









一元线性回归与梯度下降
生成数据
- 生成线性相关的散点数据
import numpy as np
import matplotlib.pyplot as plt
num = 20 # 散点数目
# 数据生成
px = np.arange(num)
py = 2*px-4+5*np.random.random(num) # 加上噪声
# 散点图
plt.scatter(px,py)
plt.show()
线性回归模型
y = k x + b y = kx + b y=kx+b
我们需要找到一个合适的参数k和b模型的预测值与真实值差异最小化。
预测值与真实值差异使用均方误差来体现:
L
(
k
,
b
)
=
1
2
n
∑
i
=
1
n
(
y
^
i
−
y
i
)
2
=
1
2
n
∑
i
=
1
n
(
k
x
i
+
b
−
y
i
)
2
L(k,b) = \frac{1}{2n} \sum_{i=1}^{n} (\hat y_i - y_i)^2 = \frac{1}{2n} \sum_{i=1}^{n} (k x_i + b - y_i)^2
L(k,b)=2n1i=1∑n(y^i−yi)2=2n1i=1∑n(kxi+b−yi)2
其中
y
^
\hat y
y^是预测值,
y
y
y是真实值。直观的来看,就是所有预测点到真实点的距离平均值的一半。这个式子我们也叫做损失函数。
梯度下降法
为了得到总误差最小的线性模型,我们将使用梯度下降法。

