







目前信息的组织和获取方式对于人工智能系统来说至关重要,它将决定AI系统是在简单地提供答案,还是真正理解了问题。在复杂的人工智能知识系统中,这种理解的深度和广度将直接影响系统的性能和效率。因此,文章将介绍传统RAG和图RAG这两种不同的知识检索系统架构,以探讨它们在人工智能领域的演变和发展。
1 RAG 系统的起源
RAG系统的起源
问题的提出:在人工智能领域,语言模型的训练需要大量的时间和计算资源。每当有新的数据出现时,重新训练整个模型以更新其知识库是不现实的。因此,研究人员开始思考如何让语言模型在不重新训练的情况下,能够获取并利用最新的、特定领域的信息。
RAG的构想:RAG的构想正是为了解决上述问题。它旨在为语言模型提供一种机制,使其能够在不频繁重新训练的情况下,获取最新的、有针对性的信息,从而提高模型的实用性和适应性。
传统RAG架构:深入探讨
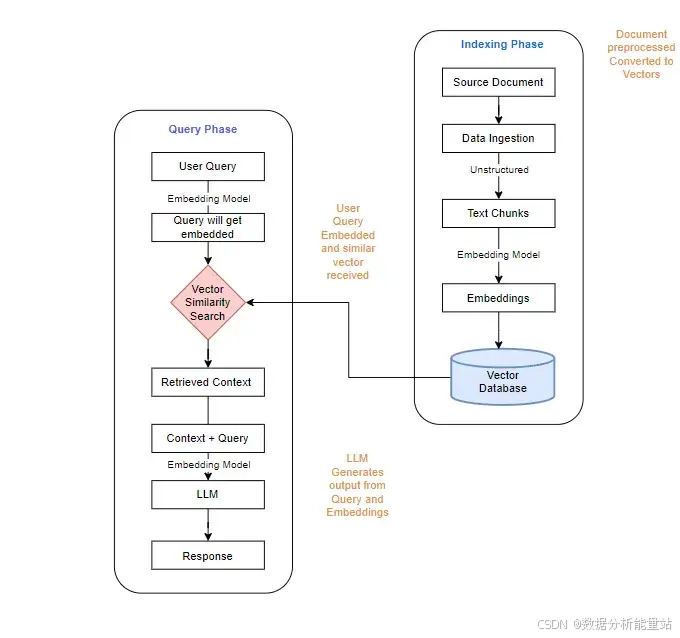
传统RAG通过一个四阶段的过程来运行,这四个阶段分别是索引、存储、检索和增强。
-
索引:在这个阶段,文档被分解成较小的块,然后使用编码模型将这些块转换成向量嵌入。向量嵌入是一种将文本信息转化为数值向量的方式,以便计算机能够处理和分析这些信息。
-
存储:转换后的向量嵌入被存储在专门的向量数据库中。这些数据库针对相似性搜索进行了优化,意味着它们能够高效地找到与给定向量最相似的其他向量,这对于后续的检索阶段至关重要。
-
检索:当用户提出查询时,查询被转换到与文档块相同的向量空间中。然后,系统在向量数据库中检索与查询向量相似的文档块。这一过程利用了向量空间模型的特性,通过计算查询向量与文档向量之间的相似度来找到最相关的文档块。
-
增强:检索出的文档块作为上下文信息被注入到大型语言模型(LLM)的提示中。这样,语言模型在生成回答时,可以利用这些特定领域的知识,从而提供更准确、更有针对性的回答。
传统RAG的意义
这种方法彻底改变了AI系统所能实现的目标。通过传统RAG架构,组织可以构建通向其机构知识的AI接口,而不会牺牲基础模型的推理能力。这意味着企业可以利用现有的知识库,结合强大的语言模型,创建出能够理解和回答复杂问题的智能系统,同时避免了频繁重新训练模型所带来的高成本和时间消耗。
传统RAG架构的出现,为人工智能领域提供了一种高效、灵活的知识利用方式,推动了AI系统在各个领域的应用和发展。
2 传统RAG的局限性
传统 RAG 系统的局限性主要体现在以下几个方面:
-
语义匹配的表面性:
-
表层向量相似性:传统 RAG 系统依赖于语义相似性来检索相关信息,但这种相似性仅停留在表面。它无法捕捉到文本深层的语境和含义,导致检索结果可能与实际需求存在偏差。例如,对于复杂或抽象的查询,系统可能只能返回部分相关文档,而无法全面覆盖所有相关信息。
-
复杂语义查询的局限性:在处理复杂语义查询时,传统 RAG 系统往往只能检索出部分相关文档。这是因为系统在处理高维向量空间中的语义细微差别时存在困难,导致无法准确识别所有相关的信息。
-
