









基础
state的分类
key state和operate state
state 的重分布
Flink状态管理详解:Keyed State和Operator List State深度解析 - 掘金
checkpoint 和save point
https://zhuanlan.zhihu.com/p/79526638
flink job 的容错策略
如果在没有持续消息输出的情况下,如何定时输出
主要是现实有可能不会一直有消息输入,但是要定时输出的情况
@Override
public void processElement(
Tuple2<String, String> value,
Context ctx,
Collector<Tuple2<String, Long>> out) throws Exception {
// retrieve the current count
CountWithTimestamp current = state.value();
if (current == null) {
current = new CountWithTimestamp();
current.key = value.f0;
}
// update the state's count
current.count++;
// set the state's timestamp to the record's assigned event time timestamp
current.lastModified = ctx.timestamp();
// write the state back
state.update(current);
// schedule the next timer 60 seconds from the current event time
// 这里注册一个timer
ctx.timerService().registerEventTimeTimer(current.lastModified + 60000);
}
@Override
public void onTimer(
long timestamp,
OnTimerContext ctx,
Collector<Tuple2<String, Long>> out) throws Exception {
// get the state for the key that scheduled the timer
CountWithTimestamp result = state.value();
// check if this is an outdated timer or the latest timer
if (timestamp == result.lastModified + 60000) {
// emit the state on timeout
out.collect(new Tuple2<String, Long>(result.key, result.count));
//每次发送一个消息后,再注册一个timer
ctx.timerService().registerEventTimeTimer(current.lastModified + 60000);
}
}state backend 有哪几类
-
HashMapStateBackend:
- 默认状态后端,适用于大多数情况。
- 状态数据作为 Java 对象存储在 JVM 堆上。
- 适用于大型状态、长窗口、大型键值状态的作业。
- 推荐在高可用性设置中使用。
- 建议将管理内存设置为零,以确保 JVM 上用户代码的最大内存分配。
-
EmbeddedRocksDBStateBackend:
- 将数据存储在 RocksDB 数据库中,通常存储在 TaskManager 的本地数据目录。
- 数据以序列化的字节数组形式存储,而不是 Java 对象。
- 支持异步快照,适合需要大量状态和长窗口的大型作业。
- 由于 RocksDB 的 JNI 桥接 API 基于 byte[],每个键和值的最大支持大小为 2^31 字节。
