







原论文:《Automatic Synonym Discovery with Knowledge Bases》
背景知识
同义词抽取是一种NLP领域下游任务使用广泛的基础任务,可以用于实体归一、融合,实体链接,query改写,提高召回等任务。现有的方法有:1)直接利用Freebase, WordNet等知识库直接扩充,但这对于领域的实体覆盖率很低;2)人工维护同义词典,成本非常高;3)监督/弱监督方法,训练一个同义词分类器,检测出固定的句式pattern来挖掘同义词,但也需要依赖人工精细的选择一些种子训练数据。本文就提供了一种自动从大规模领域预料中抽取实体同义词的方法。
远程监督:从知识库中自动收集训练种子,流程为:1)从语料中检测出实体;2)将实体链接到知识库中;3)从知识库中收集训练种子。远程监督广泛用于关系收取,实体分类,情感分类等任务,但远程监督也回来带来很多噪音,因为相同的实体文本会被链接到不同的实体中。比如
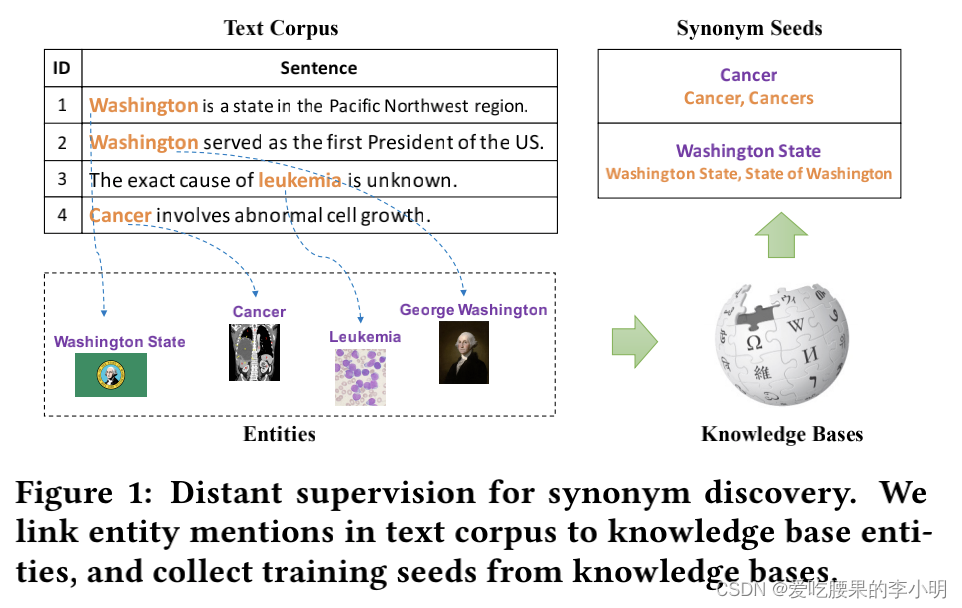
华盛顿这个同义词可以代表地名“华盛顿州”,也可以代表人名,在链接到实体库的时候可能会返回这两个结果。所以与其使用有歧义的字符串当作query,更好的方法是利用一些特殊的概念作为query,比如知识库中的实体,因为知识库中的实体会带有一些额外的信息来帮助消歧。
利用知识库中现有的实体-同义词作为种子数据,然后利用已有的实体同义词来对新的同义字符串做消歧,用投票的方法来选择是否接受这个同义词作为新的同义词。这样的话,同义词挖掘的任务就变成了:给定一对候选字符串,判断他们之间的关系是否是同义(关系分类)。但问题又来了,现有的同义词库中的种子训练数据非常少,如何更有效的利用这些种子数据呢?有以下两种方式:
1. 基于分布的方法
考虑语料级别的统计特征。这里暗含一个假设:即有同义关系的pair对经常出现在相似的文本中。基于这个假设,该方法通常利用pair对的分布特征来做表示,利用种子数据作为label训练一个分类起来预测一个给定的pair对是否是同义的。但这种方法也会带来一些噪音,用过word Embedding的同学都知道,有一些经常在一起出现的,但未必是同义的pair对语义的,比如“阿里”和“腾讯”经常一起出现。