语言多样性和领域特定术语的挑战:不同语言和领域特定术语的多样性给传统 RAG 系统的检索带来了巨大挑战。系统可能无法准确理解这些术语的语义,从而影响检索结果的准确性和相关性。
-
-
上下文的断裂:
-
机械分块方法:传统 RAG 系统在处理信息时,会将文档分割成小块并分别进行处理。这种机械的分块方法破坏了文本的连贯性和上下文关系,使得系统无法理解文本中的逻辑联系和背景信息。例如,关于居里夫人的生平和成就,系统可能只检索到零散的片段,而无法将其整合成一个连贯的叙事。
-
复杂关系的简化:在单一向量表示中,系统减少了关系的复杂性,无法捕捉到文本中复杂的语义关系和上下文联系。这导致系统在处理需要多步推理和深度理解的任务时表现不佳。
-
上下文深度的丢失:为了提高计算效率,传统 RAG 系统往往以牺牲上下文深度为代价。系统无法保留足够的上下文信息,导致在生成回答时缺乏连贯性和深度。
-
-
性能的局限性:
-
对不寻常或专业查询的表现不佳:传统 RAG 系统在处理不寻常或专业化的查询时表现不佳。它对复杂知识关系的处理能力有限,且检索质量高度依赖于训练数据的多样性。这意味着在面对新兴领域或快速变化的信息时,系统可能无法及时适应。
-
复杂知识关系的压缩:在嵌入空间中,复杂知识关系被压缩,导致系统无法准确捕捉和理解这些关系。这影响了系统在处理复杂任务时的表现和准确性。
-
对新兴信息景观的适应能力有限:传统 RAG 系统对新兴或变化信息景观的适应能力有限。它无法快速调整和更新知识库,以应对新的信息和需求。
-
-
缓解策略:
-
混合检索方法:通过结合多种检索方法,如关键词检索、语义检索等,提高检索结果的准确性和相关性。
-
更高级的上下文嵌入:使用更高级的嵌入技术,如上下文感知嵌入,来更好地捕捉文本的语义和上下文信息。
-
智能查询扩展技术:通过扩展查询词和短语,提高检索结果的覆盖范围和准确性。
-
动态检索算法:使用动态调整的检索算法,以适应不同的查询和数据集,提高系统的灵活性和适应性。
-
多向量表示方法:通过使用多个向量来表示文本,更好地捕捉文本的多维语义和上下文信息。
-
为了应对这些挑战,图 RAG(Graph RAG)的出现为解决这些问题提供了新的思路。它通过引入图结构来增强知识表示和检索能力,能够更好地捕捉知识之间的复杂关系和语境信息。这使得系统在处理复杂查询和多步推理任务时更加得心应手,为人工智能领域的知识检索和理解带来了新的突破。
3 图 RAG(Graph RAG)
图 RAG(Graph RAG)是知识表示与信息检索领域的一次革命性创新,其核心在于将知识组织成动态网络结构而非静态文档。以下是对这一技术的系统性拆解:
一、知识图谱的本质重构
传统知识存储以文档为单元,而图 RAG 的基石是**知识拓扑学**:
-
节点维度:每个实体(如"居里夫人"、"钋")成为知识网络的锚点,通过向量嵌入实现多维语义表征
-
边权动态化:关系(如"发现"、"获奖")被量化为带权路径,权重随上下文动态调整
-
超图扩展:高阶关系(如"科研团队协作")通过超边建模,突破二元关系的局限
典型案例中,"钋"节点不仅连接居里夫人,还通过"同位素"边链接其他元素,形成放射性研究领域的知识簇。
