







一、扩容场景
了解了数据迁移,我们来看下哪些场景需要进行扩容,然后有哪些方法可以实现快速扩容的效果。通常有如下两种需要紧急扩容的场景:
-
集群所有节点负载都高,需要快速扩容。
-
集群内某几台节点负载很高,需要降低这些节点的压力。
首先,来谈谈什么是节点压力。从我们的运营经验来说,Kafka集群的压力通常体现在磁盘util、CPU、网卡三个指标上。正常来说,通过加节点都可以解决这三个指标带来的问题。但是,从精细化运维的角度来说,可以有针对性地解决负载问题,达到不扩容就可以快速降低集群压力的目的。比如通过参数调优,踢掉某台故障节点/某块坏盘等等。
关于精细化运维我们在后续的文章再展开,本文主要是讨论如何能通过加节点实现快速实现集群扩容。
在生成迁移计划时,我们需要考虑以下几点:
1)选择核心指标作为生成迁移计划的依据,比如出流量、入流量、机架、单topic分区分散性等;
2)优化用来生成迁移计划的指标样本,比如过滤流量突增/突降/掉零等异常样本;
3)各资源组的迁移计划需要使用的样本全部为资源组内部样本,不涉及其他资源组,无交叉;
4)治理单分区过大topic,让topic分区分布更分散,流量不集中在部分broker,让topic单分区数据量更小,这样可以减少迁移的数据量,提升迁移速度;
5)已经均匀分散在资源组内的topic,加入迁移黑名单,不做迁移,这样可以减少迁移的数据量,提升迁移速度;
6)做topic治理,排除长期无流量topic对均衡的干扰;
7)新建topic或者topic分区扩容时,应让所有分区轮询分布在所有broker节点,轮询后余数分区优先分布流量较低的broker;
8)扩容broker节点后开启负载均衡时,优先把同一broker分配了同一大流量(流量大而不是存储空间大,这里可以认为是每秒的吞吐量)topic多个分区leader的,迁移一部分到新broker节点;
9)提交迁移任务时,同一批迁移计划中的分区数据大小偏差应该尽可能小,这样可以避免迁移任务中小分区迁移完成后长时间等待大分区的迁移,造成任务倾斜;
一、kafka 扩容和分区重新分配
我们往已经部署好的Kafka集群里面添加机器是最正常不过的需求,而且添加起来非常地方便,我们需要做的事是从已经部署好的Kafka节点中复制相应的配置文件,然后把里面的broker id修改成全局唯一的,最后启动这个节点即可将它加入到现有Kafka集群中。
但是问题来了,新添加的Kafka节点并不会自动地分配数据,所以无法分担集群的负载,除非我们新建一个topic。但是现在我们想手动将部分分区移到新添加的Kafka节点上,Kafka内部提供了相关的工具来重新分布某个topic的分区。
找到Top主题
1. 如果系统内部有通过Broker暴露的的Jmx接口采集Topic入流量指标,那么对这些流量做一个排序,可以快速的找到目标主题。
2. 也可以写一个shell脚本,使用cmdline-jmxclient.jar工具实时的取到所有topic的流量,然后再做排序。这个方法比较繁琐,仍需考虑Topic的分区是否分布在不同的Broker上,是否需要做汇总等。
3. 如果不想用2的办法,有一个简单的办法可以大概看出流量的分布。先进入broker上的数据目录,然后查看每个分区的堆积的数据量大小。比如执行如下命令:ll -h /data/kafka_data/。根据堆积的情况来判断哪些Topic的流量相对较大。
当然,如果集群中所有主题的流量都非常平均,那就对所有的Topic一起处理。接下来我们来讨论下当遇到紧急扩容的需求时,有哪些方案可以选择。
根据二八法则和现网运营来看,在大多数集群中,头部效应一般都比较明显,即大部分压力都是由少量Topic带来的。所以一般只要解决导致问题的头部主题,就会事半功倍的解决问题。给大家看一下典型的现网集群的Topic流量排行示意图,集群的流量集中在下面的Top主题中:
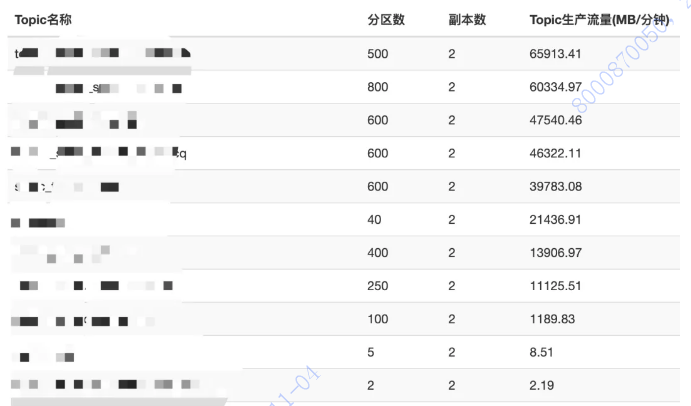
另外,kafka-reassign-partitions.sh 分区迁移工具支持分区粒度的迁移,也可以支持整个Topic的迁移。所以在进行集群扩容的时候,不需要迁移所有的Topic。可以迁移某几个Topic或者某几个Topic中的某些分区。这样尽量减少需要搬迁的数据量。
一、broker间数据迁移:数据迁移的官方说法是分区重分配:kafka-reassign-partitions.sh
官方提供了kafka-reassign-partitions.sh脚本来执行分区重分配操作。
其底层实现主要有如下三步:
- 通过副本复制的机制将老节点上的分区搬迁到新的节点上。
- 然后再将Leader切换到新的节点。
- 最后删除老节点上的分区。
-
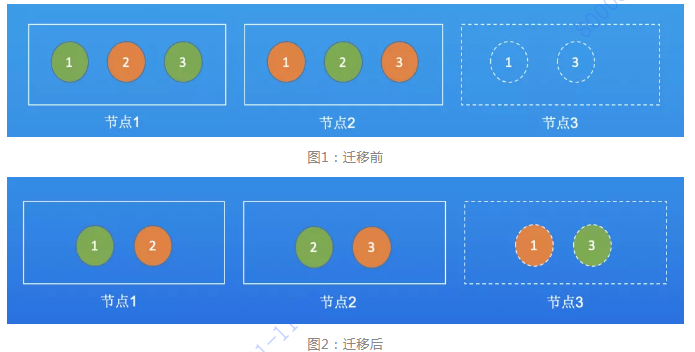
假设topicA有3个分区,2个副本,分区和副本分布在节点1和节点2。此时加了一个节点3,如果要让3个节点均分压力,就需要从节点1,2中迁移两个分区到节点3,如下所示:
在重新分布topic分区之前,我们先来看看现在topic的各个分区的分布位置:
|
|
从上面的输出可以看出,iteblog主题一共有7个分区,但是我们broker的个数只有4个,所以会导致某些broker维护更多的分区。现在我们在现有集群的基础上再添加一个Kafka节点,然后使用Kafka自带的kafka-reassign-partitions.sh工具来重新分布分区。该工具有三种使用模式:
1、generate模式,给定需要重新分配的Topic,自动生成reassign plan(并不执行)
2、execute模式,根据指定的reassign plan重新分配Partition
3、verify模式,验证重新分配Partition是否成功
- --generate 生成分区重分配计划
- --execute 执行分区重分配计划
- --verify 验证分区充重配计划