2. 基于pattern识别的方法
比如中文句式,“XX,学名XX”。具有同义语义的pair对通常会符合某些pattern,学习更多的pattern就可以发现更多的同义词对。这种方法的可解释性非常强,但召回率会偏低。
3. 基于融合的方法(本文)
DPE(distributional and pattern integrated embedding framework),包含了统计特征模块(global)和pattern模块(local)。两个模块同用词的embedding,利用种子数据做监督训练更新词的embedding并预测同义关系,这样两个模块共享信息,会提升学习效率。
在判断同义关系时,直接方法是对所有的候选实体对都判断是否存在同义关系,这个pair对数量很大,模型速度也会变慢,可以利用统计模块来对所有pair对进行排序,取topK的高潜pair重排序,再进行关系分类。
模型架构
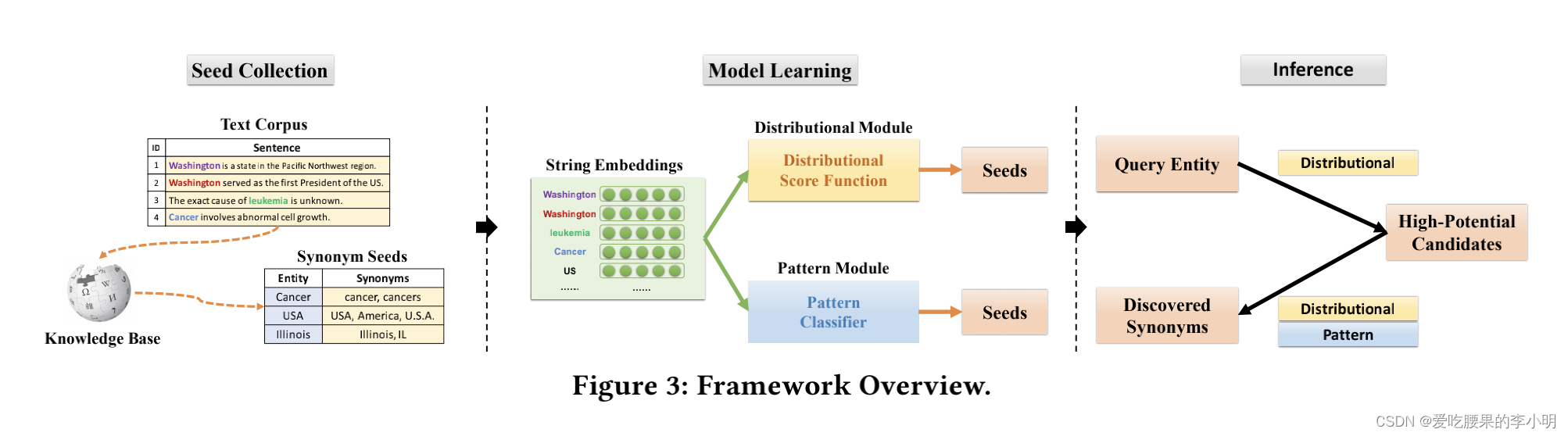
1. 对给定的语料进行实体识别,并链接到给定的知识库中,收集同义的种子做监督
在实体链接的时候会出现一些错误种子,为了保证种子的质量,只选取那些mention在同义词/实体本身的做链接,其余的链接会被移除。
2. 联合优化分布特征模块(利用global分布特征)和pattern模块 (利用local context特征)
用embedding的方法表示mention string的语义(包含已经实体链接的词和没有链接的词)。对于链接到不同实体的mention string,利用不同的embedding表示他们。比如“苹果”被链接到水果的表示和被链接到公司的表示是不同的。
统计特征和pattern特征两个模块共用底层的embedding,利用种子数据做同义关系预测,并反向传播更新embedding。两个模块joint训练的好处不仅可以提升预测能力,还可以让单个模块从另一个模块中学习“知识”,从而相互提高学习效率。
2.1 分布特征模块
包含了非监督部分和监督部分;
