






一 背景
最近总结自己的公众号的时候,发现一个问题:对于联邦学习的文章,基本都是在讲述纵向联邦学习,对于横向联邦学习的技术涉及较少,所以心血来潮之下,决定写几篇文章来压压箱子底。
❝横向联邦:现代移动设备可以访问大量适合学习模型的数据,这些数据反过来可以大大提高设备上的用户体验。例如,语言模型可以提高语音识别和文本输入,图像模型可以自动选择好的照片。然而,这些丰富的数据通常是隐私敏感的、数量很大的,或者两者兼有,这可能会阻止记录到数据中心并使用常规方法在那里进行分析训练。
❞
所以针对于此研发人员设计了一种新的模式,即让训练数据分布在移动设备上,并通过聚集本地计算的更新来学习共享模型。我们将这种模式称为联邦学习。
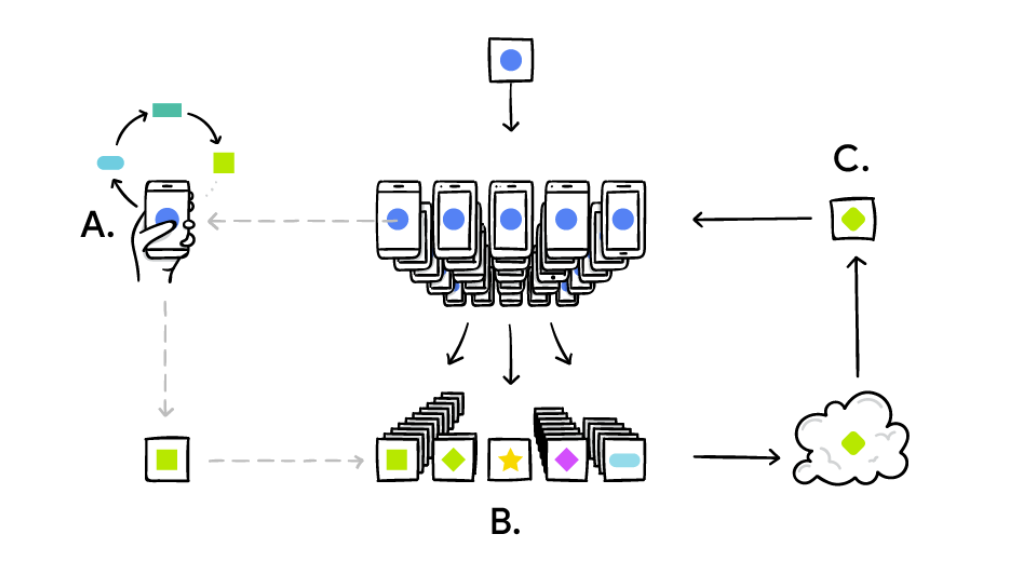
二 横向联邦学习 VS 纵向联邦学习
联邦学习主要分为三大类:横向联邦学习、纵向联邦学习、联邦迁移学习等。
-
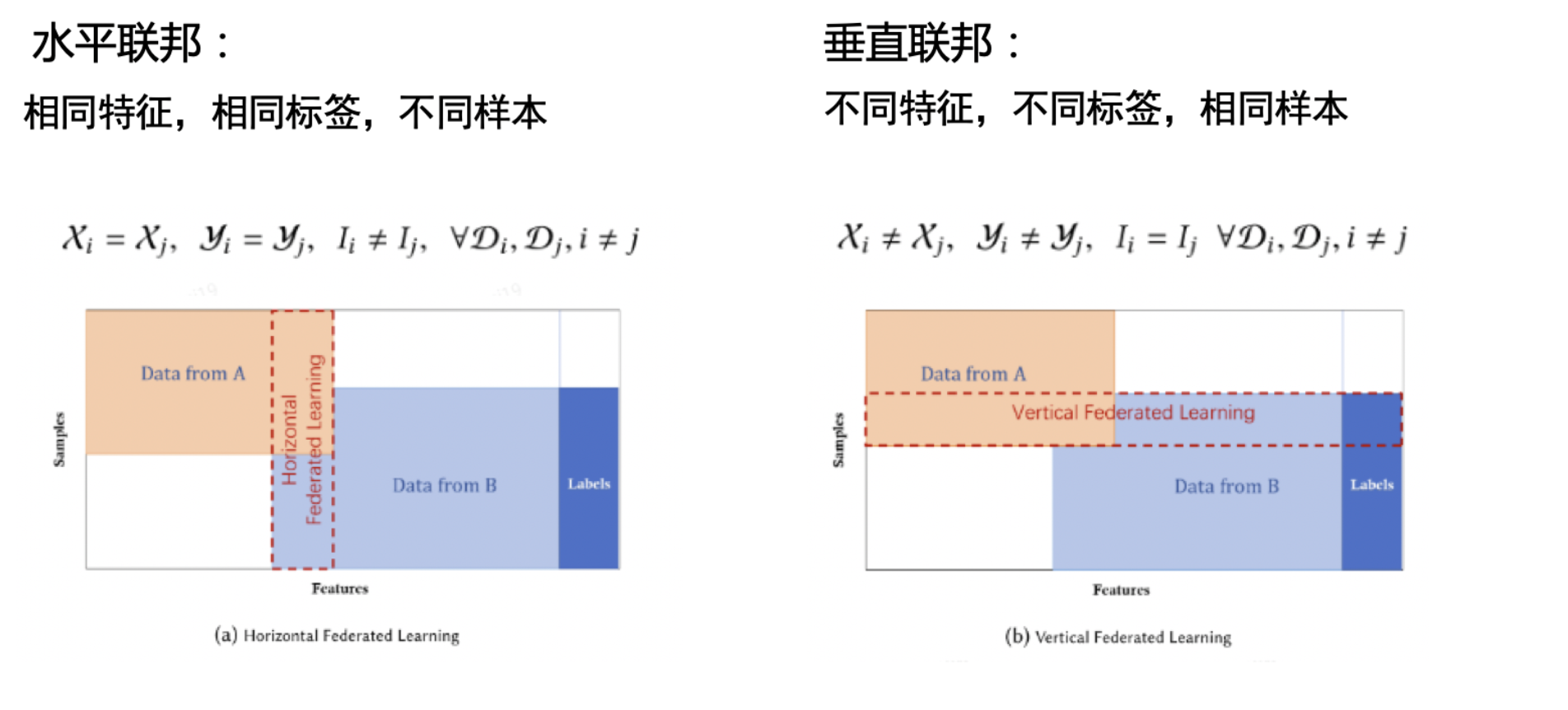
横向联邦学习:谷歌输入法案例,就是一个比较典型的横向联邦学习的案例。它的特点是各个参与方数据的特征维度是相同的,但是样本ID不同。适用于银行之间以及手机终端边缘计算等同质数据场景。 -
纵向联邦学习:它的特点是数据样本ID基本相同,特征不同。比如两个数据集的用户大规模重叠,但它们的特征不一样,双方可以进行样本拼接,继而联合训练一个模型,提升业务效果。
三 横向联邦学习面临的挑战
横向联邦学习面临较多的挑战,大致总结如下:
-
设备的异构性,不稳定; -
通信网络的异构性、不稳定、不可靠; -
数据的异构性,Non IID问题(云端数据与机器非私有隶属关系,可以通过Global Shuffle解决); -
框架的算法效率,通信的频率等; -
训练过程中的隐私性;

本篇文章在上篇文章《横向联邦学习-安全聚合算法》的基础上,继续进行展开,详细的描述下,如何进行安全、高效、可靠的横向联邦学习。