- 支持增量快照,可以减少检查点时间,提高恢复速度。
-
选择正确的状态后端:
- HashMapStateBackend 提供快速的访问和更新,但状态大小受限于集群内的可用内存。
- EmbeddedRocksDBStateBackend 可以根据可用磁盘空间扩展,是唯一支持增量快照的状态后端,但性能可能较慢。
-
配置状态后端:
- 默认情况下,如果未指定其他配置,Flink 会使用 HashMapStateBackend。
- 可以在 Flink 配置文件中设置默认状态后端,也可以在每个作业中单独设置。
-
RocksDB 状态后端细节:
- 支持增量快照,可以减少检查点时间。
- 内存管理:Flink 默认配置 RocksDB 的内存分配,以确保 TaskManagers 的内存使用在环境限制内。
- 定时器(Heap vs. RocksDB):默认情况下,即使使用 RocksDB 存储其他状态,定时器也存储在 RocksDB 中。可以选择将定时器存储在 JVM 堆上。
-
高级配置:
- 可以手动控制 RocksDB 的内存分配,通过配置 RocksDBOptionsFactory。
- 可以启用 RocksDB 的原生指标,但可能会对性能产生负面影响。
-
变更日志(Changelog):
- 旨在减少检查点时间,提高端到端延迟。
- 通过持续上传状态变化形成变更日志,检查点时只需上传相关部分。
- 支持从保存点和检查点恢复。
如果我用的EmbeddedRocksDBStateBackend,为啥还要配置checkpoint目录
-
检查点数据存储:检查点是 Flink 用于确保流处理作业容错性的关键机制。当启用检查点时,Flink 会定期保存作业的状态快照。这些快照包括了作业的当前状态信息,如键值状态、窗口状态、定时器等。即使状态数据存储在 RocksDB 中,检查点的元数据和可能的状态快照(如增量快照)仍然需要被保存到文件系统中。
-
恢复和故障转移:在作业失败时,Flink 需要从最近的检查点恢复状态。这要求检查点数据必须被持久化到一个可靠的存储系统中,通常是分布式文件系统(如 HDFS、Amazon S3 等)。这样,无论作业的状态数据存储在哪里,检查点数据都可以从这个目录中恢复。
-
增量快照:对于
EmbeddedRocksDBStateBackend,Flink 支持增量快照。这意味着检查点不仅保存了状态数据的完整副本,还记录了自上次检查点以来状态的变化。这些增量快照也需要被保存到检查点目录中,以便在恢复时能够更高效地重建状态。 -
配置一致性:配置检查点目录为 Flink 提供了一个统一的配置点,无论使用哪种状态后端,都可以在同一个配置文件中指定检查点的存储位置。这有助于简化配置管理,并确保在不同状态后端之间切换时的一致性。
flink 与spark 简单比较
flink 有哪几种时间
| 时间概念 | 描述 | 适用场景 |
|---|---|---|
| 事件时间 (Event Time) | 数据本身所携带的时间戳,在事件生成时确定。 | 处理乱序事件、处理延迟数据的场景 |
| 处理时间 (Processing Time) | 数据到达 Flink 系统时的系统时间。 | 实时流处理任务、简单的数据处理场景 |
| 摄取时间 (Ingestion Time) | 数据进入 Flink 系统时所携带的时间戳,由 Source 接收到数据时确定。 | 中间场景,在事件时间和处理时间之间权衡 |
flink 有哪些语义
| 流处理语义 | 描述 | 应用场景 |
|---|---|---|
| 精确一次语义 (Exactly-Once) | 每个事件都会被处理且仅被处理一次,不会出现数据丢失或重复处理的情况。 | 金融交易处理、关键业务数据处理 |
| 至少一次语义 (At-Least-Once) | 每个事件至少会被处理一次,但可能会出现数据重复处理的情况。 | 实时日志收集、实时指标计算 |
| 无语义 (No Semantics) | 对事件的处理不进行任何语义上的保证,可能会出现数据丢失、重复处理甚至乱序处理的情况。 | 实时推荐系统、实时监控系统 |