在非监督部分中,对含有mention的string构建共现网络的分布信息进行编码。首先构建词的贡献网络,利用一个大小为w的滑动窗口体现词的共现特征。每个pair的权重被定义成是贡献网络中的贡献次数,文中发现string的贡献次数与下面两个因素有关:1)语义相似的两个string更容易共现;2)一个string趋向与另一个string出现的文本中,那这两个string更容易共现
无监督部分:
在监督部分中,利用同义词种子学习分布score函数,来让string的embeeding作为特征预测同义关系。例如“数据挖掘”和“文本挖掘”共现的机会更多,具有高度的相关性,但“数据挖掘”与“物理学”共现的机会就很少。但即使语义不同的词也会经常共现,比如“首都”和“北京”。于是有
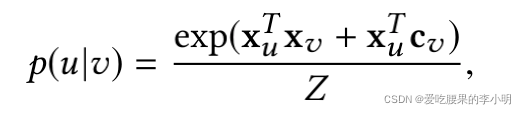
其中c_v是context vector,代表了更容易共通提及的v所属于的种类,x表示embedding,Z是归一化项,u v向量相似表示有相近的语义,那么这一项就会很大(对应因素1)。如果u的向量接近v的内容向量,说明u会经常出现在v所在的内容中,所以
项就会很大(对应因素2)。
最小化期望分布和经验分布
的KL散度,其中
是两个string的贡献次数,
是共现图中v的度。构建优化目标:
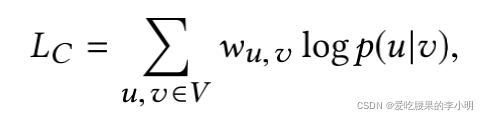
由于直接优化上述目标计算复杂度很大,采用和word2vec相同的负采样技术
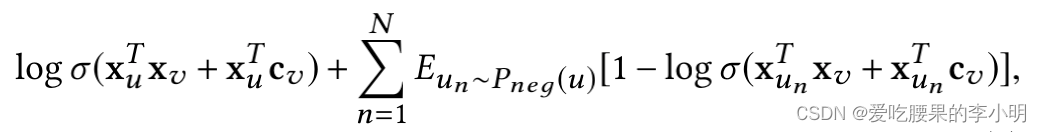
第一项是最大话同义pair正例的概率,第二项最小化噪声负样本概率。
监督部分:
使用同义种子对来训练同义关系分类器的分布函数。引入了两个词有多同义的衡量标准,利用双线性函数定义pair对(u,v)的同义性得分
![]()
其中是得分函数的参数矩阵,为了简化计算,
设置为对角矩阵,同义的string pair对得分要大于不同义的string pair对得分,可以基于排序目标优化学习:

2.2 pattern模型
pattern模型的目标是预测句子中mention的关系是否是同义。对于每个句子,会先抽取pattern,并收集部分语法特征和语义特征来表示pattern,最终整合所有的pattern来决定string的同义关系。
