







1.现象
在zuul网关springboot版本由1.5.10升级到2.1.1版本后,网关调用某服务下的所有接口,均出现熔断超时现象,报GATEWAY_TIMEOUT。
2.分析
2.1 问题分析
1.从代码底层调用RibbonRoutingFilter的buildCommandContext方法构建请求上下文RibbonCommandContext。再到构建HystrixCommand,HttpClientRibbonCommand最终调用RetryableRibbonLoadBalancingHttpClient的execute方法发起http请求,整个源码链路跟了一遍,没发现明显异常。
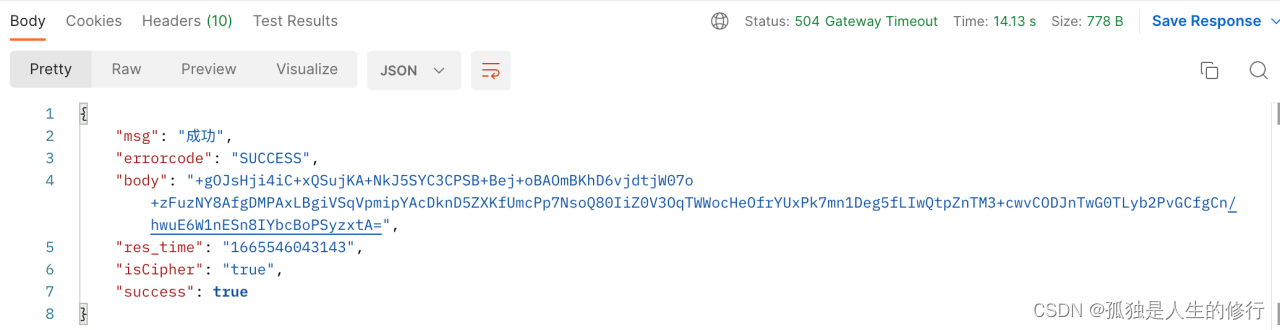