四 横向联邦学习的安全问题
在上一篇文章中,我们介绍了横向联邦学习的两种模型更新的方式:
-
FedSGD -
FedAVG
❝上面介绍的两个算法,所有的梯度、参数等都是通过明文的形式传递的,所以存在泄露问题,下面我们就介绍下梯度泄露;
❞
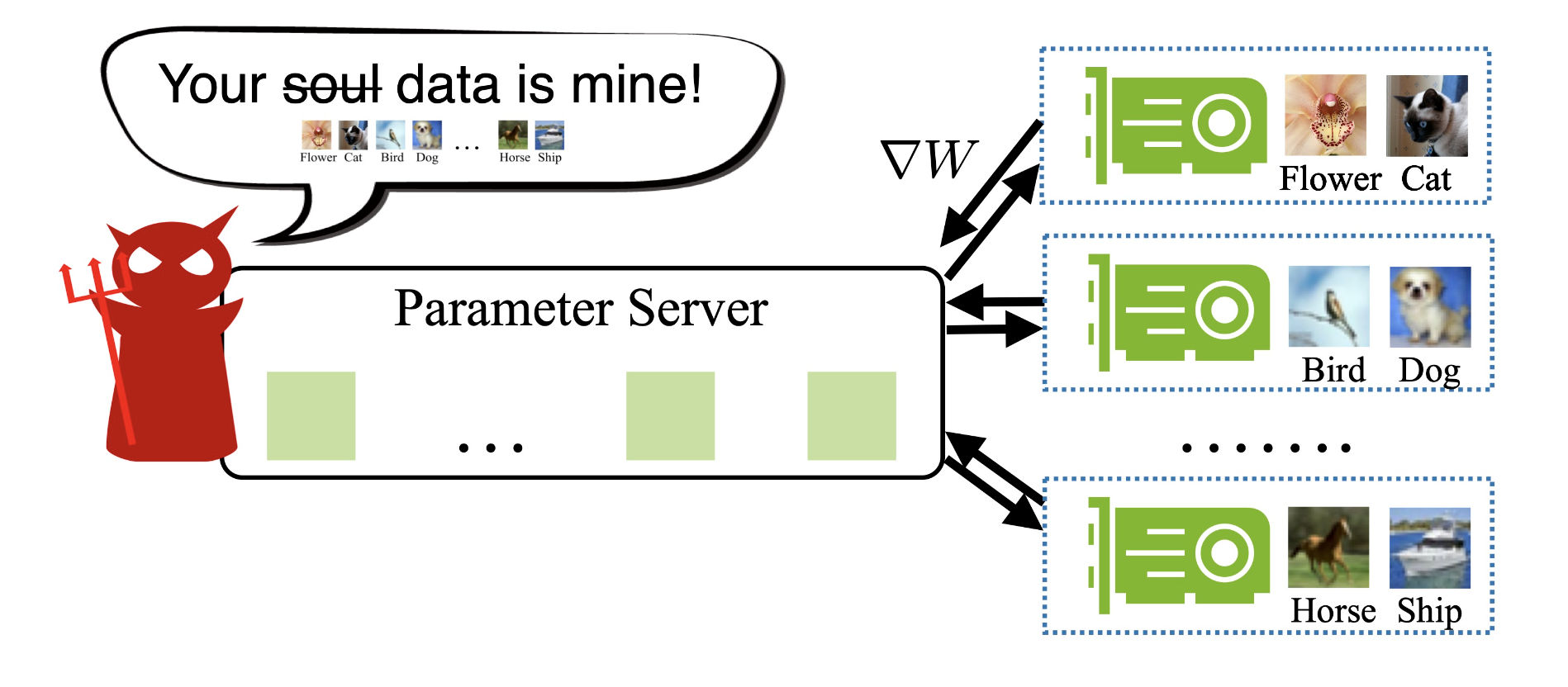
梯度会泄露用户的个人信息,在NeurIPS 2019中,《Deep Leakage from Gradients》一文指出,从梯度可以推断出原始的训练数据,包括图像和文本数据。
其中报道了一个用20行基于PyTorch核心代码的样例,运用GAN的思想,让分布式训练中的一个攻击方可以从整个模型更新梯度的过程中,通过减少梯度差异的方式,不断生成与其他参与各方相同的数据,从而实现『偷取』数据。
-
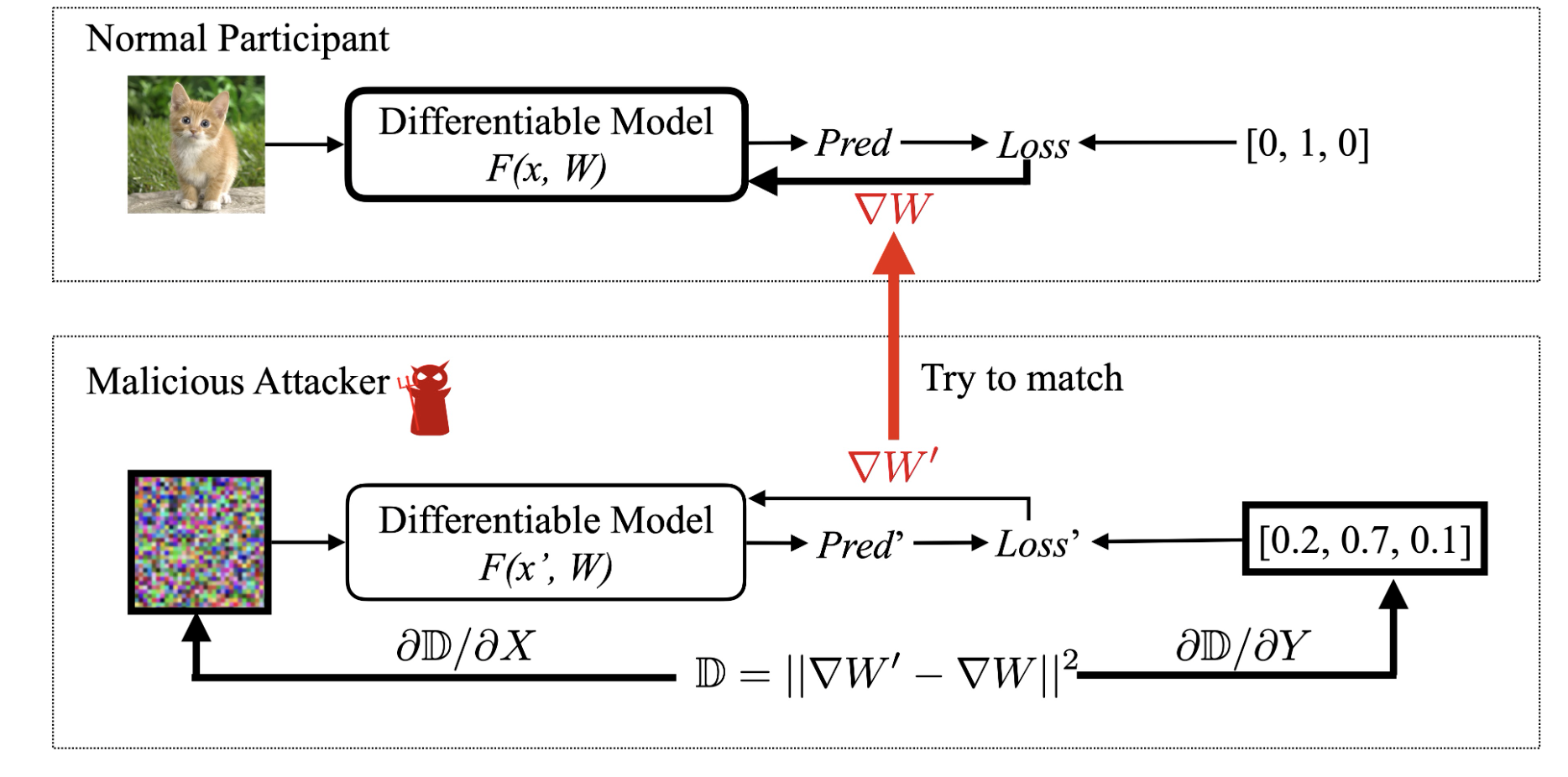
Deep Leakage by Gradient Matching
-
其核心算法是匹配虚拟数据和真实数据之间的梯度。在PyTorch中,不到20行就可以实现它!
def deep_leakage_from_gradients(model, origin_grad):
dummy_data = torch.randn(origin_data.size())
dummy_label = torch.randn(dummy_label.size())
optimizer = torch.optim.LBFGS([dummy_data, dummy_label] )
for iters in range(300):
def closure():
optimizer.zero_grad()
dummy_pred = model(dummy_data)
dummy_loss = criterion(dummy_pred, dummy_label)