定义pattern为一个三元组<词法,POS标签,依赖标签>。
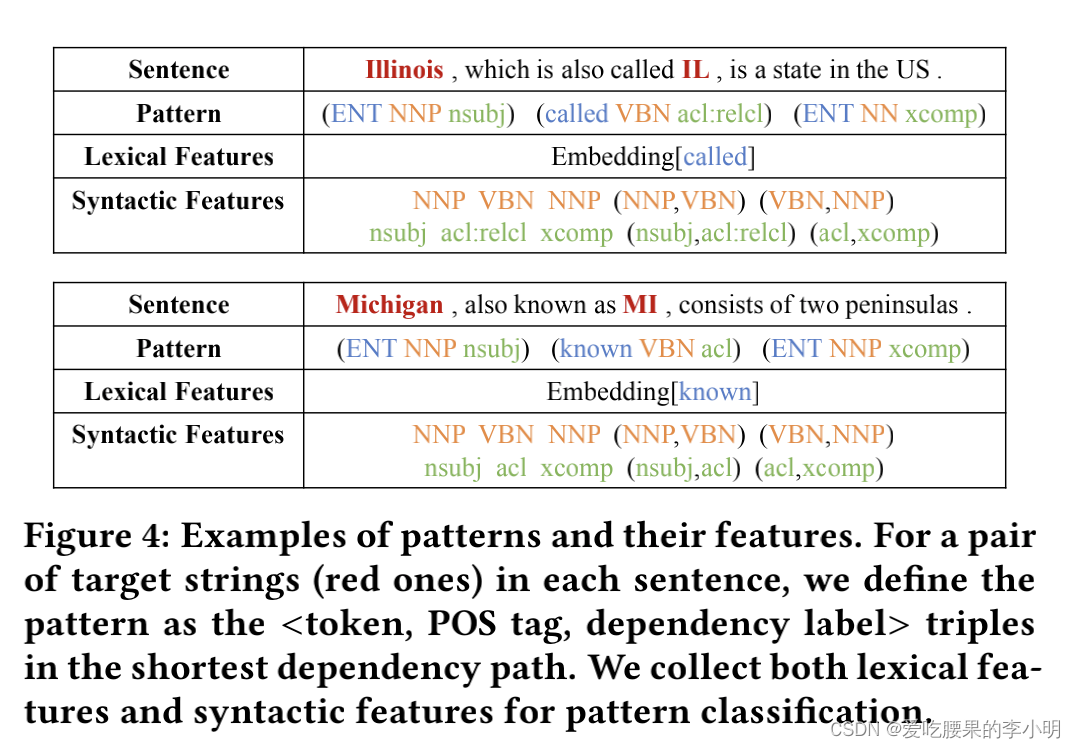
同义关系的pattern表达要有相似的特征。“called”和“known”经常在相似的文本中出现,所以他们的embedding非常接近,这两个pattern也会有相近的词法特征。而句法特征则是要识别pattern中的句子结构,所以利用POS tag序列中所有的n-grams(N=2)作为句法特征。文中只利用了一个简单的逻辑回归分类器,并定义pattern是同义的概率为:
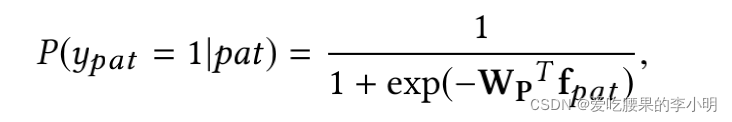
通过学习最大化似然函数为目标学习分类器的参数。
在使用时,首先收集pair对所在的sentence,抽取句子的pattern,然后利用得分函数衡量他们是同义的概率
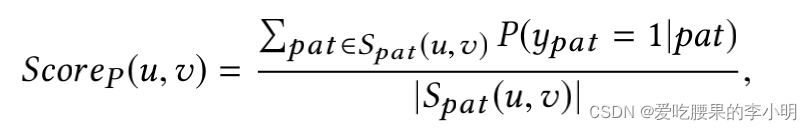
分母时所有pattern的数量,不同的pattern会通过投票的方式来判断是否具有同义关系。
3. 从联合模型中发现query实体缺失的同义词
在训练模型时,利用两个模型的目标函数作为整体的目标函数,包含了3部分,统计特征模型中的非监督和监督目标函数还有pattern模型的目标函数,采用边缘采样策略,在每次迭代过程中,交替从三个部分中采样训练样本。
在使用时,对于一个新的实体e,对于每一个候选string,通过如下函数计算同义得分:

计算e和同义种子(知识库)与每一个候选实体的得分,最后的结果由e实体的同义种子们共同投票决定每一个候选词是否是同义词。
trick:在计算pattern同义得分时,当候选string比较多时计算量就很大,可以先利用分布特征模型的得分排序,利用Top的候选来构建一波有潜力的pair对,减少候选 string的数量,然后再通过混合模型的得分重新计算选出来的候选的分数。
实验结果
感兴趣的小伙伴自己去看哈~

















 1715
1715

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