2.启动老的springboot版本的zuul网关应用。发起调用,发现在网关连接发起,再到获取响应头的时候,有获取到响应头信息server:nginx。
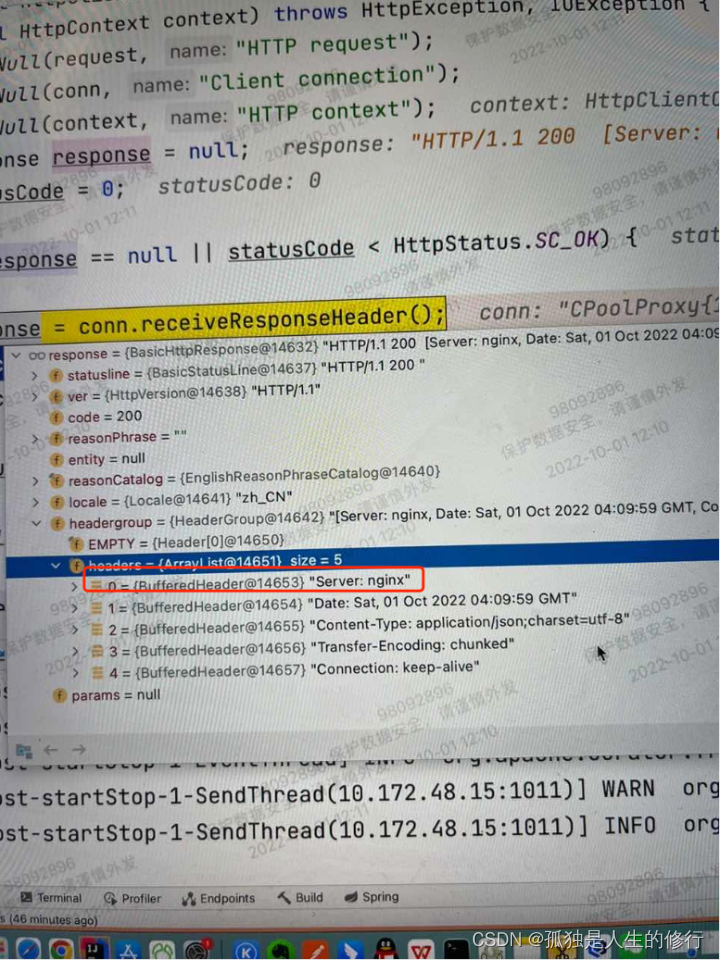
联想到,在下游没有代理的情况下,网关是能正常调用的,所以初次断定是nginx的问题。
3.我们找来了下游服务对应的研发人员,让他配合调整nginx的一系列参数,发现仍然报超时的现象。最后让他把请求相关的参数打印出来:
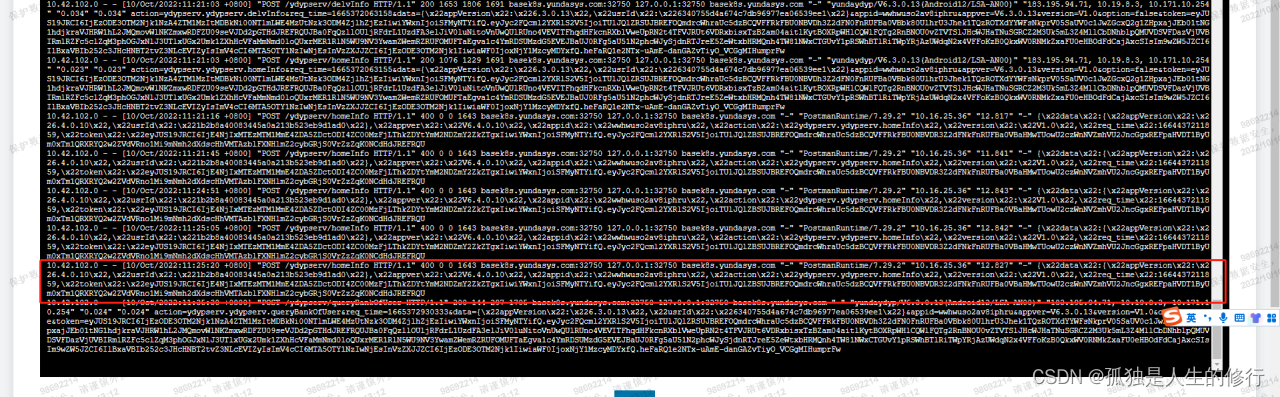
我们发现nginx收到的参数,不是个完整的json。另外http状态码为400,有语义有误和参数有误的含义。另外有两个时间参数request_time和upstream_response_time,其值分别是12.827以及”-”。
两字段的含义:
request_time: 指的就是从接受用户请求的第一个字节到发送完响应数据的时间,即包括接收请求数据时间、程序响应时间、输出响应数据时间。
upstream_response_time: 是指从Nginx向后端建立连接开始到接受完数据然后关闭连接为止的时间。
值大小说明:
$request_time值为12.827是因为在网关设置了ribbon的读取超时时间13秒

$upstream_response_time 为”-”的原因,很可能是nginx没有把请求参数发给下游服务。
延伸:request_time肯定比upstream_response_time值大,特别是使用POST方式传递参数时,因为Nginx会把request body缓存住,接受完毕后才会把数据一起发给后端。所以如果用户网络较差,或者传递数据较大时,request_time会比upstream_response_time大很多。
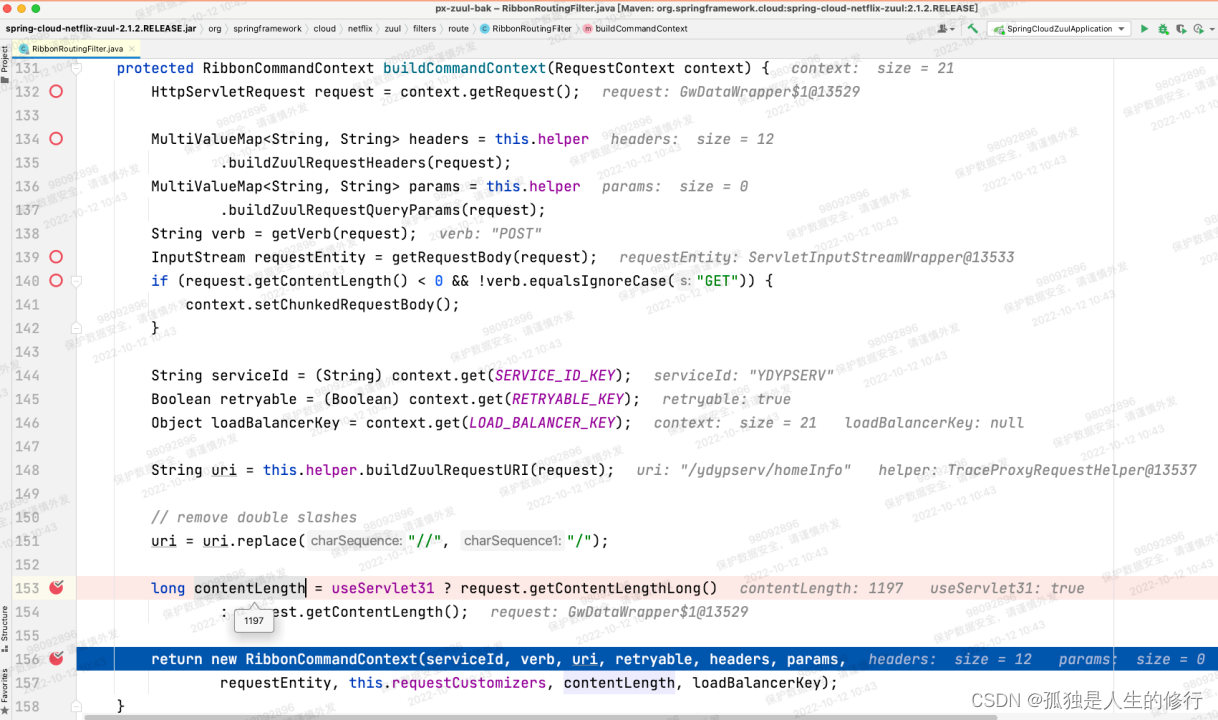
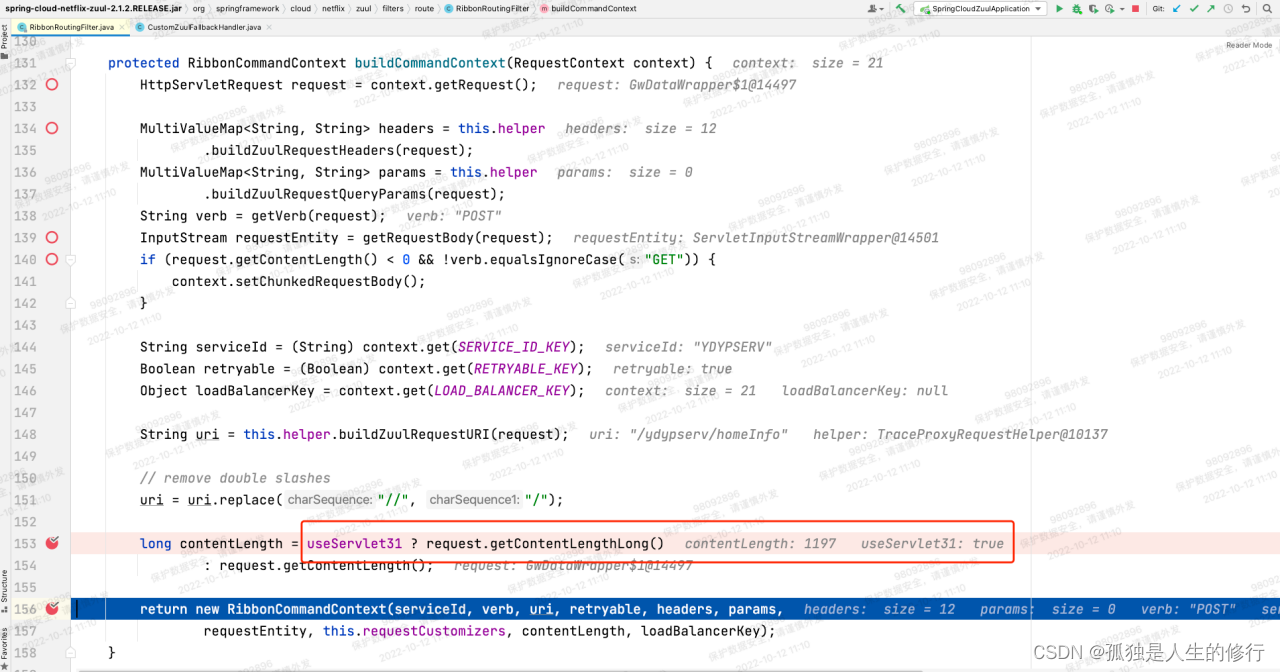
4.由于是参数的问题,所以顺着这个思路,把httpclient相关的jar包,由升级后的httpclient-4.5.6.jar 换回到 httpclient-4.5.5.jar。调用之后仍然报超时。既然最底层的httpclient包回滚都报错,联想到因为spring boot的版本升级,导致feign, hystrix, ribbon等一系列版本都升级。所以很可能在一开始构建请求参数的时候,就出现了问题。我们同时启动升级前后的两个zuul网关应用。我们在最初的构建请求上下文的地方:RibbonRoutingFilter的buildCommandContext方法打上断点,发起调用并进行详细的参数比对。在计算contentLength的时候,发现了不同点:
老版本:
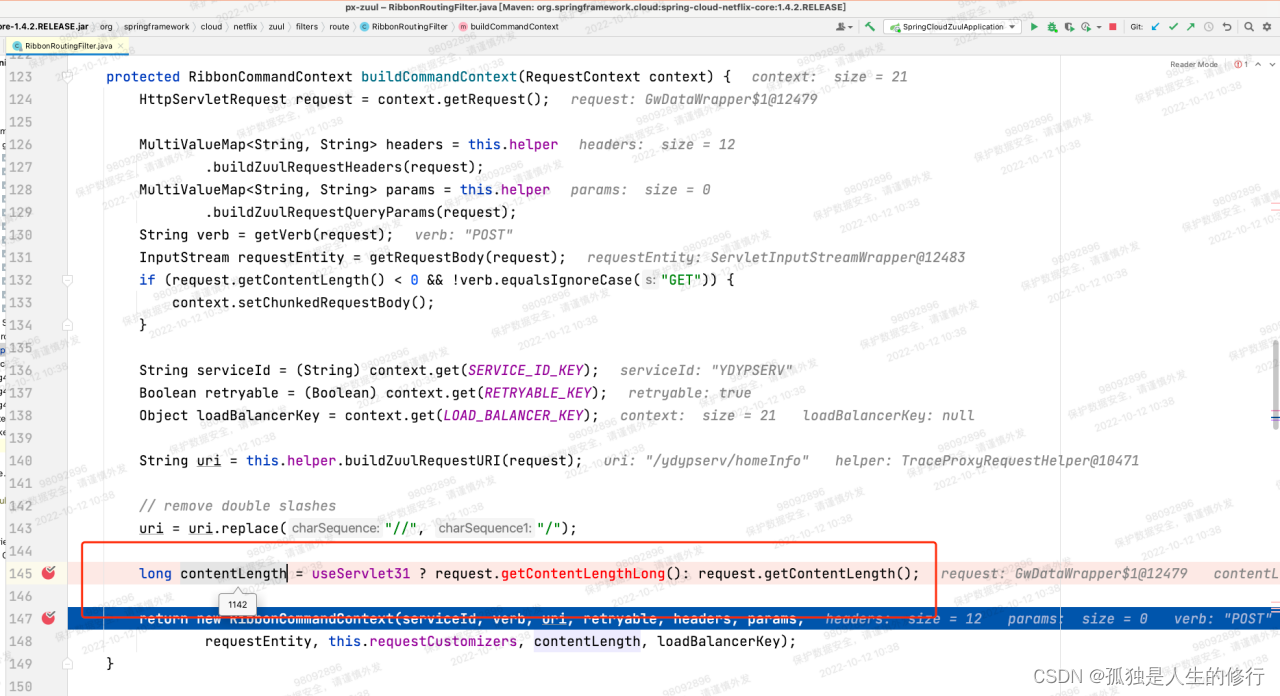
新版本:
2.2 原因分析
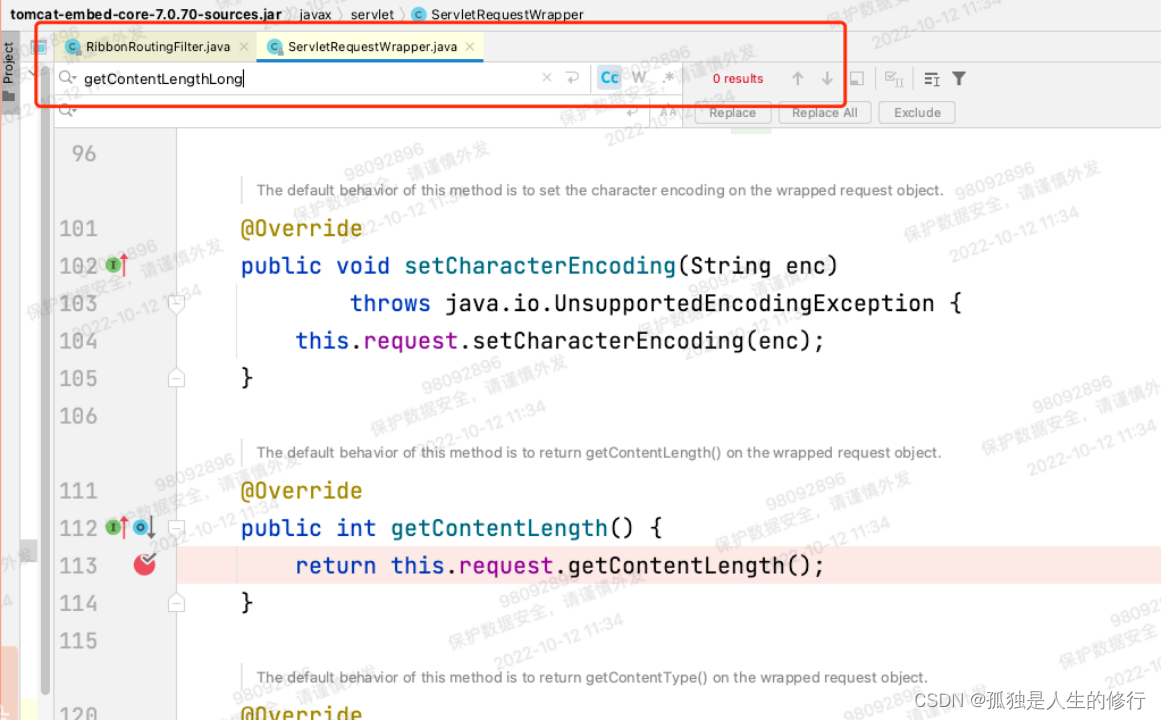
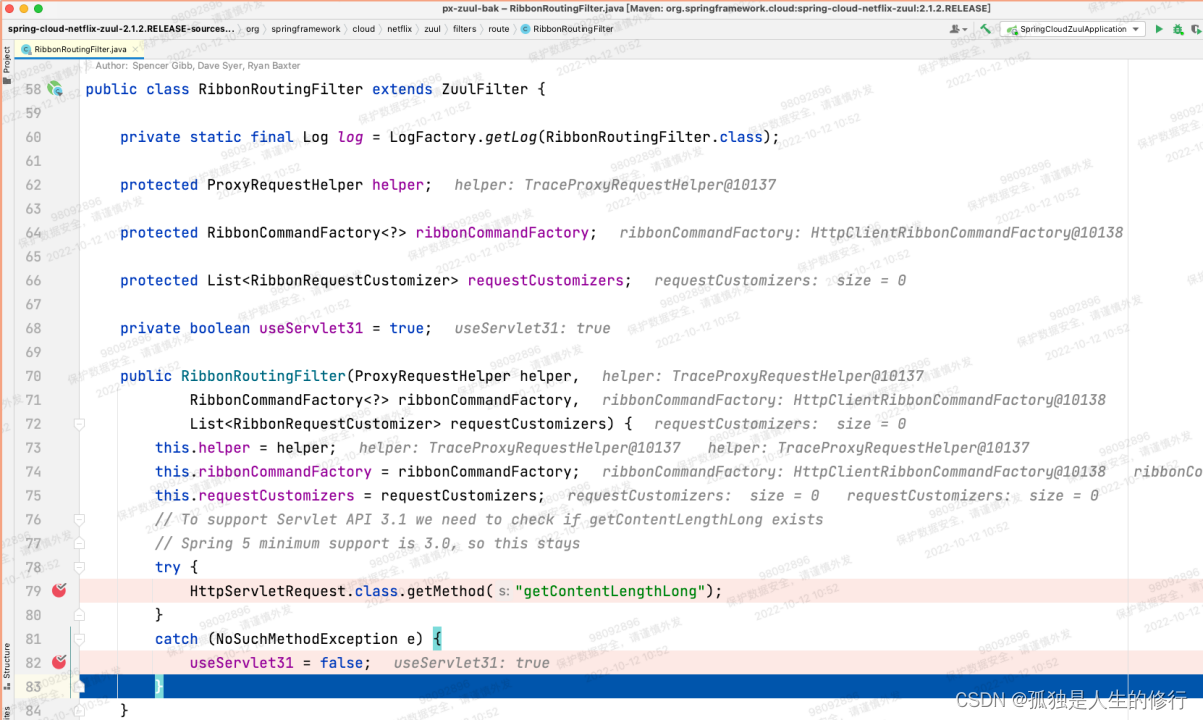
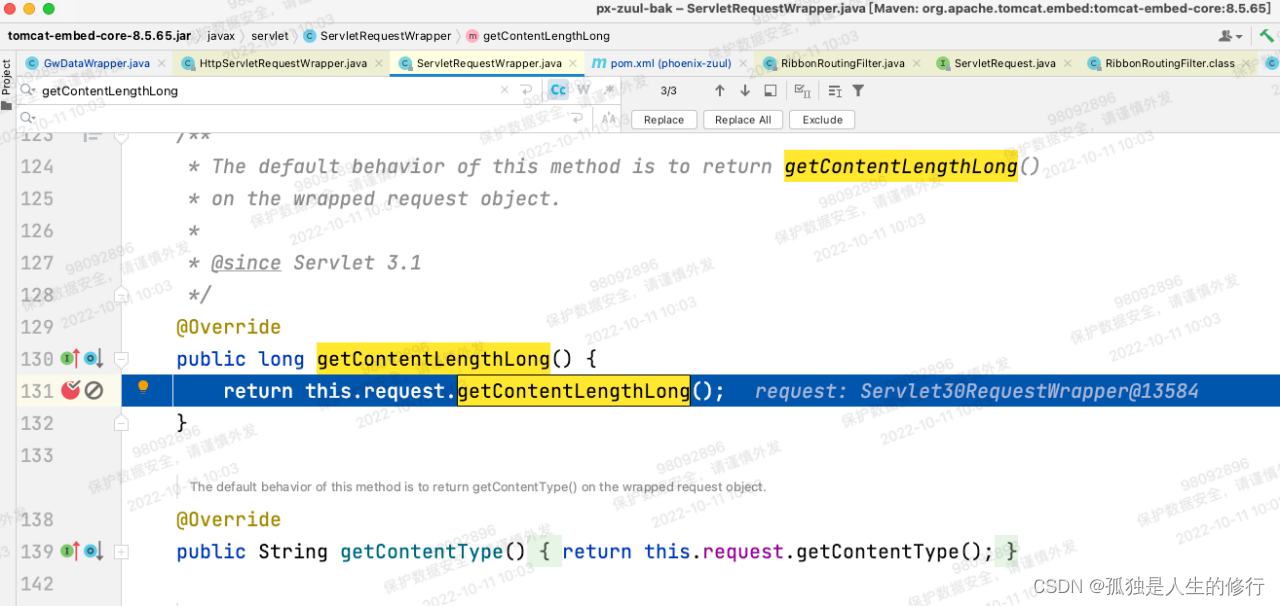
1.项目启动的时候构建底层路由过滤器RibbonRoutingFilter。会判断HttpServletRequest子类是否有getContentLengthLong方法。(因为拉升了tomcat版本,升级前老版本没有,升级后有)。有的话,会将boolean变量useServlet31置为true,否则为false。