dummy_grad = grad(dummy_loss, model.parameters(), create_graph=True)
grad_diff = sum(((dummy_grad - origin_grad) ** 2).sum() \
for dummy_g, origin_g in zip(dummy_grad, origin_grad))
grad_diff.backward()
return grad_diff
optimizer.step(closure)
return dummy_data, dummy_label
-
在视觉图片上的实验效果
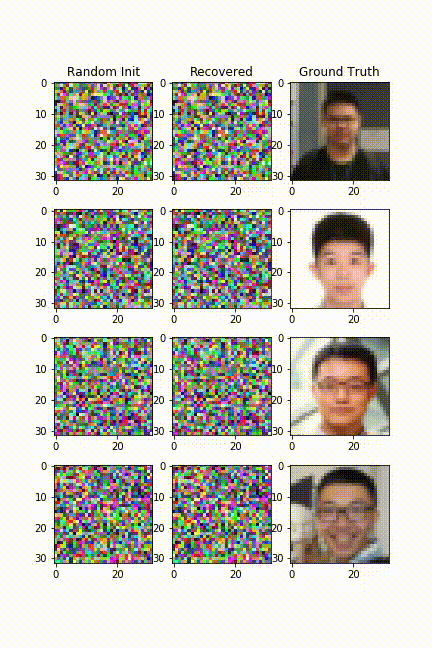
-
在语言模型上的实验效果
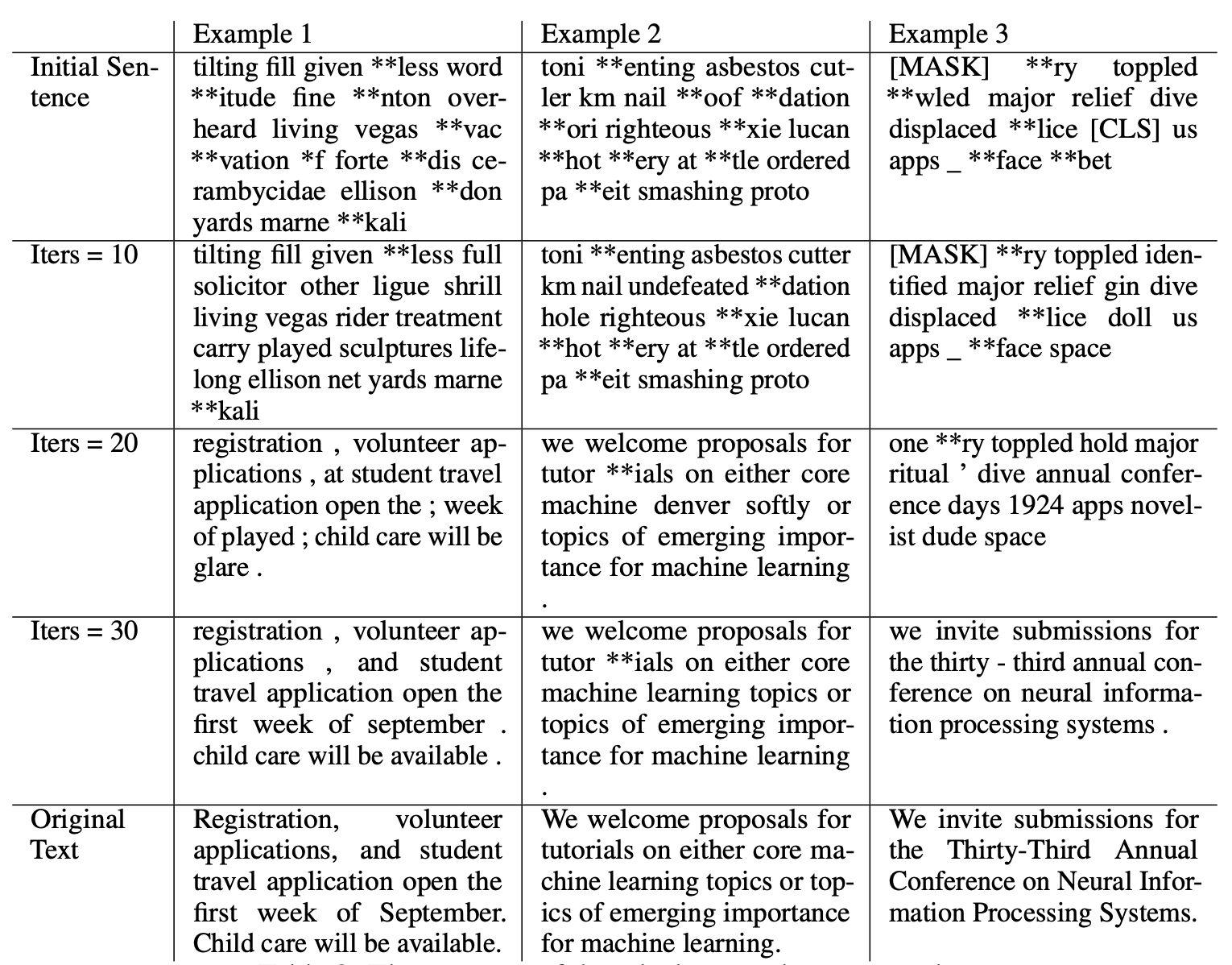
五 前置知识
其实严格的从时间轴上来说,《Deep Leakage from Gradients》出现的相对滞后,在2017年谷歌已经提出了横向联邦学习的安全的模型聚合方法。
❝但是其实早在2017年,谷歌的Bonawitz等发表了《Practical Secure Aggregation for Privacy-Preserving Machine Learning》这篇文章,详细阐述了针对梯度泄露攻击设计的Secure Aggregation协议,我们简称为SMPC.
❞
-
前置知识
-
秘密分享(Secret Sharing):可以参考我专栏里面的文章, 隐私计算基础组件系列-秘密分享。 -
DH密钥交换(Key Agreement):可以参考我专栏里面的文章, 隐私计算加密技术基础系列-Diffie–Hellman key exchange。 -
认证加密(Authenticated Encryption):可以参考我专栏里面的文章, 隐私计算加密技术基础系列(上) 系列 -
