







目录
1. 容错
1. 1 全局配置
1. 2 检查点
发生故障之后怎么办?最简单的想法当然是重启机器、重启应用。这里的问题在于,流处理应用中的任务都是有状态的,而为了快速访问这些状态一般会直接放在堆内存里;现在重启应用,内存中的状态已经丢失,就意味着之前的计算全部白费了,需要从头来过。就像编写文档或是玩 RPG 游戏,因为宕机没保存而要重来一遍是一件令人崩溃的事情;所以就有了存档,这样即使遇到宕机也可以读档继续了。
在流处理中,我们同样可以用存档读档的思路,把之前的计算结果做个保存,这样重启之后就可以继续处理新数据、而不需要重新计算了。进一步地,我们知道在有状态的流处理中, 任务继续处理新数据,并不需要“之前的计算结果”,而是需要任务“之前的状态”。所以我们最终的选择,就是将之前某个时间点所有的状态保存下来,这份“存档”就是所谓的“检查点” (checkpoint)。
检查点是 Flink 容错机制的核心。这里所谓的“检查”,其实是针对故障恢复的结果而言的:故障恢复之后继续处理的结果,应该与发生故障前完全一致,我们需要“检查”结果的正确性。所以,有时又会把 checkpoint 叫作“一致性检查点”。
1. 3 开启检查点并且指定检查点时间间隔 及 Checkpoint的模式设置
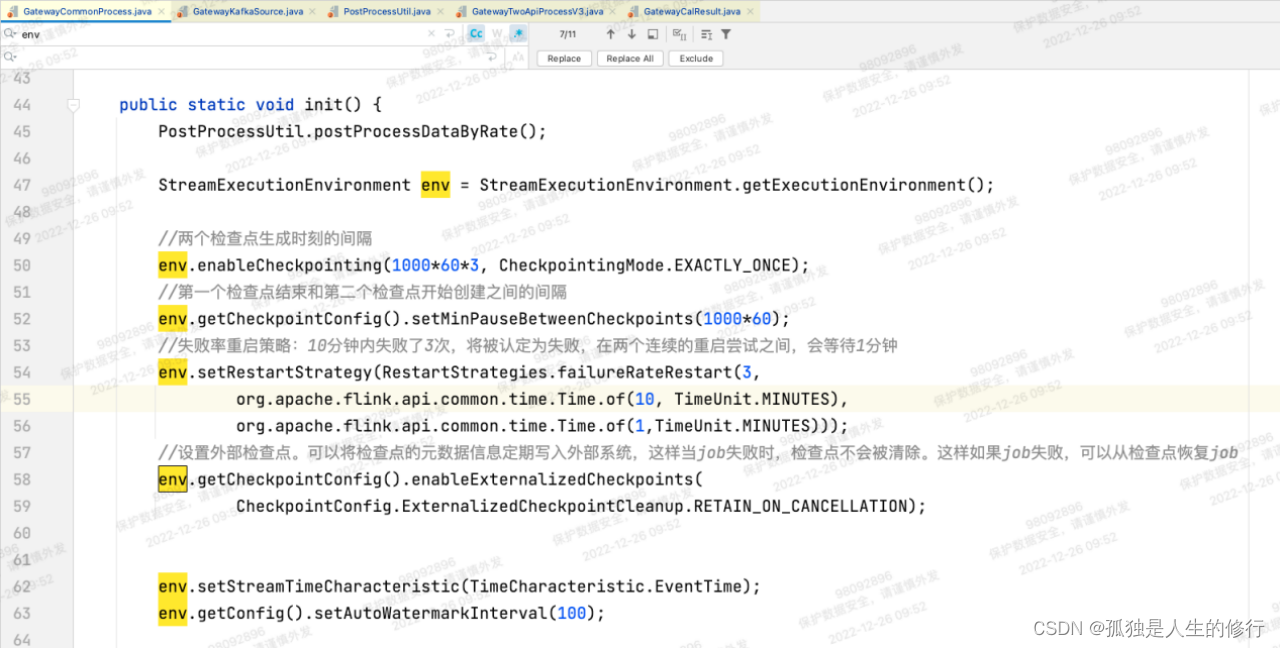
env.enableCheckpointing(1000 * 60 * 3, CheckpointingMode.EXACTLY_ONCE);
检查点时间间隔:1000 * 60 * 3,按照生产1分钟为1个窗口的设置,这里可以设置成1分钟,也就是1000 * 60。
Checkpoint的模式设置:
exactly-once:保证整个应用内端到端的数据一致性,这种情况比较适合于数据要求比较高,不允许出现丢数据或者数据重复(对于项目中的告警场景,对数据准确度是要求较高的,所以选择exactly-once)
由于一致性要求高,flink内部要做exactly-once检查,因此Flink的性能也相对较弱。对于大多数应用程序,只需一次就可以了,flink的Checkpoint默认模式为exactly-once。
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
at-least-once:语义更适合于时廷和吞吐量要求非常高但对数据的一致性要求不高的场景。flink内部无须exactly-once检查。
env.getCheckpointConfig.setCheckpointingMode(CheckpointingMode.AT_LEAST_ONCE);
1. 4 第一个检查点结束和第二个检查点开始创建之间的间隔
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(1000*60);
这个是两次checkPoint之间最小的时间间隔,此时小伙伴们可能会有点疑惑,我在开启checkPoint的时候不是已经给了一个10秒作为checkPoint的执行间隔了吗,这个参数有啥意义?这里解释一下,我们执行checkPoint肯定是需要一定的时间的,比如说我这次执行checkPoint就花了10秒或者10秒钟我还是没执行完,setMinPauseBetweenCheckpoints(500)就是说,我会让这俩checkPoint的操作至少会有一定的时间间隔,稍微的等一下上一个checkPoint的意思。