老版本:
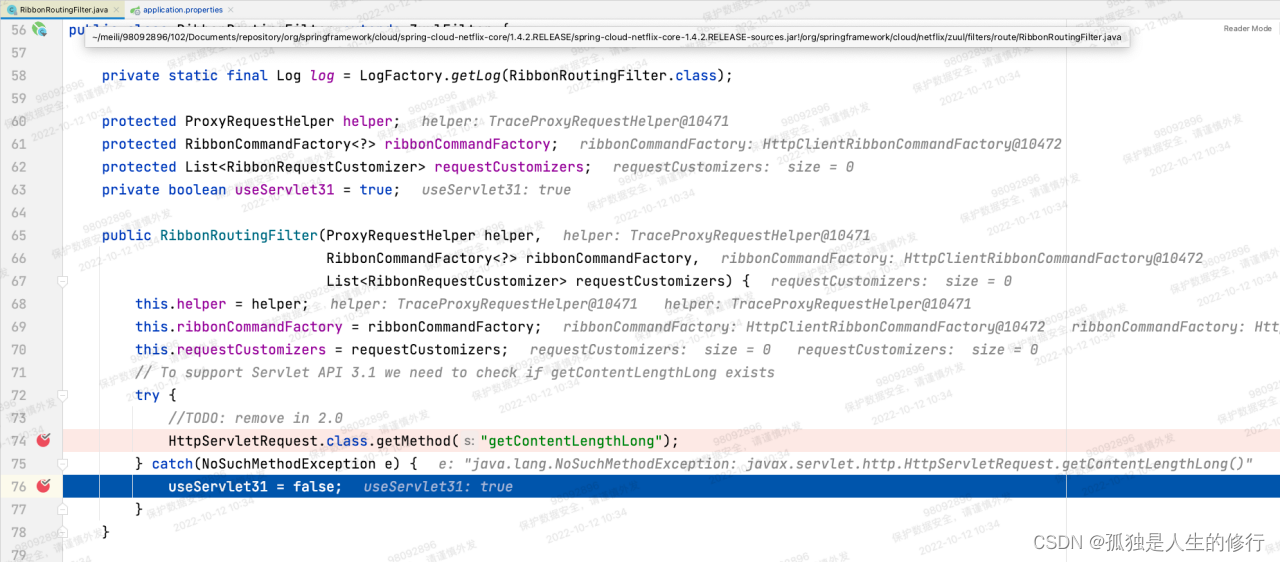
新版本:
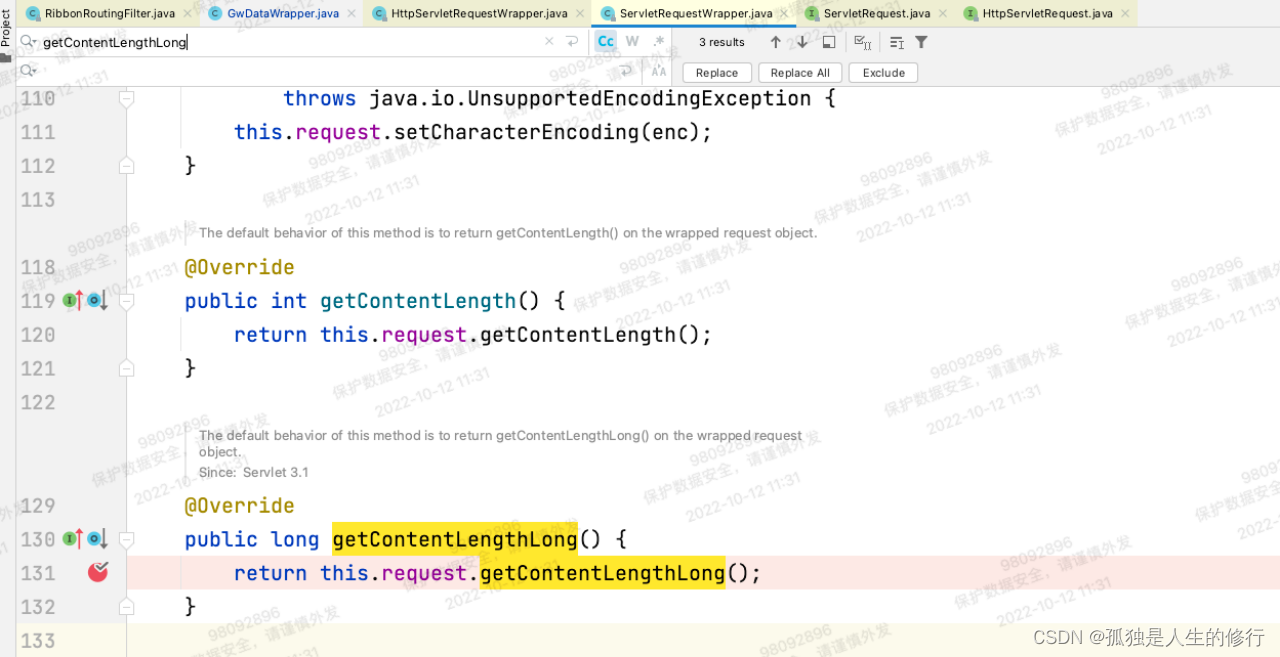
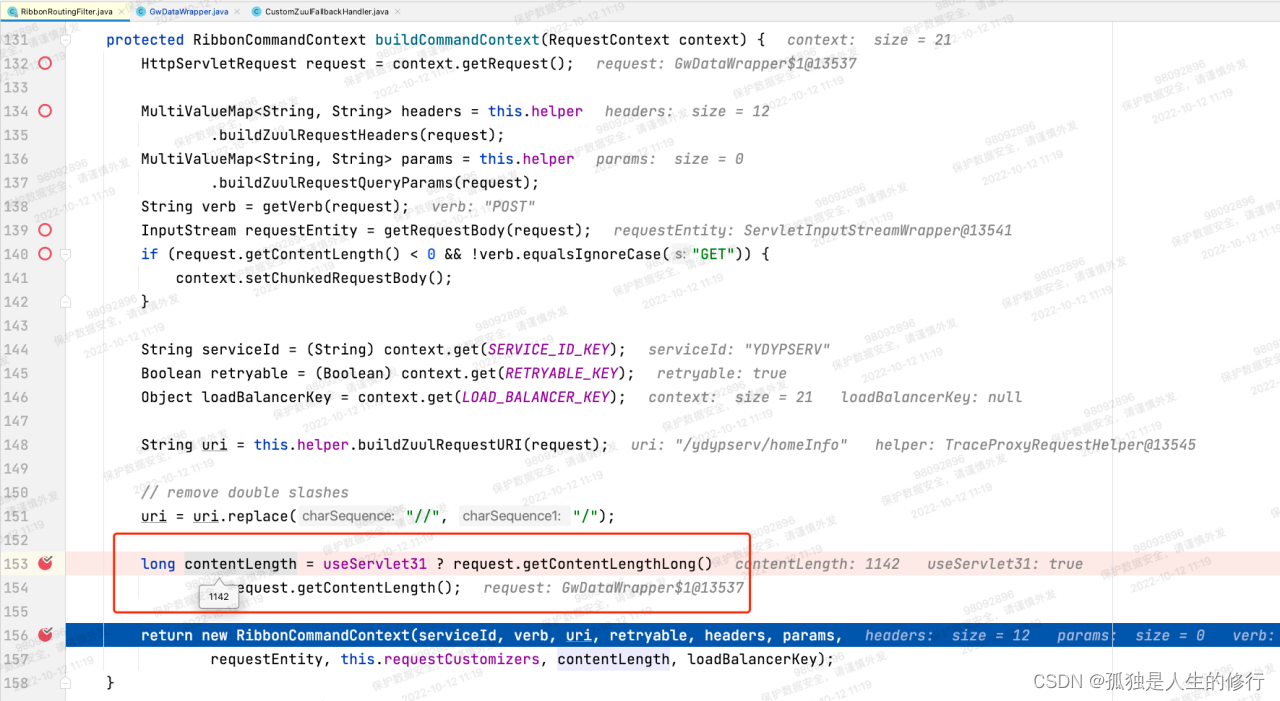
2.请求发起调用,RibbonRoutingFilter内部调用buildCommandContext方法,构建请求上下文RibbonCommandContext,里面包含参数contentLength。contentLength的构建逻辑:long contentLength = useServlet31 ? request.getContentLengthLong(): request.getContentLength(); 