伪随机数生成器(Pseudorandom Generator) -
「数字签名」(Signature Scheme ): 隐私计算加密技术基础系列(下)对称与非对称加密的应用场景
❝下面我们再简单分享下秘密分享和DH秘钥交换,这里只做简单的介绍,如果有需要详细了解这两个知识点内容的同学,请移步到上面的链接。
❞
5.1 秘密分享
5.1.1 广义介绍
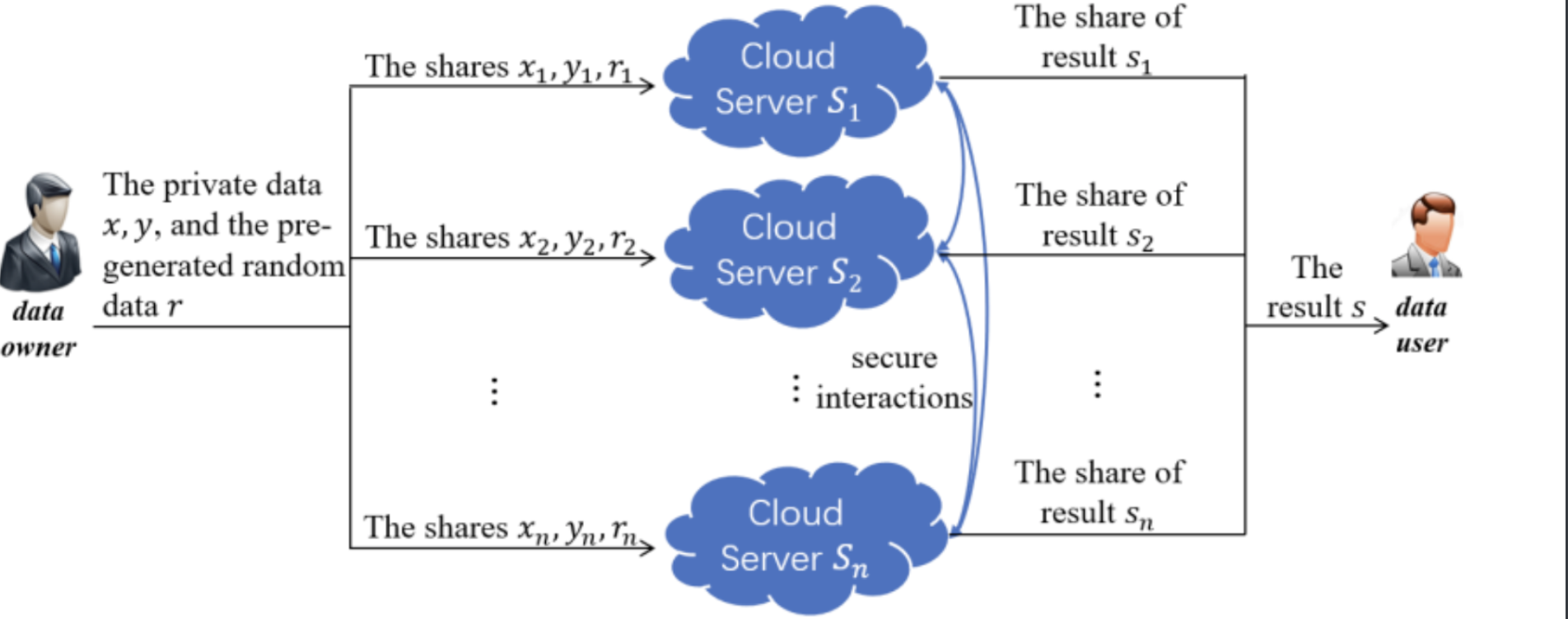
下面简单介绍下秘密分享,有想全面了解的,请移步 隐私计算基础组件系列-秘密分享
主要是介绍阈值秘密分享,阈值秘密分享的基本思路是,基于秘密分享的便携性与安全性的考量,如果有个n个秘密分片,我们只需要凑齐 k( 1 < K <n )个人,他们手中的信息拼凑起来,就可以获取秘密。
那么如何才能做到这点呢?有以下几个问题需要考虑;
-
随机性:挑选的k个人,需要是随机挑选的k个人,不能是一个固定的选取。 -
必然性:随机选出的这k个人,必须能需要的数字进行解密。
那么,是什么样的技术可以实现呢?
大家还记得学习《线性代数》的时候吧,在线性代数的课上,k个参与者,相当于k个变量,那么需要k个方程就才可以解出来。
❝「计算逻辑」
❞
秘密数字:D;
参与方:n个参与者,
一个大的素数:p,约束这个素数要大于D和n
-
首先,构造出n个方程式,构造公式 ,这个公式是从文章How to Share a Secret里面分析的,说白了就是多项式,列举如下:
-
公式展开:
-
公式举例(假设k为3,n为10)
a_0 = D$;
a_0 = D$;
......
a_0 = D$;
-
-
然后,目前的方程组里面,还有 的(k-1)个变量,那么这几个变量如何获取呢?根据Adi Shamir在ACM发布的《How to Share a Secret 》的描述, The coefficients in q(x) are randomly chosen from a uniform distribution over the integers in [0, p), 也就是说在[0,p)的范围内均匀分布中进行获取。
