







 该文介绍了一项基于IBM人力资源分析数据集的员工离职预测项目。通过使用matplotlib和网易有数进行数据可视化,以及Jupyter作为开发工具,作者选择了决策树进行离职预测。数据预处理包括清洗和选取关键特征,初步分析显示离职率与年龄、教育程度、收入等因素有关。
该文介绍了一项基于IBM人力资源分析数据集的员工离职预测项目。通过使用matplotlib和网易有数进行数据可视化,以及Jupyter作为开发工具,作者选择了决策树进行离职预测。数据预处理包括清洗和选取关键特征,初步分析显示离职率与年龄、教育程度、收入等因素有关。
一、背景
二、目标
内容比较多,分为上下两篇来更新
1)离职员工分布情况(上)
2)离职受哪些因素影响(上)
3)如何通过数据对员工离职进行预测(下)
三、执行
数据分析使用的matplotlib.pyplot、网易有数 做可视化;特征值比较多,离职预测用的决策树;开发工具用的jupyter,方便分段执行。
整体开发思路分为8步:
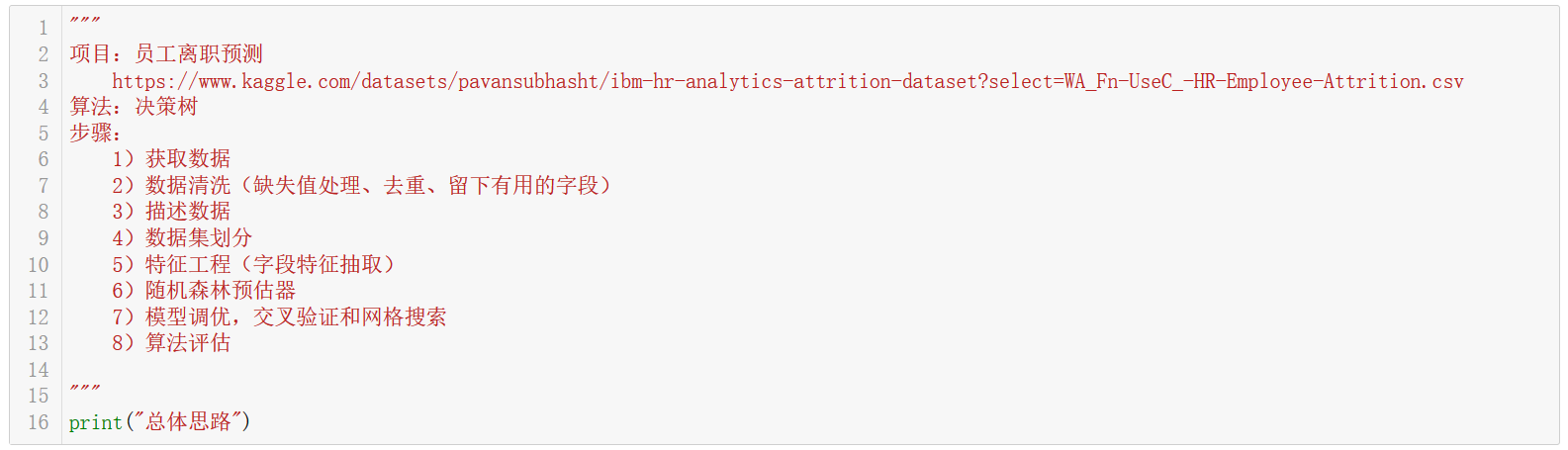
1)获取数据
Kaggle上的入门项目《IBM人力资源分析》
项目url:IBM HR Analytics Employee Attrition & Performance | Kaggle
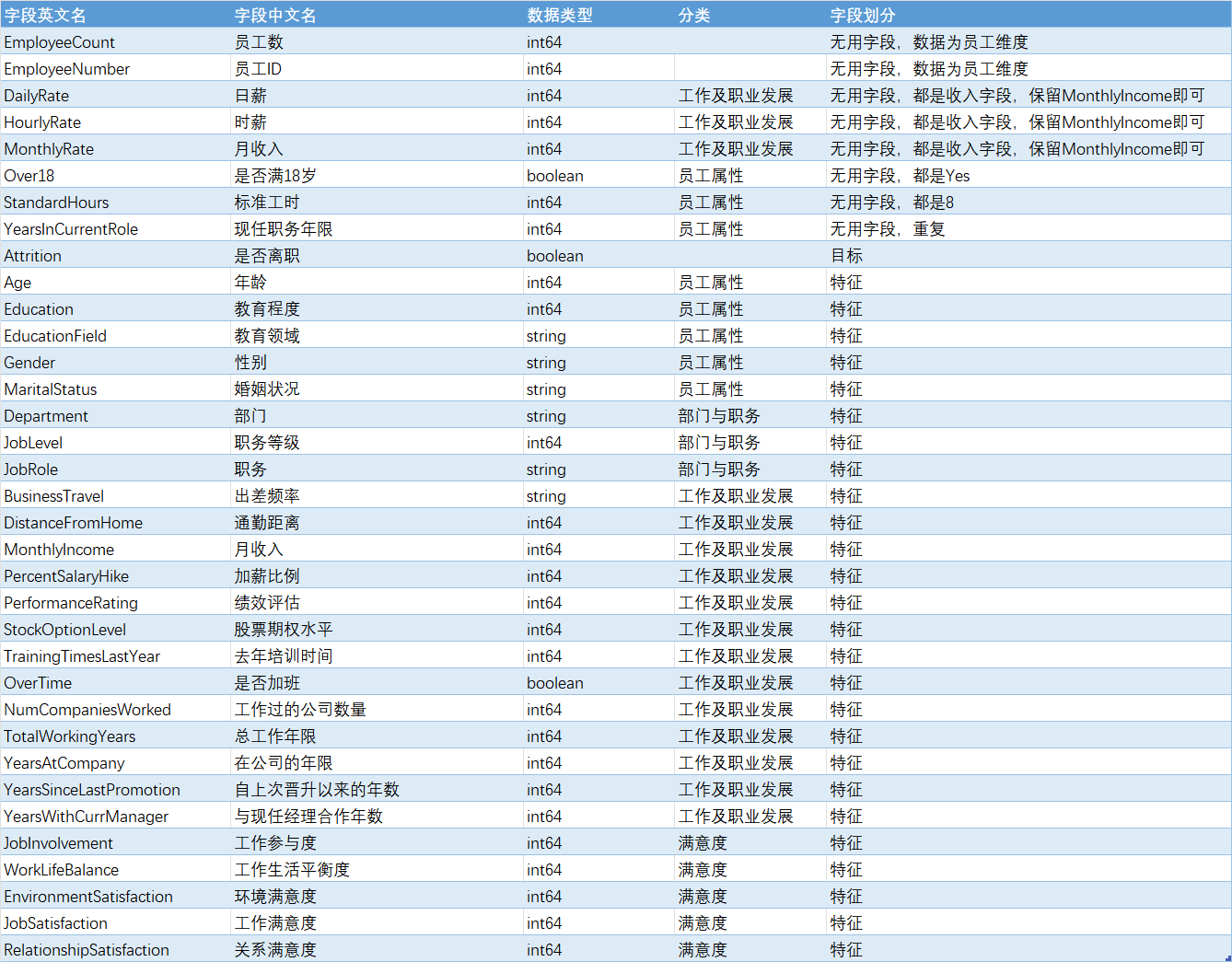
项目数据为1个csv文件。原始数据共1470行,35个字段:26个数值型、6个文本型、3个布尔型,其中有8个自字段为无用字段。
代码实现
# 1)读取数据
import pandas as pd
data0 = pd.read_csv('WA_Fn-UseC_-HR-Employee-Attrition.csv')