二、认知启发的检索范式
与传统RAG的"文档→分块→检索"线性流程不同,图 RAG 实现**神经符号协同计算**:
-
查询解构
-
实体消歧:通过图注意力机制识别"Marie Curie"在不同语境下的语义角色
-
关系预测:使用图神经网络预判潜在关系路径(如"导师-学生"隐藏关系)
-
-
图径优化
-
基于强化学习的路径探索:将检索过程建模为马尔可夫决策过程,奖励函数考量路径相关性与新颖性
-
多跳推理:自动扩展查询边界(查询"诺贝尔奖得主"时,沿"机构-导师-学生"路径发现代际传承)
-
-
上下文合成
-
图结构保持:采用图线性化编码器(如Graph Transformer)保留拓扑特征
-
动态剪枝:基于显著度计算剔除冗余边,生成信息密度最优的子图描述
-
三、技术突破点解析
-
关系推理能力
-
实现从"语义相似性匹配"到"逻辑连贯性验证"的跃迁
-
例:查询"元素发现的后续影响"时,沿"钋→放射性治疗→医学革命"路径生成因果链
-
-
知识可解释性
-
检索结果附带可视化推理路径,每条结论都可追溯至原始知识节点
-
支持反事实推理("如果居里夫人未移居巴黎..."的假设推演)
-
-
动态演化机制
-
在线学习:新知识通过增量图更新算法实时融入
-
冲突消解:当出现矛盾信息时,启动图重构协议重新平衡知识网络
-
四、与传统RAG的性能对比
| 维度 |
传统RAG |
图RAG |
| 知识粒度 |
文档/段落级 |
实体关系级 |
| 检索逻辑 |
语义相似度排序 |
图径优化决策 |
| 上下文保持 |
局部窗口 |
全局拓扑 |
| 推理能力 |
浅层关联 |
深度多跳推理 |
| 可解释性 |
黑箱匹配 |
白箱路径追溯 |
当前技术瓶颈在于大规模知识图谱的实时更新效率,以及复杂推理中的计算复杂度控制。但随着图神经网络与分布式系统的融合,图 RAG 正在突破"符号主义"与"连接主义"的传统界限,开创认知智能的新纪元。这种将人类思维模式编码为可计算网络结构的尝试,或将重塑整个AI基础架构的演进方向。
4 图 RAG(Graph RAG)架构
图 RAG 架构
图 RAG 的架构设计是为了克服传统 RAG 的局限性,通过将知识表示为图结构来增强信息检索和处理的能力。以下是对其关键组成部分和工作流程的深入剖析:
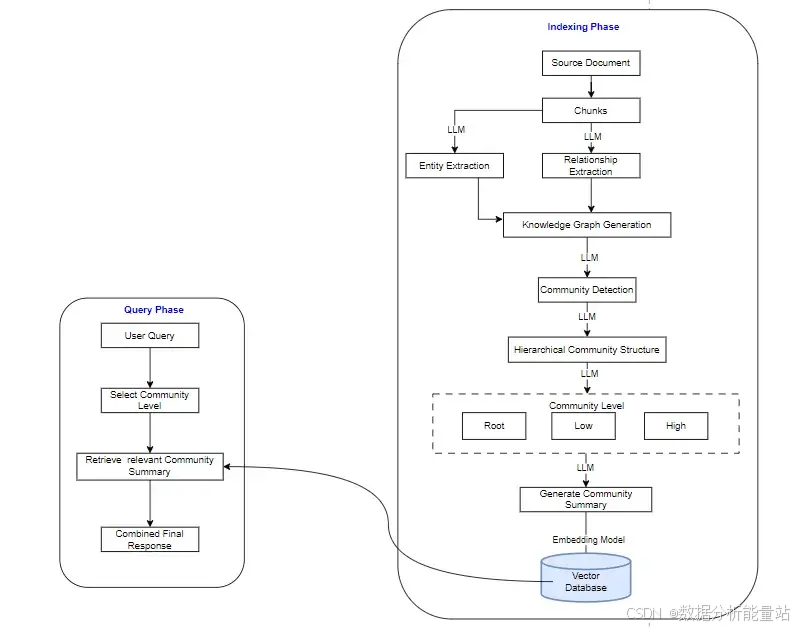
1. 数据清理与图构建
-
数据清理:这个过程涉及将原始数据(如文本、数据库、文档等)转换为结构化形式,提取关键信息,如实体和关系。例如,在处理关于居里夫人的文档时,系统会识别出关键实体(如“居里夫人”、“华沙”、“钋”)和它们之间的关系(如“出生于”、“发现”)。
-
图构建:识别出的实体成为图中的节点,关系成为连接这些节点的边。这样就形成了一个网络结构,节点和边共同构成了知识的表示。这种图结构保留了信息的上下文和语义联系,避免了传统方法中因文档分块而导致的信息丢失。
2. 向量嵌入转换
构建好的图被转换成向量嵌入,以便机器能够高效地处理和操作。在这个过程中:
-