flink 任务流程
flink 广播变量
flink 的operator chain
flink 窗口有哪几种
| 窗口类型 | 描述 | 使用场景 |
|---|---|---|
| 滚动窗口 (Tumbling Windows) | 固定大小的窗口,按固定的时间间隔对数据流进行切分。 | 对数据流进行固定时间间隔的聚合操作。 |
| 滑动窗口 (Sliding Windows) | 由固定大小和滑动时间间隔组成的窗口,窗口之间可以有重叠部分。 | 对数据流进行连续的聚合操作。 |
| 会话窗口 (Session Windows) | 根据数据流中的会话间隙划分窗口,一个会话表示一段连续的时间内数据的集合。 | 对非连续数据流进行聚合操作。 |
| 全局窗口 (Global Windows) | 将整个数据流作为一个窗口处理,不对数据进行切分。 | 对整个数据流进行全局聚合操作 |
flink 内存管理
原理
双流JOIN 实现原理
Flink DataStream 如何实现双流Join-腾讯云开发者社区-腾讯云
和维度关联的几种方案
| 方案 | 描述 | 优点 | 缺点 |
|---|---|---|---|
| 提前加载方案 | 在实现方案启动时从外部存储加载维度数据,实现简单,但不能更新数据 | 实现简单,适用于静态数据,不需要频繁更新的场景 | 不能更新数据,不适用于频繁变动的维度数据 |
| 定时更新方案 | 定时从外部存储加载维度数据,然后存储,定时更新,解决了不能更新数据的问题,但不支持实时更新,有延时,不适用于大数据量 | 可以解决数据不能更新的问题 | 不能实时更新,有延时,不适用于大数据量 |
| 实时更新方案 | 实时从外部存储查询维度数据,支持超大数据量,但可能会产生查询瓶颈,可以使用异步查询的方案 | 可以支持超大数据量,可以实现实时更新 | 可能会产生查询瓶颈,实时性取决于外部存储的性能和网络延迟 |
| 广播数据的方案 | 将更新后的数据通过广播形式和业务数据进行 Join,可以实现实时更新维表 | 可以实时更新维表 | 需要维护广播数据的一致性和更新机制,可能会增加网络传输和内存消耗 |
| Temporal Table Function 方案 | 在 Flink SQL 中通过 Temporal Table Function 方案实现,可以 join 不同时间的维度数据 | 可以实现不同时间的维度数据的 join | 适用于 Flink SQL,可能需要对应的支持和功能 |
watermark生成策略
| 策略 | 描述 |
|---|---|
| 周期性生成 | 定期生成 Watermark,例如每隔一定时间(如每100毫秒)生成一个 Watermark,表示事件时间已经到达或者超过了这个 Watermark 所表示的时间戳。 |
| 事件驱动生成 | 当特定类型的事件到达时,触发生成一个 Watermark。例如,在基于窗口操作的情况下,当收到窗口关闭事件时,可以根据这个事件生成一个 Watermark,表示当前处理的时间戳已经到达或者超过了窗口的关闭时间。 |
| 自定义生成策略 | Flink 提供了灵活的 API,允许用户根据自己的需求实现自定义的 Watermark 生成策略。通过实现 AssignerWithPunctuatedWatermarks 或者 AssignerWithPeriodicWatermarks 接口,用户可以定义自己的 Watermark 生成逻辑。 |
flink 一次性实现实现
| 实现方式 | 描述 |
|---|---|
| Checkpointing 机制 | Flink 使用 Checkpointing 机制来实现 Exactly-Once 语义。Checkpoint 是 Flink 在作业执行过程中创建的状态快照,用于保存作业状态。Flink 在执行任务时周期性地创建 Checkpoint,并将 Checkpoint 存储到可靠的持久化存储系统中。当作业失败或需要恢复时,Flink 可以使用最近的 Checkpoint 来恢复作业状态,从而实现 Exactly-Once 语义。Checkpointing 机制还包括了分布式快照的协调和一致性保证,确保在失败时能够正确恢复状态。 |