# 取需要的字段
data1 = data0[['Attrition','Age','Education','EducationField','Gender','MaritalStatus','Department','JobLevel','JobRole','BusinessTravel','DistanceFromHome','MonthlyIncome','PercentSalaryHike','PerformanceRating','StockOptionLevel','TrainingTimesLastYear','OverTime','NumCompaniesWorked','TotalWorkingYears','YearsAtCompany','YearsSinceLastPromotion','YearsWithCurrManager','JobInvolvement','WorkLifeBalance','EnvironmentSatisfaction','JobSatisfaction','RelationshipSatisfaction']]
# 列名改成中文名
data1.columns = ['是否离职','年龄','教育程度','教育领域','性别','婚姻状况','部门','职务等级','职务','出差频率','通勤距离','月收入','加薪比例','绩效评估','股票期权水平','去年培训时间','是否加班','工作过的公司数量','总工作年限','在公司的年限','自上次晋升以来的年数','与现任经理合作年数','工作参与度','工作生活平衡度','环境满意度','工作满意度','关系满意度']
data12)数据清洗
这里主要是处理原始数据中的空值、重复值等,避免影响分析结果。样本数据未发现相关问题。
# 2)数据清洗(缺失值处理)
print("清洗前那些行有空值:\n", data1.isna().sum())
print("去重后数据行数:\n", len(data1.drop_duplicates()))3)描述数据
带着以下问题来看进行数据描述
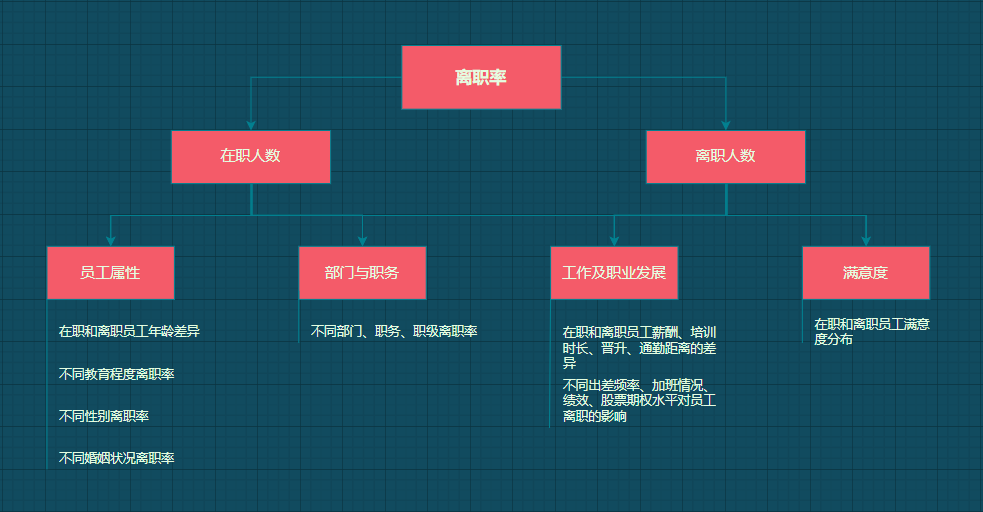
