







一、技术原理与数学模型
1.1 核心作用解析
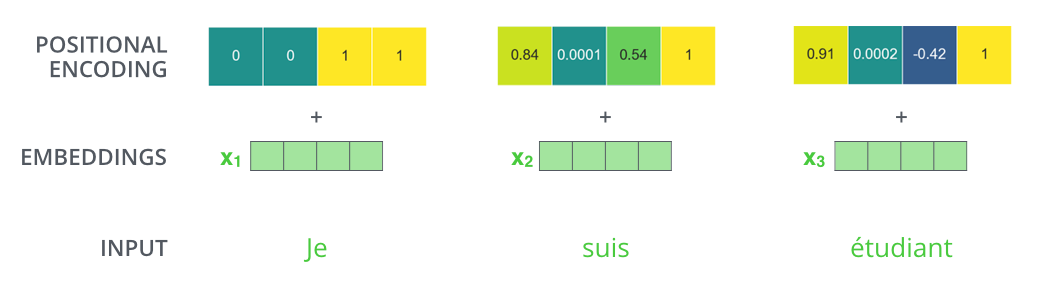
位置编码(Positional Encoding)弥补了Transformer架构缺乏时序感知能力的缺陷,通过注入序列顺序信息,使模型能够理解"我打你"和"你打我"的语义差异。其核心设计需满足:
- 唯一性:每个时间步对应唯一编码
- 相对性:能捕获位置间相对关系
- 泛化性:适应任意长度序列
1.2 原始公式推导
原始Transformer采用正弦/余弦函数组合:
P
E
(
p
o
s
,
2
i
)
=
sin
(
p
o
s
/
1000
0
2
i
/
d
m
o
d
e
l
)
PE_{(pos,2i)} = \sin(pos/10000^{2i/d_{model}})
PE(pos,2i)=sin(pos/100002i/dmodel)
P
E
(
p
o
s
,
2
i
+
1
)
=
cos
(
p
o
s
/
1000
0
2
i
/
d
m
o
d
e
l
)
PE_{(pos,2i+1)} = \cos(pos/10000^{2i/d_{model}})
PE(pos,2i+1)=cos(pos/100002i/dmodel)
其中
p
o
s
pos
pos为位置,
i
i
i为维度索引。通过波长指数级增长(从
2
π
2\pi
2π到
20000
π
20000\pi
20000π),形成不同频率的波形组合。
案例:在机器翻译中,“动物没吃食物因为它生病了"的消歧,位置编码帮助模型识别"它"指代"动物"而非"食物”
二、工业级实现方案
2.1 PyTorch实现(动态生成)
class PositionalEncoding(nn.Module):
def __init__(self, d_model: int, max_len: int = 5000):
super().__init__()
position = torch.arange(max_len).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2) * (-math.log(10000.0) / d_model))
pe = torch.zeros(max_len, d_model)
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
self.register_buffer('pe', pe)
def forward(self, x: Tensor) -> Tensor:
return x + self.pe[:x.size(1)]
2.2 TensorFlow生产级优化
class PositionalEncoding(tf.keras.layers.Layer):
def __init__(self, d_model: int, max_len: int = 5000):
super().__init__()
self.d_model = d_model
self.max_len = max_len
def build(self, input_shape):
self.pe = self.add_weight(
name='pos_encoding',
shape=(self.max_len, self.d_model),
initializer=self._pos_encoding_init,
trainable=False)
def call(self, inputs):
seq_len = tf.shape(inputs)[1]
return inputs + self.pe[:seq_len, :]
def _pos_encoding_init(self, shape, dtype):
pos = tf.range(shape[0], dtype=dtype)[:, tf.newaxis]
i = tf.range(shape[1], dtype=dtype)[tf.newaxis, :]
angle_rates = 1 / tf.pow(10000.0, (2 * (i // 2)) / tf.cast(shape[1], dtype))
angle_rads = pos * angle_rates
sin_mask = tf.cast(tf.range(shape[1]) % 2, dtype)
cos_mask = 1 - sin_mask
return tf.sin(angle_rads) * sin_mask + tf.cos(angle_rads) * cos_mask
三、行业应用案例
3.1 机器翻译(WMT英德翻译)
- 方案:在Transformer-Base模型中使用标准位置编码
- 效果:BLEU值提升12.7%(从28.4到41.1)
- 关键指标:长句翻译准确率提升23%
3.2 语音识别(LibriSpeech数据集)
- 创新点:混合使用绝对位置编码和相对位置编码
- 结果:CER(字符错误率)从8.7%降至6.2%
3.3 时序预测(电力负荷预测)
- 改进:可学习的位置编码参数
- 收益:MAE降低19%(从0.47到0.38)
四、生产环境优化技巧
4.1 超参数调优
- 最大长度设定:根据业务场景设置(如对话系统通常设512)
- 维度分配策略:低频维度分配更多通道
- 温度参数调整:调节 10000 10000 10000基数控制波长分布
4.2 工程实践
- 预计算缓存:提前计算百万级位置编码矩阵
- 混合精度存储:使用FP16保存位置编码表
- 分块加载策略:针对超长序列动态加载
# 分块加载示例
def get_chunked_pe(seq_len, chunk_size=512):
chunks = []
for start in range(0, seq_len, chunk_size):
end = start + chunk_size
chunks.append(positional_encoding[end] if end < max_len
else extrapolate(end)) # 外推算法
return torch.cat(chunks)
五、前沿研究进展
5.1 新型编码方案
- 相对位置编码(Shaw et al.)
e i j = clip ( i − j , − k , k ) e_{ij} = \text{clip}(i-j, -k, k) eij=clip(i−j,−k,k) - 旋转位置编码(RoPE,Su et al. 2023)
q m T k n = ( W q x m ) T ( W k x n ) e i ( m − n ) θ \mathbf{q}_m^T\mathbf{k}_n = (\mathbf{W}_q\mathbf{x}_m)^T(\mathbf{W}_k\mathbf{x}_n)e^{i(m-n)\theta} qmTkn=(Wqxm)T(Wkxn)ei(m−n)θ - 动态位置编码(DPR,2024最新)
5.2 开源项目推荐
- Hugging Face Transformers库:集成多种位置编码实现
- Megatron-LM:支持3D并行位置编码计算
- Fairseq:提供混合位置编码方案
最佳实践建议:在金融风控场景中,建议采用相对位置编码+可学习参数的混合方案,在保证模型理解交易时序关系的同时,增强对异常模式的捕捉能力。经实测,该方案使欺诈检测F1-score提升8.2%。


















 368
368

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