| 状态管理和恢复 | Flink 通过状态管理和恢复机制来保证作业状态的一致性和恢复。Flink 的状态管理器负责管理作业的状态,并在需要时将状态持久化到外部存储系统中。当作业失败或需要恢复时,Flink 可以从外部存储系统中恢复状态,以确保作业能够从失败的地方继续执行,并且保持一致性 |
flink 端到端一次性实现实现
| 要点 | 描述 |
|---|---|
| Exactly-Once 语义支持 | 使用支持事务性写入的数据源,如 Apache Kafka、Apache Hudi、Apache HBase 等。确保 Flink 作业的容错机制能够正确处理故障情况,如使用 Flink 的 Checkpointing 机制实现状态的持久化和恢复。 |
| Exactly-Once 语义的语义保证 | 确保所有算子都是幂等的。确保 Flink 作业的状态管理和状态恢复机制能够确保状态一致性。 |
| 端到端一致性保证 | 保证与外部系统的交互也具有 Exactly-Once 语义,可能需要与外部系统的事务性交互或通过幂等性操作和重试机制来实现。实现适当的错误处理机制,包括故障恢复、幂等性操作、重试策略等,以确保在发生故障或异常情况时能够正确处理并保持端到端的一致性。 |
| 持久化数据源的选择 | 选择支持事务性写入和 Exactly-Once 语义的持久化数据源,如 Apache Kafka、Apache Hudi、Apache HBase 等。这些数据源能够提供端到端的一致性保证,并且与 Flink 的 Exactly-Once 语义兼容。 |
| 错误处理机制 | 实现适当的错误处理机制,包括故障恢复、幂等性操作、重试策略等。确保在发生故障或异常情况时能够正确处理并保持端到端的一致性。 |
flink 撤回语义
Flink 提供了撤回语义(Retraction Semantics),这是指在流式计算中对数据进行修正或撤回的能力。撤回语义通常用于在处理实时数据流时,对先前发出的结果进行更新或删除。
实现撤回语义的一种方法是使用特殊的数据表示来表示撤回操作。通常,使用特殊的撤回消息来标识先前发出的数据应该被撤回,而不是直接删除数据。这样做可以保持数据流的完整性,并允许系统在撤回消息到达时正确地更新之前计算的结果。
flink为啥state用的rocksdb
-
可靠性和持久性:RocksDB 提供了高度可靠的持久化存储,能够在发生故障时恢复状态。这对于需要长时间运行的流处理应用非常重要。
-
性能:RocksDB 是一个高效的键值存储引擎,具有快速的读取和写入速度。对于处理大量数据和需要快速访问状态的应用场景,RocksDB 提供了比内存状态后端更好的性能。
-
可扩展性:RocksDB 具有良好的可扩展性,能够处理大规模的状态数据。这对于处理高吞吐量和大规模数据的流应用非常重要。
-
内存管理:使用 RocksDB 作为状态后端可以有效地管理状态数据的内存,避免了因为状态数据过大导致内存不足的问题。RocksDB 可以自动将部分数据存储在磁盘上,从而降低了内存使用量。
-
灵活性:RocksDB 提供了丰富的配置选项和优化参数,可以根据具体的应用需求进行调整和优化,从而提高性能和可靠性。
-
唯一支持增量的状态后端
Hash shuffle 和sort shuffle
反压如何分析
反压的实现原理
flink 出现反压场景, 异常场景造成Exceeded checkpoint tolerable failure threshold.-CSDN博客
checkpoint 超时可能是由啥导致的
| 因素 | 描述 |
|---|---|
| 资源不足 | 集群资源不足以处理所有任务和状态,例如 TaskManager 的资源(如CPU、内存)不足以处理数据流和状态的快照,或者网络带宽不足以传输大量的状态数据。 |
| 状态大小 | 状态数据量过大,需要花费较长时间来生成和传输快照,可能受到数据流速率、窗口大小、状态保留策略等因素的影响。 |
| IO负载 | 集群的IO负载较高,可能影响快照的生成和传输速度,例如数据存储和传输过程中的瓶颈导致的,如磁盘IO限制或网络传输速度限制。 |