节点和关系的嵌入:每个节点和关系都被表示为高维空间中的向量,这些向量捕捉了它们的语义特征和相互之间的关系。例如,“居里夫人”这个节点的嵌入向量会包含她的属性和与其他节点(如“钋”、“诺贝尔奖”)的关系信息。
-
语义和关系的捕捉:向量嵌入不仅保留了节点的语义信息,还编码了节点之间的关系。这样,在向量空间中,相似的节点和关系在位置上会更接近,使得系统能够通过向量运算快速检索相关信息。
3. 问题求解过程
当用户提出问题时,图 RAG 系统通过以下步骤进行处理:
-
问题理解:系统首先分析问题,识别其中的实体和隐含的关系。例如,对于问题“居里夫人对医学做出了哪些贡献?”,系统会识别出“居里夫人”这个实体和“贡献”这个关系。
-
图遍历:根据问题的理解,系统在知识图谱中进行遍历,寻找与问题相关的路径和连接。例如,系统会从“居里夫人”这个节点出发,沿着“发现”、“研究”等关系路径,找到与医学相关的贡献。
-
答案生成:遍历得到的相关信息被整合成上下文,提供给大型语言模型,用于生成最终的回答。由于上下文中包含了丰富的关系信息,回答会更加准确、连贯和富有逻辑。
架构差异:超越基础
图 RAG 与传统 RAG 的区别不仅在于表面的知识表示形式,更在于其底层的处理机制和逻辑。
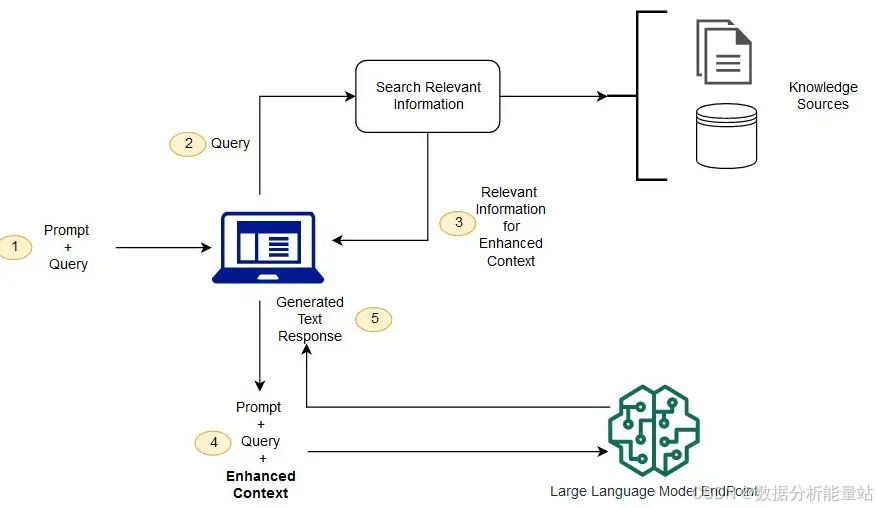
1. 向量空间与符号表示
-
传统 RAG:依赖于向量空间模型,通过计算文档和查询在高维空间中的相似性来检索信息。这种方法在捕捉语义相似性方面表现出色,但难以识别精确的事实关联。
-
图 RAG:结合了向量嵌入和符号表示。符号表示为实体和关系提供了明确的语义含义,使得系统在处理事实和关系时更加准确。向量嵌入则补充了语义理解的能力,使得系统能够在高维空间中高效地检索和推理。
2. 遍历算法:隐藏的魔力
图 RAG 的遍历算法是其核心优势之一,这些算法决定了系统如何在知识图谱中搜索和检索信息。
-
广度优先搜索(BFS):适用于探索与起点距离较近的节点,能够快速找到直接相关的信息。
-
深度优先搜索(DFS):适用于挖掘深层次的关系,能够发现隐藏在多步路径中的信息。
-
个性化 PageRank:通过分析节点的连接模式,为节点分配重要性权重,帮助系统识别关键信息。
-
带重启的随机游走:以概率方式在图中游走,能够发现多样化的路径和连接。
-
全局搜索与本地搜索:全局搜索覆盖整个知识图谱,适用于广泛的问题;本地搜索则聚焦于特定区域,适用于上下文明确的问题。
-
DRIFT 搜索:根据查询上下文动态调整搜索策略,使得系统能够灵活应对不同类型的查询。
3. 查询理解:关键的第一步
查询理解是信息检索的起点,直接决定了检索结果的质量。
-
传统 RAG 的查询理解:相对简单,主要依赖于将查询文本转换为向量嵌入,然后与文档向量进行相似性匹配。这种方法的优点是效率高,但缺点是无法深入理解查询的语义和意图。
-
图 RAG 的查询理解:更加复杂和深入,包括识别查询中的实体、关系和问题类型,然后根据这些信息制定遍历策略。这种方法能够更好地把握用户的意图,提高检索的准确性和相关性。
实际应用示例