方法一:把整理好的数据通过BI呈现,个人习惯这种方法,可视化图表选择比较多,可以形成分析报告
报告图片:

方法二:通过代码实现数据描述,可以先看看整个表的数据情况,然后分指标去绘制可视化图表。分别定义了箱线图和柱状图,根据需求分析的字段进行调用。
# 4)描述数据,不同的特征值需要用不用的图表
import matplotlib.pyplot as plt
import seaborn as sns # sns有打包好的boxplot包,可区分X/Y轴。plt中需要
from scipy.stats import pearsonr
plt.rcParams['font.family']=['STFangsong'] # 中文
# 定义离职分布箱线图
def boxplot_demo(name):
sns.boxplot(y=data1[name],x=data1['是否离职'])
plt.title(name)
plt.show()
data_lz = data1[name].loc[data1["是否离职"]=="Yes"]
print("离职员工{}数据:\n".format(name),data_lz.describe())
data_zz = data1[name].loc[data1["是否离职"]=="No"]
print("\n在职员工{}数据:\n".format(name),data_zz.describe())
# 定义离职率柱状图
def bar_demo(name):
# 离职数据
data_lz = data1[["年龄",name]].loc[data1["是否离职"]=="Yes"]
data_lz_cnt = data_lz.groupby([name]).count().add_prefix('count')
data_lz_cnt["key"] = data_lz_cnt.index
# 在职数据
data_zz = data1[["年龄",name]].loc[data1["是否离职"]=="No"]