梯度下降法的迭代关系式:
k
i
=
k
i
−
1
−
α
⋅
∂
L
∂
k
i
−
1
b
i
=
b
i
−
1
−
α
⋅
∂
L
∂
b
i
−
1
\begin{align} k_i &= k_{i-1} - \alpha \cdot \frac{\partial L}{\partial k_{i-1}} \\ b_i &= b_{i-1} - \alpha \cdot \frac{\partial L}{\partial b_{i-1}} \end{align}
kibi=ki−1−α⋅∂ki−1∂L=bi−1−α⋅∂bi−1∂L
其中
α
\alpha
α是步长,也称学习率。这里的
k
0
,
b
0
k_0,b_0
k0,b0我们可以随机初始化一个数字。
通过微积分公式我们可以计算得知:
∂
L
∂
k
=
1
n
∑
i
=
1
n
(
k
x
i
+
b
−
y
i
)
⋅
x
i
∂
L
∂
b
=
1
n
∑
i
=
1
n
(
k
x
i
+
b
−
y
i
)
\begin{align} \frac{\partial L}{\partial k} &= \frac{1}{n} \sum_{i=1}^{n} (k x_i + b - y_i) \cdot x_i \\ \frac{\partial L}{\partial b} &= \frac{1}{n} \sum_{i=1}^{n} (k x_i + b - y_i) \end{align}
∂k∂L∂b∂L=n1i=1∑n(kxi+b−yi)⋅xi=n1i=1∑n(kxi+b−yi)
算法实现
# 模型函数
def f(x,k,b):
return k*x+b
# 损失函数
def L(x,y,k,b):
s = 0
n = len(x)
for i in range(len(x)):
s += (k*x[i]+b-y[i])**2
return s/2
# k梯度
def grad_k(x,y,k,b):
s = 0
n = len(x)
for i in range(n):
s += (k*x[i]+b-y[i])*x[i]
return s/n
# b梯度
def grad_b(x,y,k,b):
s = 0
n = len(x)
for i in range(n):
s += (k*x[i]+b-y[i])
return s/n
# 初始化参数
k = 0
b = 0
times = 100 # 训练次数
alpha = 0.01 # 步长
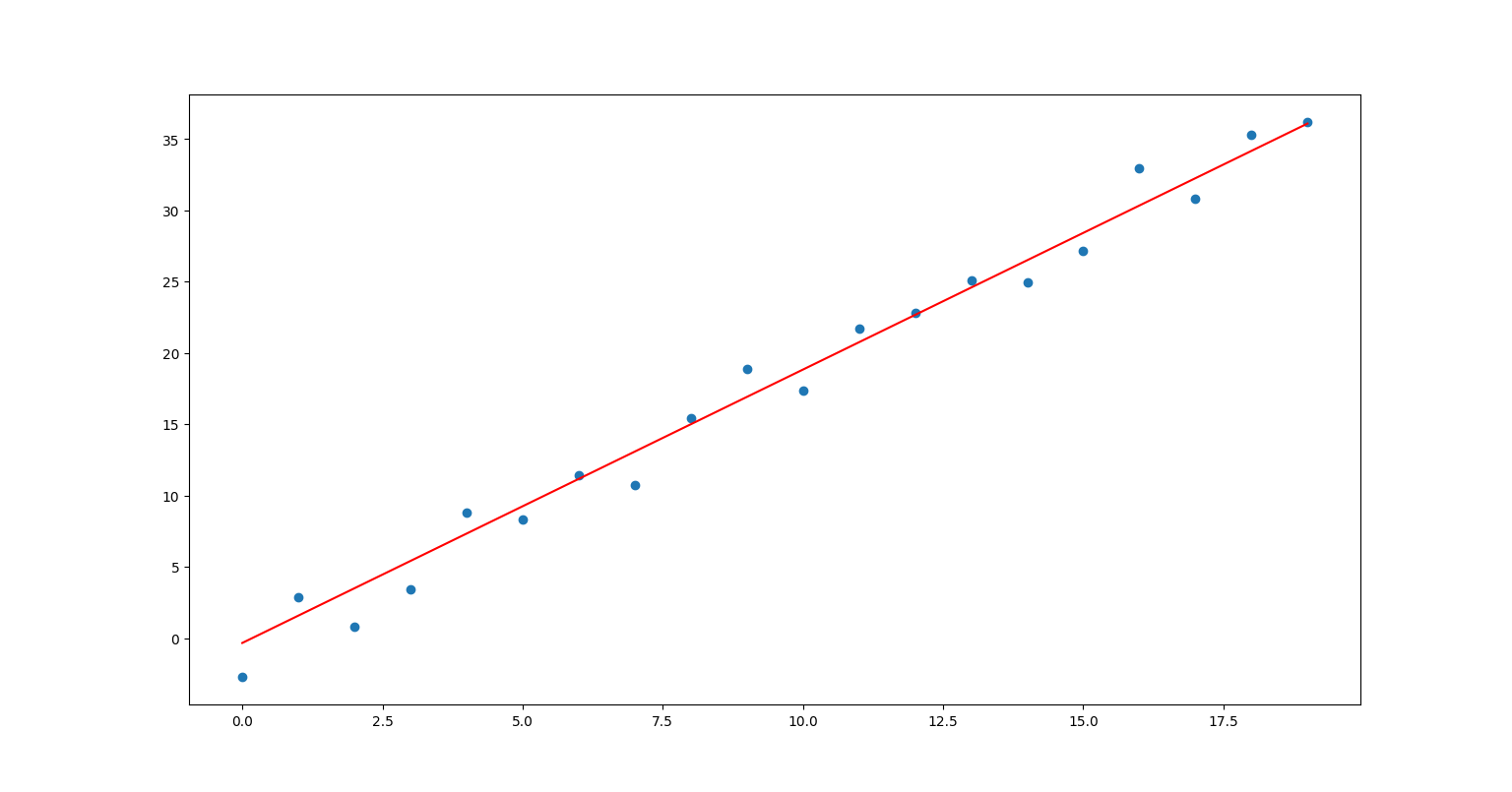
for i in range(times):
# 梯度下降迭代
k = k - alpha*grad_k(px,py,k,b)
b = b - alpha*grad_b(px,py,k,b)
if i%20 == 0:
print("%d:%.2f"%(i,L(px,py,k,b))) # 输出当前损失函数
plt.plot(px,f(px,k,b),c = "red") # 绘制训练结果
plt.show()
完整代码
import numpy as np
import matplotlib.pyplot as plt
num = 20 # 散点数目
# --------------数据生成----------------
px = np.arange(num)
py = 2*px-4+5*np.random.random(num) # 加上噪声
# 散点图
plt.scatter(px,py)
# plt.show()
# --------------模型搭建-----------------
# 模型函数
def f(x,k,b):
return k*x+b
# 损失函数
def L(x,y,k,b):
s = 0
n = len(x)
for i in range(len(x)):
s += (k*x[i]+b-y[i])**2
return s/2
# k梯度
def grad_k(x,y,k,b):
s = 0
n = len(x)
for i in range(n):
s += (k*x[i]+b-y[i])*x[i]
return s/n
# b梯度
def grad_b(x,y,k,b):
s = 0
n = len(x)
for i in range(n):
s += (k*x[i]+b-y[i])
return s/n
# --------------梯度下降-----------------
# 初始化参数
k = 0
b = 0
times = 100 # 训练次数
alpha = 0.01 # 步长
for i in range(times):
# 梯度下降迭代
k = k - alpha*grad_k(px,py,k,b)
b = b - alpha*grad_b(px,py,k,b)
if i%20 == 0:
print("%d:%.2f"%(i,L(px,py,k,b))) # 输出当前损失函数
plt.plot(px,f(px,k,b),c = "red") # 绘制训练结果
plt.show()














 9511
9511











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