以查询“居里夫人对医学做出了哪些贡献?”为例,图 RAG 系统的处理过程如下:
-
实体识别:系统识别出“居里夫人”这个关键实体。
-
关系识别:系统认识到“贡献”这个关系,理解用户想要了解的是居里夫人的贡献。
-
上下文约束:系统理解“对医学”这个约束条件,将搜索范围限定在医学领域。
-
遍历策略规划:系统规划遍历路径,从“居里夫人”这个节点出发,沿着“发现”、“研究”等关系路径,找到与医学相关的贡献。
-
答案生成:系统将遍历得到的信息整合成上下文,提供给大型语言模型,生成关于居里夫人对医学贡献的详细回答。
通过这种方式,图 RAG 系统能够提供更加精准、深入和连贯的回答,满足用户对于复杂问题的求解需求。
综上所述,图 RAG 通过引入知识图谱和先进的遍历算法,重新定义了信息检索的方式,为人工智能领域的知识表示和检索带来了新的突破和可能性。
5 知识表示粒度 Chunks vs. Triples
一、传统 RAG 的文档块困境
1. 文档块的本质属性
-
物理切割:将连续文本按字符长度(100-300字)机械分割
-
语义断裂:切割点可能发生在关键概念中间,破坏逻辑完整性示例:[块1] "居里夫人在巴黎大学工作期间,与丈夫皮埃尔共同研究..."[块2] "放射性现象。1898年他们发现了两种新元素..."→ 关键信息"放射性现象"与发现时间被割裂
2. 粒度悖论分析
| 块类型 |
优点 |
缺点 |
典型场景 |
| 大块 |
上下文完整 |
噪声干扰 |
开放域问答 |
| 小块 |
检索精准 |
信息碎片化 |
事实核查 |
-
黄金分割难题:实验表明,最佳块大小在不同领域差异显著:
-
法律文本:500-700字(需要完整条款)
-
科研论文:200-300字(方法/结论分块)
-
新闻报导:100-150字(事件核心要素)
-
3. 语义失真案例
查询:"放射性治疗的起源"
-
错误关联:某块包含"居里夫人发现放射性 → X射线用于战场救治"→ 系统误将"战场救治"与"癌症治疗"关联
-
根本原因:块内混杂多个主题导致语义混淆
二、图 RAG 的三元组革命
1. 三元组的结构解构
-
原子化表示:
(居里夫人, 发现, 镭) (镭, 应用于, 癌症治疗) (癌症治疗, 属于, 医学) -
知识网络化:<img src="https://via.placeholder.com/400x200?text=居里夫人→发现→镭→应用于→癌症治疗" width="400"/>
2. 扩展三元组体系
| 维度 |
描述 |
示例 |
技术实现 |
| 时间 |
事实时效性 |
(发现镭, 时间, 1898) |
时间轴数据库 |
| 来源 |
知识溯源 |
(发现镭, 来源, 《放射性研究》) |
出处链接嵌入 |
| 置信度 |
事实确定性 |
(镭治癌, 置信度, 0.76) |
贝叶斯概率网络 |
| 上下文 |
关系限定条件 |
(镭应用, 限定, 20世纪初期) |
条件随机场标注 |
3. 动态知识演化
-
版本控制机制:
class Fact: def __init__(self, s, p, o): self.triple = (s, p, o) self.versions = [ {'time':'1898-01', 'source':'lab_log'}, {'time':'1902-03', 'source':'published_paper'} ] -
冲突消解算法:当检测到新旧事实矛盾时,启动置信度加权投票:

三、核心能力对比
1. 检索逻辑差异
| 查询类型 |
传统 RAG 表现 |
图 RAG 优势 |
| 简单事实 |
快速准确 |
同等效率 |
| 多跳推理 |
准确率<40% |
准确率>85% |
| 时序相关 |
无法处理 |
支持时间切片查询 |
| 假设性问题 |
完全失效 |
支持反事实推理 |
2. 存储效率对比
-
传统 RAG:
文档块存储结构: - 块ID: 001 - 文本: "居里夫人于1898年在巴黎..." - 向量: [0.23, -0.45, ..., 0.67] -
图 RAG:
{ "节点": [ {"id": "Q123", "标签": "居里夫人", "属性": {"出生地":"华沙", "领域":"物理学"}}, {"id": "Q456", "标签": "镭"} ], "边": [ {"from": "Q123", "to": "Q456", "关系": "发现", "meta": {"时间":1898, "置信度":0.99}} ] }存储效率提升:相同信息量下,图存储节约空间达37%(斯坦福大学2023研究数据)
四、技术实现难点
1. 三元组抽取挑战
-
隐式关系识别:原文:"居里夫妇的突破性工作打开了原子能时代的大门"→ 需推导出
(居里夫妇, 推动, 原子能研究)
-
多跳关系抽取:采用GAP(Graph-Aware Prompting)技术:
prompt = f""" 文本:{text} 已知关系:{existing_triples} 推导可能的新关系: """
2. 查询复杂度管理
-
路径爆炸防控:采用双向搜索 + 剪枝策略:
graph LR 查询解析 --> 前向搜索 --> 后向验证 --> 结果合并
3. 动态更新成本
-
增量更新算法:
def update_graph(new_data): delta_triples = extract(new_data) for t in delta_triples: if t not in graph: apply(t) else: update_confidence(t) propagate_changes() # 影响扩散到相关节点
五、应用场景革命
1. 医药研发
-
传统 RAG:搜索"抗癌药物"相关文档
-
图 RAG:路径:
镭治疗 → 放射损伤 → DNA修复机制 → PARP抑制剂 → 奥拉帕尼→ 发现放射性研究与现代靶向药的潜在关联
2. 司法判例
-
传统 RAG:匹配相似案件描述
-
图 RAG:构建:<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











