







白话机器学习-逻辑斯蒂回归-理论篇
@(2018年例会)
概述
前面讲述了线性回归,线性回归的模型 y=wT+b 。模型的预测值逼近真实标记y。那么可否令模型的预测值逼近真实标记y的衍生物呢。比如说模型的预测值逼近真实标记的对数函数。下面引入逻辑回归的知识。
转换函数
我们需要一个单调可微函数将分类任务的真实标记y与线性回归模型的预测值联系起来,所以需要一个转换函数将线性模型的值与实际的预测值关联起来。
考虑二分类问题,其输出标记是y属于{0,1},而线性模型产生的预测值是 z=wT+b 是实值,那么我们需要将这个实值转化成0/1值,最理想的函数是单位阶跃函数。
单位阶跃函数
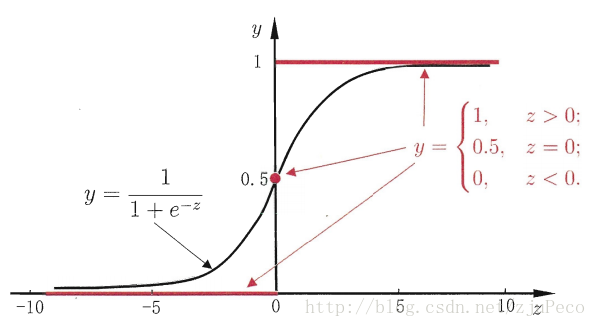
单位阶跃函数(unit-step function),如下图,如果预测值大于零则判断为正例;如果预测值小于零则判断为反例;为零的则任意判断。如下图所示。

sigmoid function
从图中可以看出,单位阶跃函数不连续因此不适合用来计算。这里我们引入sigmoid函数,进行计算。
y=11+e−z将z值转化为一个接近0或1的y值,并且其输出值在z=0的附近变化很陡。那么我们现在的模型变化成
几率与对数几率
几率:如果将y作为正例的可能性,1-y作为负例的可能性,那么两者的比值 y1−y 称为几率,反应了x作为正例的相对可能性。则根据sigmoid函数可得。
lny1−y 称为对数几率;
由此可以看出, y=11+e−(wT+b) 实际上是用线性模型的预测结果去逼近真实标记的对数几率,因此,其对应的模型称为“对数几率回归”
下面介绍损失函数以及计算方法。
损失函数
因为: lny1−y=wT+b 。所以
我们采用极大似然估计法进行求解,由于是二分类问题,所以符合概率里面的0-1分布,所以似然函数为
令 p(y=1|x)=e(wT+b)1+e(wT+b)=f(x) , p(y=0|x)=11+e(wT+b)=1−f(x)
对数似然函数为:
求这个函数的最大值,加个负号,求最小值。运用前面章节介绍的梯度下降和牛顿法都可以求解,这里不再赘述。















 1352
1352

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