由于老版本useServlet31变量值为false,将调用request.getContentLength()方法,此方法在网关的自定义过滤器-加解密过滤器中,被重写过(因为解密后,请求体包的大小相比原来有变化,所以需要重写)。故而能得到准确的contentLength。但是升级后useServlet31为true,调用的是request.getContentLengthLong()。此方法,因为没被重写,获取的是最原始的请求体包大小。当时调用下游服务的请求,升级后最终算出来contentLength为1197,而实际上应该是1142。
老版本:
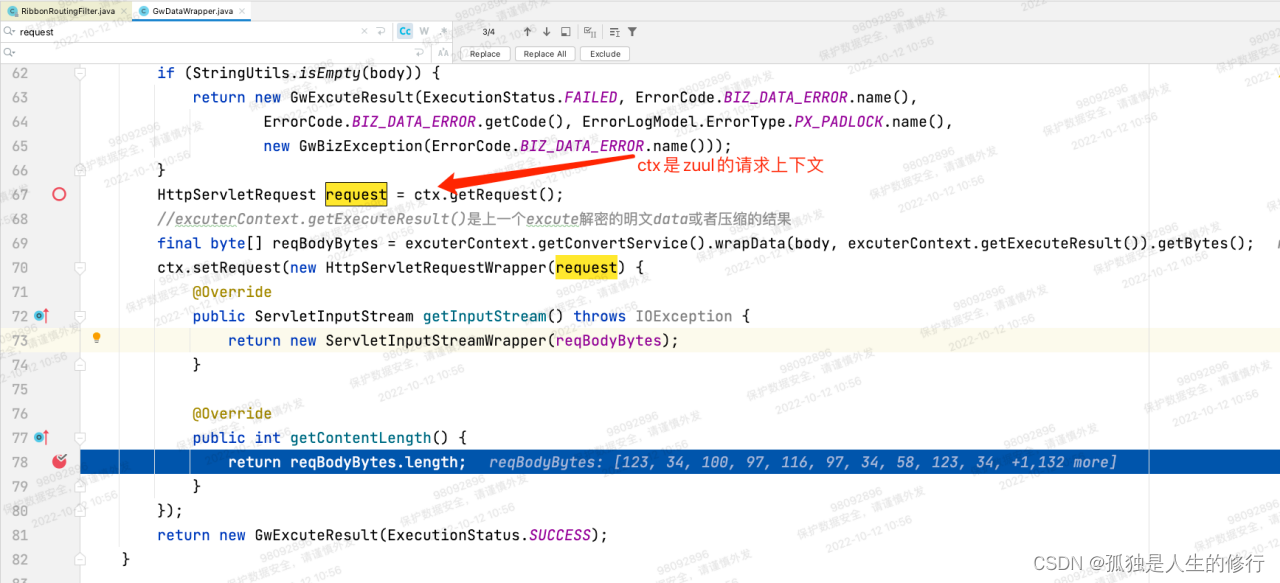
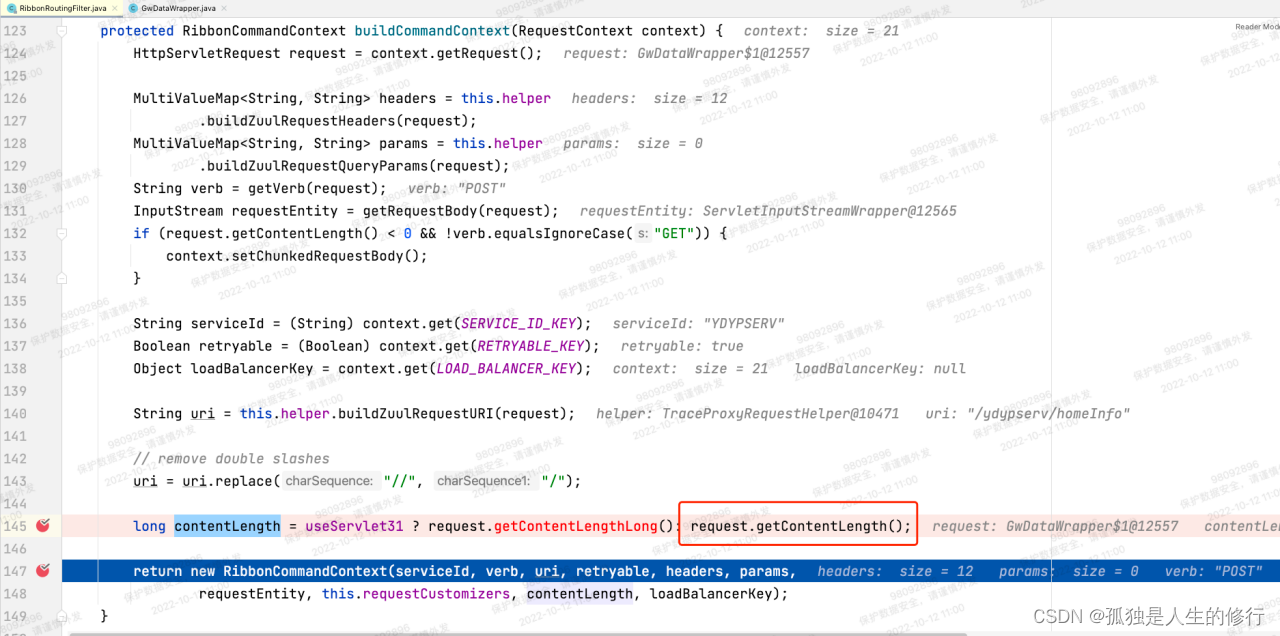
新版本:
-
请求打到下游的nginx后,nginx会再转发给他们的下游服务。但nginx因为contentlenth比实际大的缘故,导致nginx读取到消息结尾后,会等待下一个字节,会无响应直到超时。自然也无法把请求发给下游服务,这也是上文$upstream_response_time为”-”的原因。
-
nginx迟迟不给网关返回响应,超过了熔断的时间,最终因为熔断报了GATEWAY_TIMEOUT。

3.解决
3.1修改重写方法
加解密代码块中,重写方法由getContentLength() 改为getContentLengthLong(),再次发起调用后,一切正常。

the end~















 7765
7765











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