-
然后,原始文章中也对 进行了约束是大素数的取模,不过这理解这个大素数的p的作用更多是控制我们选择 的大小的,防止数据的过于膨胀;(唯一解的问题,在构造的时候基本可以规避,大家可以自行证明,提示一下:系数行列式不等于零);
-
最后,将这个n个方程划分给n个参与者。需要计算的时候,只需要将k个方程获取进行联合计算就可以计算出a也就是秘密D。
❝「案例介绍」
❞
下面通过一个案例,介绍下基于多项式的阈值秘密分享。
-
输入
-
秘密数字:D = 88 -
参与方:10个, -
大素数:991 -
解密阈值:3
-
-
加密逻辑
-
首先,生成方程组
,其中 ;
,其中 ;
......
,其中 ;
-
然后,基于素数生成 的值,设定 ,则方程组如下,并且
,其中 ;
,其中 $;
......
,其中 ;
-
然后,可见 都小于我们设置的素数991,符合预设,所以将这10个方程分布分发到10个参与者分片Server。
-
-
解密逻辑
-
首先,假设抽取参与者1,2, 10的方程组成方程组进行解密,则方程组如下:
-
最后,求解这个方程组,则 ,则解出秘密D。
-
5.1.2 本文使用方法
在本文中,我们使用如下的公式「分享秘密」,
使用 分享秘密,其中s代表要分享的秘密,分成n份(集合U的大小|U|=n),需要至少t个用户进行秘密的恢复(具体流程参见上面,n个多项式,最少t个可以求解),所以集合V的大小 。
「恢复秘密:」
。使用 来恢复秘密,其中因为 ,所以根据上面秘密分享的描述,是可以通过t个用户来恢复出秘密的。
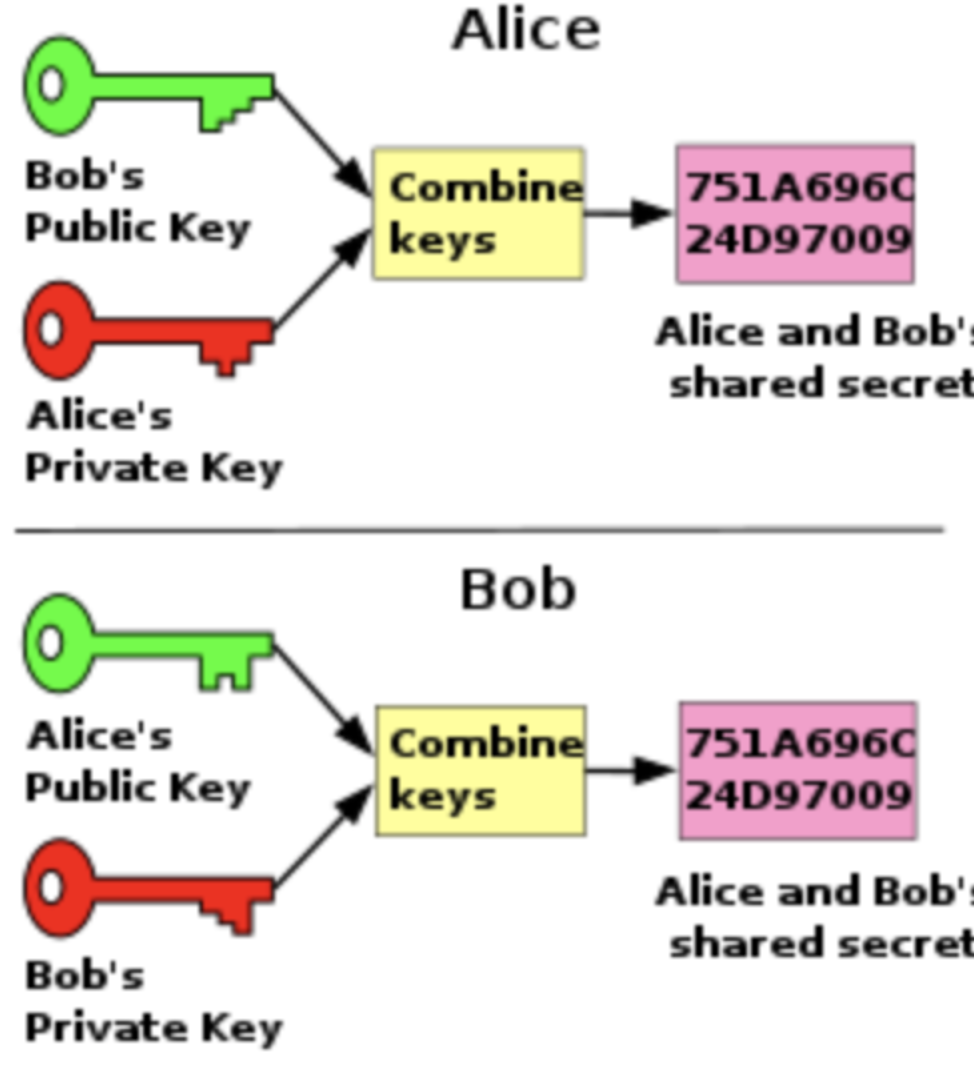
5.2 简单介绍下DH秘钥交换