data_zz_cnt = data_zz.groupby([name]).count().add_prefix('count')
data_zz_cnt["key"] = data_zz_cnt.index
# 数据join
data_rate = pd.merge(data_zz_cnt,data_lz_cnt,how='left',on="key")
# 增加离职率字段计算
data_rate["rate"] = round(data_rate["count年龄_y"]/(data_rate["count年龄_x"]+data_rate["count年龄_y"]),3)
plt.bar(data_rate["key"], data_rate["rate"], label='离职率')
plt.show()
print_data = data_rate[["key","count年龄_x","count年龄_y","rate"]]
print_data.columns = ["分类","在职人数","离职人数","离职率"]
return print_data# 不同性别离职率
bar_demo(name="性别")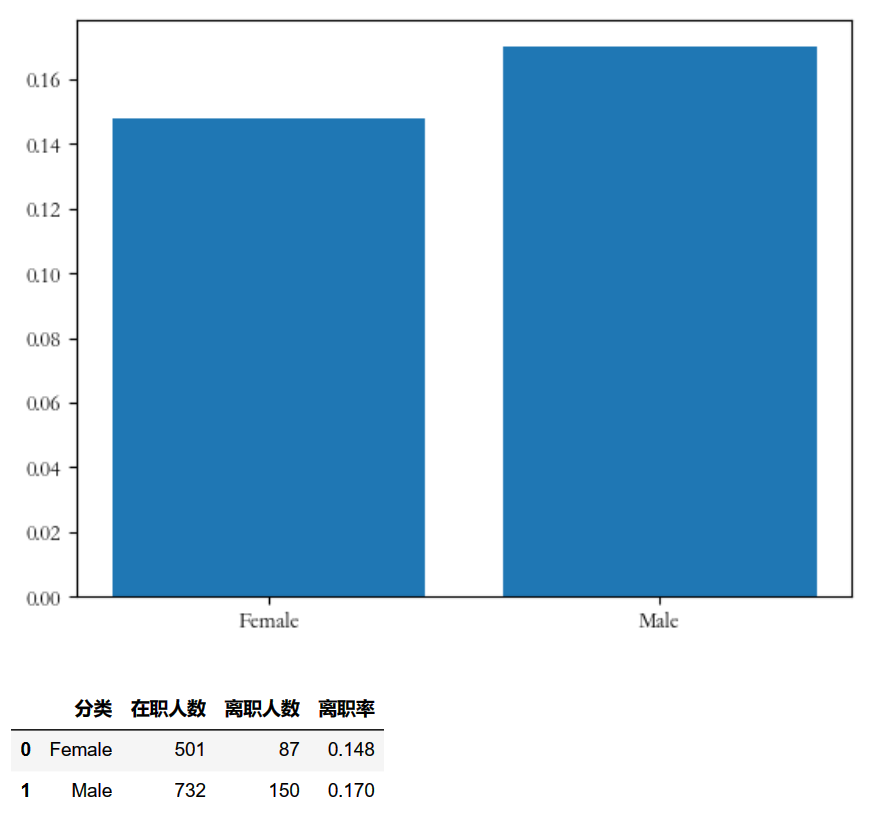
# 年龄和离职关系
boxplot_demo(name = "年龄")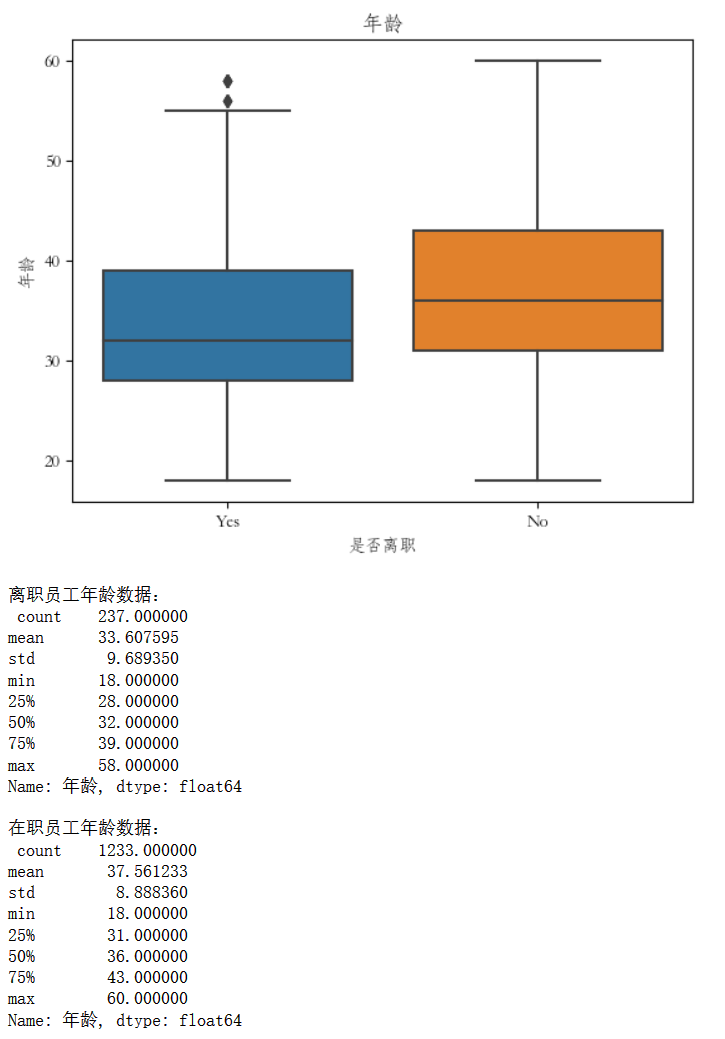
上篇总结:
样本数据量1470,数量偏少,部分分析结论借鉴意义较低。
从分析结论来看,离职率偏高的群里是 "单身年轻"、"中低级别"、"较低收入"、"出差频繁"、"加班多"、"工作满意度低",比较符合常规认知。
对于企业而言,需要着重思考如何在有限的资源资源条件下,保留优质员工;如何在工作较为集中或项目赶工期间,增加对员工关怀。

















 2269
2269

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









