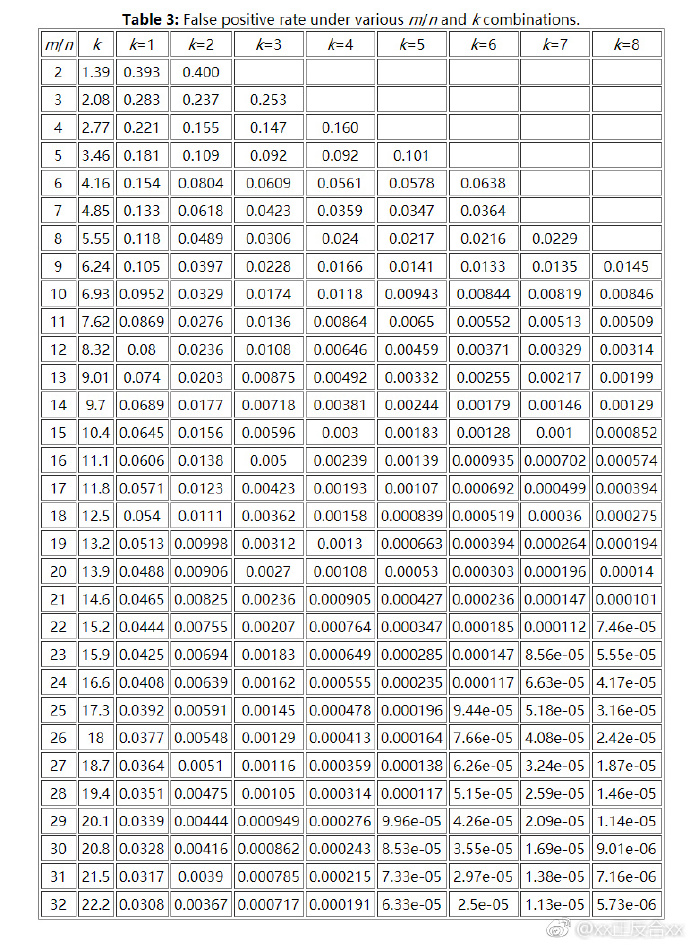
总结
公式推完了,大家可以看看,里面的数学公式基本用到了指数函数 对数函数 微积分求导法则 概率论的知识,大家可以补充看下课本。
参考文章
- http://www.cs.jhu.edu/~fabian/courses/CS600.624/slides/bloomslides.pdf
- http://pages.cs.wisc.edu/~cao/papers/summary-cache/node8.html#SECTION00053000000000000000
自我介绍
个人介绍:杜宝坤,京东联邦学习从0到1构建者,带领团队构建了京东的联邦学习解决方案,实现了电商营销领域支持超大规模的工业化联邦学习解决方案,支持超大规模样本PSI隐私对齐、安全的树模型与神经网络模型等众多模型支持,并且实现了广告侧等业务领域的落地,开创了新的业务增长点,产生了显著的业务经济效益。
个人喜欢研究技术。基于从全链路思考与决策技术规划的考量,研究的领域比较多,从架构、数据到算法与算法框架均有涉及。欢迎喜欢技术的同学和我交流,邮箱:baokun06@163.com















 137
137











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