5.2.1 广义介绍
下面先简单介绍下DH秘钥交换,有想全面了解的,请移步 隐私计算加密技术基础系列-Diffie–Hellman key exchange
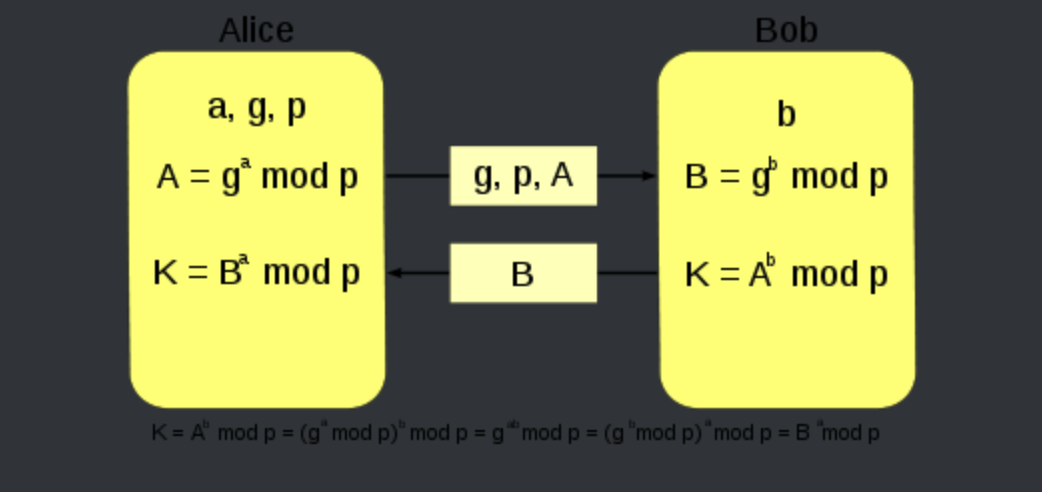
最简单,最早提出的这个协议使用一个质数p的整数模n乘法群以及其原根g。下面展示这个算法,绿色表示非秘密信息,「红色粗体」表示秘密信息:
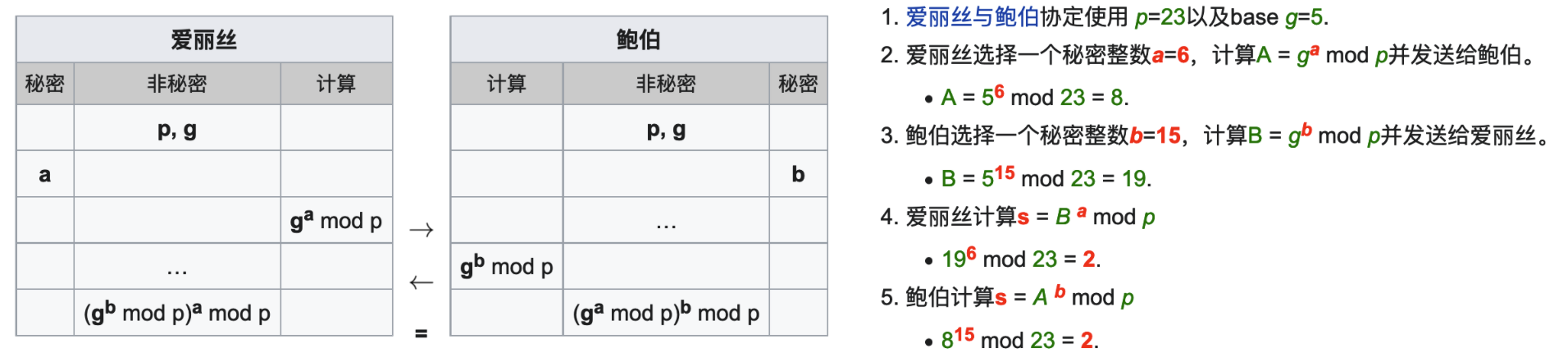
由上面的流程可以看到,Alice和Bob最终都得到了同样的值,因为在模p的情况下 相等。注意 是秘密的。
5.2.2 本文使用方法
这里我们描述下一个具体的实现方案,可能与我们上面的实现稍有差异。
首先,我们定义交互的双方为我们的老朋友,Alice和Bob。秘钥交换的本质目标是使双方能够用于一个私有的秘钥进行安全的通信,这个秘钥只有Alice和Bob知道,那么我们总结下基本步骤如下:
-
第一步,Alice和Bob定义好公共的参数,一个大素数P和一个原根g,这一步我们用公式表示如下: ,H为哈希函数。 -
第二步,基于定义好的公共函数,双方各自生成用户生成最终秘钥的中间秘钥数据: ; -
第三步,双方互发 -
第四步,计算后续通信的秘钥, ,用公式表示为, ,并且由于 ,双方完成秘钥的协商。
5.3 认证加密
这块可以参考下,上面给出的我的公众号的连接,简单的说就是加密解密,公式如下:
AE.dec(c,AE.enc(c,x)) = x
5.4 伪随机数生成器
这块我没看的十分理解,说下自己的看法,这个随机数生成应该和种子有很大的关系,所以这样才能在后面的客户端掉线后进行恢复,因为论文中提供的秘钥分享与每个用户加的随机数其实是有diff的。
5.5 数字签名
5.5.1 广义介绍
前面的客户端证书链保障了证书的合法性,里面用到了数字签名的技术,那么数字签名到底是个什么技术,又是如何在这里面起到作用呢?