现在我们需要将原先分布在broker 1-4节点上的分区重新分布到broker 1-5节点上,借助kafka-reassign-partitions.sh工具生成reassign plan,不过我们先得按照要求定义一个文件,里面说明哪些topic需要重新分区,文件内容如下:
[iteblog@www.iteblog.com ~]$ cat topics-to-move.json
{"topics": [{"topic": "iteblog"}],
"version":1
}1、生成分区重分配计划
然后使用kafka-reassign-partitions.sh 工具生成reassign plan
[iteblog@www.iteblog.com ~]$ bin/kafka-reassign-partitions.sh
--zookeeper www.iteblog.com:2181
--topics-to-move-json-file topics-to-move.json
--broker-list "1,2,3,4,5" #broker-list partition重分配broker范围
--generate
Current partition replica assignment
{
"version": 1,
"partitions": [{
"topic": "iteblog",
"partition": 3,
"replicas": [4, 1]
}, {
"topic": "iteblog",
"partition": 5,
"replicas": [2, 4]
}, {
"topic": "iteblog",
"partition": 4,
"replicas": [1, 3]
}, {
"topic": "iteblog",
"partition": 0,
"replicas": [1, 2]
}, {
"topic": "iteblog",
"partition": 6,
"replicas": [3, 1]
}, {
"topic": "iteblog",
"partition": 1,
"replicas": [2, 3]
}, {
"topic": "iteblog",
"partition": 2,
"replicas": [3, 4]
}]
}
Proposed partition reassignment configuration
{
"version": 1,
"partitions": [{
"topic": "iteblog",
"partition": 3,
"replicas": [3, 5]
}, {
"topic": "iteblog",
"partition": 5,
"replicas": [5, 3]
}, {
"topic": "iteblog",
"partition": 4,
"replicas": [4, 1]
}, {
"topic": "iteblog",
"partition": 0,
"replicas": [5, 2]
}, {
"topic": "iteblog",
"partition": 6,
"replicas": [1, 4]
}, {
"topic": "iteblog",
"partition": 1,
"replicas": [1, 3]
}, {
"topic": "iteblog",
"partition": 2,
"replicas": [2, 4]
}]
}2、执行分区重分配计划
--reassignment-json-file 指定JSON格式配置文件,第一步生成的重分配计划
Proposed partition reassignment configuration下面生成的就是将分区重新分布到broker 1-5上的结果。我们将这些内容保存到名为 result.json 文件里面(文件名不重要,文件格式也不一定要以json为结尾,只要保证内容是json即可),然后执行这些reassign plan:
[iteblog@www.iteblog.com ~]$ bin/kafka-reassign-partitions.sh
--zookeeper www.iteblog.com:2181
--reassignment-json-file result.json
--execute
Current partition replica assignment
{
"version": 1,
"partitions": [{
"topic": "iteblog",
"partition": 3,
"replicas": [4, 1]
}, {
"topic": "iteblog",
"partition": 5,
"replicas": [2, 4]
}, {
"topic": "iteblog",
"partition": 4,
"replicas": [1, 3]
}, {
"topic": "iteblog",
"partition": 0,
"replicas": [1, 2]
}, {
"topic": "iteblog",
"partition": 6,
"replicas": [3, 1]
}, {
"topic": "iteblog",
"partition": 1,
"replicas": [2, 3]
}, {
"topic": "iteblog",
"partition": 2,
"replicas": [3, 4]
}]
}
Save this to use as the--reassignment - json - file option during rollback
Successfully started reassignment of partitions {
"version": 1,
"partitions": [{
"topic": "iteblog",
"partition": 1,
"replicas": [1, 3]
}, {
"topic": "iteblog",
"partition": 5,
"replicas": [5, 3]