| 网络延迟 | 集群中节点之间的网络延迟较高,会影响快照的传输速度,可能受到网络拓扑、节点间距离、网络拥塞等因素的影响。 |
| 任务处理时间长 | 任务的处理时间超过了配置的 checkpoint 超时时间,可能是由于任务逻辑复杂、处理大量数据或计算密集型操作导致的。 |
| 故障节点 | 在 checkpoint 过程中涉及的节点出现故障或性能下降,例如 TaskManager 节点宕机或网络故障,可能导致 checkpoint 操作失败或超时。 |
架构
flink 架构有哪些角色
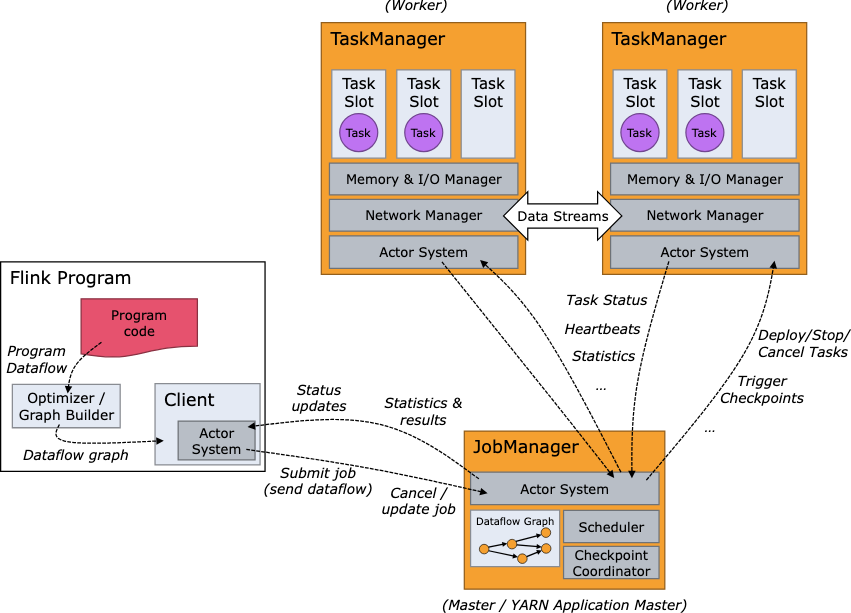
| 组件 | 描述 |
|---|---|
| JobManager | 负责整个作业的调度和协调、管理作业的生命周期(包括启动、监控和故障处理)、负责触发和协调作业的 Checkpoint、管理集群的资源(与资源管理器通信进行资源分配)、在高可用性模式下确保集群的高可用性。 |
| TaskManager | 执行实际的数据处理任务、管理任务的状态(包括数据流程图、中间结果、缓存的状态等)、负责数据交换(通过网络传输数据流)、管理本地资源(如 CPU、内存等)、与 JobManager 协调资源的分配和释放。 |
高可用实现
如何一个架构同时支持流和批
批是流的一种特殊情况
| 组件 | 描述 |
|---|---|
| DataStream API | 用于处理无限和有限的数据流,支持流式和批处理,具有事件时间处理、窗口操作等特性。 |
| 运行时架构 | 分布式流处理引擎,用于处理实时数据流;优化器和执行引擎,针对批处理作业进行优化和执行。 |
| 状态管理 | 高效可靠的状态管理机制,用于在流处理和批处理作业中管理状态。 |
| 任务调度和资源管理 | 负责将作业中的任务分配给集群中的计算资源,并确保任务按照预期的方式执行,同时合理地利用集群资源。 |
应用
flink cdc
mysql cdc
tidb cdc
无锁算法
如何确保顺序
如何确保任务失败后,可以从中断节点开始消费
Flink CDC 2.0 正式发布,详解核心改进 - 知乎
flink sql
flink 如何实现top n 操作
CREATE TABLE transactions (
user_id STRING,
amount DOUBLE
) WITH (
'connector' = 'kafka',
'topic' = 'transactions_topic',
'format' = 'json'
);
-- 计算每个用户的交易总额,并获取Top N
SELECT
user_id,
total_amount
FROM (
SELECT
user_id,
SUM(amount) AS total_amount,
ROW_NUMBER() OVER (PARTITION BY user_id ORDER BY SUM(amount) DESC) AS row_num
FROM
transactions
GROUP BY
user_id
)
WHERE
row_num <= 10;
flink 优化实时任务
| 优化方法 | 描述 |
|---|---|
| 状态后端选择 | 根据任务需求选择适合的状态后端,如RocksDB或内存 |
| 并行度调整 | 根据数据量和任务复杂度调整并行度以提高性能 |
| 窗口优化 | 考虑使用滑动窗口、会话窗口等优化窗口设计 |
| 算子链优化 | 合并多个算子以减少状态转换和数据序列化的开销 |
| 网络通信优化 | 减少网络通信开销,如使用本地连接和网络拓扑优化 |
| 内存管理优化 | 优化内存分配和管理以减少GC开销 |
| 数据分区优化 | 合理分区数据以提高并行度和减少数据倾斜 |
| 代码优化 | 优化代码逻辑和数据处理逻辑以提高执行效率 |
| 任务调度优化 | 调整任务调度策略以更好地利用资源和平衡负载 |
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