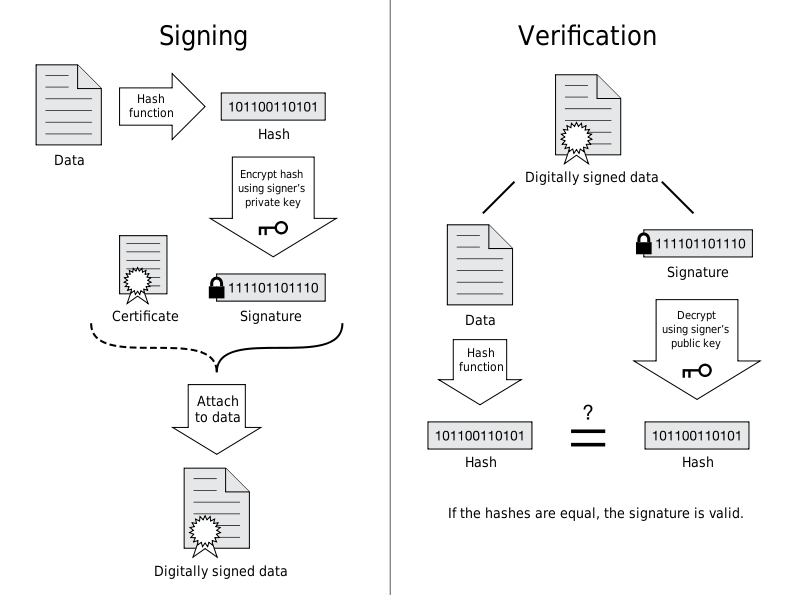
❝数字签名就是附加在数据单元上的一些数据,或是对数据单元所作的密码变换。这种数据或变换允许数据单元的接收者用以确认数据单元的来源和数据单元的完整性并保护数据,防止被人(例如接收者)进行伪造。它是对电子形式的消息进行签名的一种方法,一个签名消息能在一个通信网络中传输。基于公钥密码体制和私钥密码体制都可以获得数字签名,主要是基于公钥密码体制的数字签名。
❞
数字签名是个加密的过程,数字签名验证是个解密的过程。
-
数字证书签名生成的步骤:
-
第一步,获取撰写证书的元信息:签发人、地址、签发时间、过期失效等等;
-
第二步,通过通用的hash算法将信息摘要提取出来,比如sha1或者md5;
-
第三步,Hash摘要通过签发者的私钥进行非对称加密,生成一个签名密文;
-
最后一步,将签名密文attach到文件证书上,使之变成一个签名过的证书。
-
-
数字证书签名验证的步骤:
-
第一步,浏览器获得服务端从CA签发的证书; -
第二步,将其解压后分别获得“元数据”和“签名密文”; -
第三步,将同样的Hash算法应用到“元数据”生成摘要信息; -
最后一步,将证书“密文签名”通过公钥(非对称算法)解密获得同样的摘要值,并且进行对比,同时也可以与客户端证书链里面的签名摘要信息对比。
-
5.5.2 本文使用方法
主要介绍下本文使用的公式,主要是有三个:SIG.gen,SIG.sign,SIG.ver;
-
秘钥的生成: ,其中 ; -
使用签名算法(私钥加密)对一段明文进行签名: ; -
使用公钥进行校验: ,验证成功是1,失败为0;
六 横向联邦学习的参数更新机制
❝但是其实早在2017年,谷歌的Bonawitz等发表了《Practical Secure Aggregation for Privacy-Preserving Machine Learning》这篇文章,详细阐述了针对梯度泄露攻击设计的Secure Aggregation协议。
❞
-
「整体流程如下」

6.1 初始阶段
-
首先,针对所有的客户端,确定几个公共的参数; -
用于秘密分享的参数,用户数n、秘密分享的阈值t; -
用户DH秘钥交换的参数k, ; -
用户与服务端进行交互的参数空间的大小m;
-
-
然后,针对所有的客户端,分别与服务端之间有一个经过认证的安全通道; -
然后,针对所有的客户端,从可信的第三方获取一对非对称秘钥对 ;
6.2 第0轮(广播 Keys)
-
对于客户端u
-
根据DH秘钥交换,生成两对秘钥 ; -
生成一个签名: ; -
将两个公钥、一个签名 ,通过经过认证的安全通道发送方到服务端;
-
-
对于服务端
-
收集客户端的信息,并且判断收集到的客户端的数量是否小于t,如果小于则终止。同时将本次收到的客户端的集合定义为 ; -
向本次收集到的客户端的集合 广播其他客户端的标识ID、两个公钥、一个签名 ;
-
6.3 第1轮(分享秘密)
-
对于客户端u
-
验证阶段:收到来自服务端的广播信息 -
首先,验证 ,保证秘密分享的阈值要求,否则终止算法; -
然后,针对收集到的其他的客户端的消息进行验证,即 ,否则终止算法;
-
-
扰动生成阶段:读过上文的同学应该了解,我们是生成两组掩码(分别称之为交互掩码与自身掩码),继而进行秘密分享 -
随机抽样一个随机数 ,用于PRG随机数生成器的种子。 -
交互掩码的秘密分享: -
自身掩码的秘密分享: -
生成针对每个客户端的扰动项,并且通过服务端发送给客户端(发送服务端的时候,会说明是要中转到哪个具体的客户端ID的) ; -
存储本轮生成和收到的所有的信息;
-
-
-
对于服务端
-
验证阶段:检查收到的客户端消息是否小于t,如果小于则终止算法,同时将本次收到消息的客户端结合标记为 ,这里 ; -
广播阶段:将收集到的 分别广播给对应的客户端;
-
6.4 第2轮(计算信息掩码、进行扰动,发送服务端聚合消除)
-
对于客户端u
-
验证阶段:收到来自服务端的广播消息:其他客户端对应本客户端的 ,并且得到集合 。如果 则继续,否则终止。
-
掩码计算阶段:计算信息掩码
-
计算交互掩码:针对每个客户端u,计算它与所有其他客户端的交互掩码,计算逻辑如下,首先通过秘钥协商获得秘钥, ,然后将这个秘钥作为伪随机数生成器PRG的种子,并且生成与传递给服务端的参数(梯度)相同尺寸的向量,作为掩码向量,向量的符号计算如下: ,当 ,当 ,(注意 ),同时 ; -