1. 5 失败率重启策略
10分钟内失败了3次,将被认定为失败,在两个连续的重启尝试之间,会等待1分钟
env.setRestartStrategy(RestartStrategies.failureRateRestart(3,
org.apache.flink.api.common.time.Time.of(10, TimeUnit.MINUTES),
org.apache.flink.api.common.time.Time.of(1,TimeUnit.MINUTES)));
1. 6 当 Flink 任务取消时,保留外部保存的 checkpoint 信息
env.getCheckpointConfig().enableExternalizedCheckpoints(
CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
2. 提高计算准确度
2. 1 水位线
水位线,首先水位线的主要作用是解决数据的延迟和乱序问题,水位线到底是什么?水位线其实可以理解是一个特殊的数据,用来延迟窗口的触发(此处指的窗口每个相互独立)
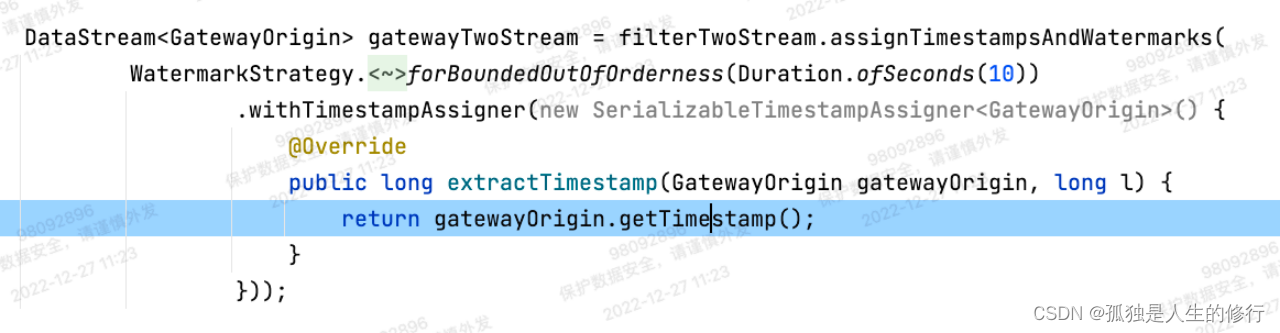
在网关的生产环境中,数据乱序程度很小,基本都是毫秒级,极端情况会有1秒的乱序,所以我们在生产环境中,水位线设置成了3秒:
WatermarkStrategy.forBoundedOutOfOrderness(Duration.ofSeconds(3))
2. 2 事件时间
Flink中不同的事件概念
Processing time(处理时间): 即事件被机器处理的时间,事件流向某个算子的系统时间
Event Time(事件时间): 事件时间是再某个生产设备上发生时间,指事件进入Flink之前嵌入的时间,通常可以从事件中获取一个时间戳,此时间戳可以用来得出水位线,进而解决延迟,乱序,重发等情况
Ingestion time(摄入时间): 摄入时间即是事件进入Flink的时间,是在Source Operator中设置的。
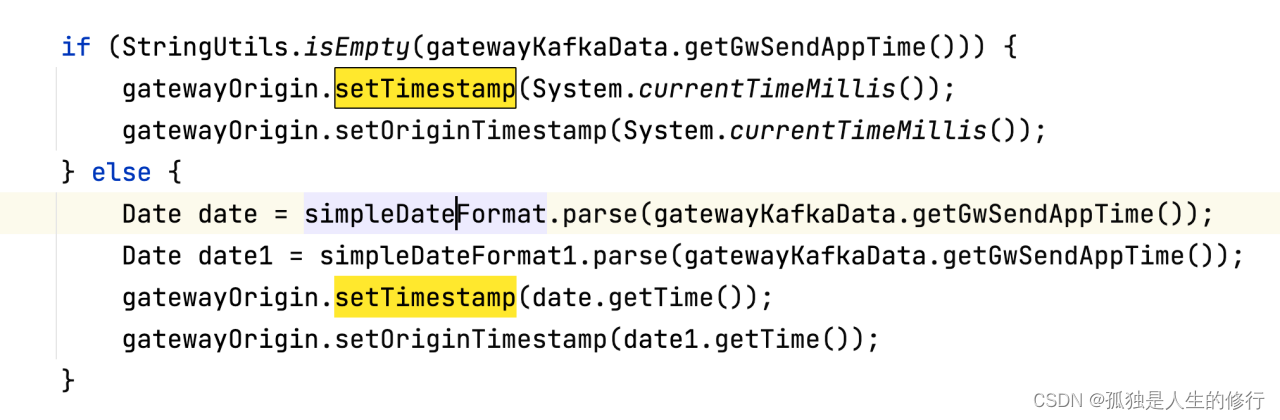
在项目中,我们选择了gwSendAppTime字段作为事件时间,此字段是网关在后置过滤器,返回给客户端的时候生成的。比较贴合某次请求数据生成时间,计算较准确。
2. 3 source端可重放
如果出现故障,我们恢复到之前保存的状态,故障时正在处理的所有数据都需要重新处理;所以我们只需要让源(source) 任务向数据源重新提交偏移量、请求重放数据就可以了。这需要源任务可以把偏移量作为算子状态保存下来,而且外部数据源能够重置偏移量;Kafka 就是满足这些要求的一个最好的例子。
2. 4 幂等写入
从故障恢复时,数据不会重复写入外部系统。接口id和时间戳建立复合主键,避免数据重复插入。














 1269
1269











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