计算自身掩码:针对每个客户端端u,计算其自身掩码,计算逻辑如下,首先,通过 计算伪随机数生成 ;
-
-
真值加掩码阶段:将将要与服务端传递的真值加上交互掩码与自身掩码,公式如下
-
上述流程如果任何一步出现问题,则终止算法。如果均成功,将生成结果传递给服务端。
-
-
服务端
-
验证阶段:检查收到的客户端消息是否小于t,如果小于则终止算法,同时将本次收到消息的客户端结合标记为 ,这里 ;
-
6.5 第3轮(二次检查,主要为了防止有掉线的客户端以及冒充)
-
对于客户端u -
验证阶段:收到来自服务端的广播消息集合 ,并且判断 是否大于t,如果小于t则终止算法; -
签名阶段:针对集合 使用数字签名进行签名: ,并且发送给服务端;
-
-
对于服务端 -
验证阶段:检查收到的客户端消息是否小于t,如果小于则终止算法,同时将本次收到消息的客户端结合标记为 ,这里 ,并且针对集合中的每个用户,发送签名信息到集合 ;
-
6.6 第4轮(汇聚信息并解密)
-
对于客户端u
-
签名阶段:收到来自服务端的签名消息 ,进行确认 ,并且需要满足秘密分享的阈值t,接着进行签名的校验 对于所有的 ,防止服务端对于客户端进行欺骗。 -
解析分享秘密阶段:针对在 中除了u的所有客户端v,使用秘钥解密加密过的数据 ,得到四个结果,并且进行验证是否满足 ,如果不满足则可能是设备已经下线或者发错消息。 -
如果任何解密操作失败(特别是,密文没有正确验证),则终止。 -
同时将得到的两个分享的秘密发送给服务,对于掉线的客户端 ,发送交互掩码 ,对于正常客户端 ,则发送自身掩码
-
-
对于服务端
-
验证阶段:检查收到的客户端消息是否小于t,如果小于则终止算法(这时候用户集合定义为 );
-
异常处理
-
对于正常的客户端,即 ,使用秘钥分享聚合出自身掩码就好,即 ,送入伪随机数生成器PRG计算出对应客户端的 ; -
对于掉线的客户端,即 ,使用秘密分享聚合出交互掩码,即恢复出 ,送入伪随机数生成器PRG计算出其针对其他客户端的 。
-
-
最后的数据聚合
-
七 参考资料
-
Deep Leakage from Gradients -
Secure Analytics: Federated Learning and Secure Aggregation -
Federated Learning of Deep Networks using Model Averaging -
Practical Secure Aggregation for Privacy-Preserving Machine Learning
八 番外篇
❝个人介绍:杜宝坤,隐私计算行业从业者,从0到1带领团队构建了京东的联邦学习解决方案9N-FL,同时主导了联邦学习框架与联邦开门红业务。 框架层面:实现了电商营销领域支持超大规模的工业化联邦学习解决方案,支持超大规模样本PSI隐私对齐、安全的树模型与神经网络模型等众多模型支持。 业务层面:实现了业务侧的开门红业务落地,开创了新的业务增长点,产生了显著的业务经济效益。 个人比较喜欢学习新东西,乐于钻研技术。基于从全链路思考与决策技术规划的考量,研究的领域比较多,从工程架构、大数据到机器学习算法与算法框架均有涉及。欢迎喜欢技术的同学和我交流,邮箱:「baokun06@163.com」
❞
九 公众号导读
自己撰写博客已经很长一段时间了,由于个人涉猎的技术领域比较多,所以对高并发与高性能、分布式、传统机器学习算法与框架、深度学习算法与框架、密码安全、隐私计算、联邦学习、大数据等都有涉及。主导过多个大项目包括零售的联邦学习,社区做过多次分享,另外自己坚持写原创博客,多篇文章有过万的阅读。公众号「秃顶的码农」大家可以按照话题进行连续阅读,里面的章节我都做过按照学习路线的排序,话题就是公众号里面下面的标红的这个,大家点击去就可以看本话题下的多篇文章了,比如下图(话题分为:一、隐私计算 二、联邦学习 三、机器学习框架 四、机器学习算法 五、高性能计算 六、广告算法 七、程序人生),知乎号同理关注专利即可。

一切有为法,如梦幻泡影,如露亦如电,应作如是观。
本文由 mdnice 多平台发布

















 1433
1433

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