}, {
"topic": "iteblog",
"partition": 4,
"replicas": [4, 1]
}, {
"topic": "iteblog",
"partition": 6,
"replicas": [1, 4]
}, {
"topic": "iteblog",
"partition": 2,
"replicas": [2, 4]
}, {
"topic": "iteblog",
"partition": 0,
"replicas": [5, 2]
}, {
"topic": "iteblog",
"partition": 3,
"replicas": [3, 5]
}]
}3、验证分区重分配计划
这样Kafka就在执行reassign plan,我们可以校验reassign plan是否执行完成:
[iteblog@www.iteblog.com ~]$ bin/kafka-reassign-partitions.sh \
--zookeeper www.iteblog.com:2181
--reassignment-json-file result.json
--verify
Status of partition reassignment:
Reassignment of partition [iteblog,1] completed successfully
Reassignment of partition [iteblog,5] is still in progress
Reassignment of partition [iteblog,4] completed successfully
Reassignment of partition [iteblog,6] completed successfully
Reassignment of partition [iteblog,2] completed successfully
Reassignment of partition [iteblog,0] is still in progress
Reassignment of partition [iteblog,3] completed successfully可以看出,分区正在Reassignment的状态是still in progress;如果分区Reassignment完成则completed successfully,然后我们就可以看到分区已经按照生成的reassign plan进行,我们可以看下topic各个分区现在的分布情况:
[iteblog@www.iteblog.com ~]$ ./bin/kafka-topics.sh
--topic iteblog
--describe
--zookeeper www.iteblog.com:2181
Topic:iteblog PartitionCount:7 ReplicationFactor:2 Configs:
Topic: iteblog Partition: 0 Leader: 5 Replicas: 5,2 Isr: 2,5
Topic: iteblog Partition: 1 Leader: 1 Replicas: 1,3 Isr: 3,1
Topic: iteblog Partition: 2 Leader: 2 Replicas: 2,4 Isr: 4,2
Topic: iteblog Partition: 3 Leader: 3 Replicas: 3,5 Isr: 3,5
Topic: iteblog Partition: 4 Leader: 1 Replicas: 4,1 Isr: 1,4
Topic: iteblog Partition: 5 Leader: 5 Replicas: 5,3 Isr: 3,5
Topic: iteblog Partition: 6 Leader: 1 Replicas: 1,4 Isr: 1,4
分区的分布的确和操作之前不一样了,broker 5上已经有分区分布上去了。但是仔细的同学应该可以发现,broker 4上居然没有分区的Leader,这肯定不是我们想要的!所以使用kafka-reassign-partitions.sh工具生成的reassign plan只是一个建议,方便大家而已。其实我们自己完全可以编辑一个reassign plan,然后执行它,如下:
{
"version": 1,
"partitions": [{
"topic": "iteblog",
"partition": 0,
"replicas": [1, 2]
}, {
"topic": "iteblog",
"partition": 1,
"replicas": [2, 3]
}, {
"topic": "iteblog",
"partition": 2,
"replicas": [3, 4]
}, {
"topic": "iteblog",
"partition": 3,
"replicas": [4, 5]
}, {
"topic": "iteblog",
"partition": 4,
"replicas": [5, 1]
}, {
"topic": "iteblog",
"partition": 5,
"replicas": [1, 3]
}, {
"topic": "iteblog",
"partition": 6,
"replicas": [2, 4]
} ]
}将上面的json数据文件保存到result.json文件中,然后也是执行它:
[iteblog@www.iteblog.com ~]$ bin/kafka-reassign-partitions.sh
--zookeeper www.iteblog.com:2181
--reassignment-json-file result.json
--execute
等这个reassign plan执行完,我们再来看看分区的分布:
[iteblog@www.iteblog.com ~]$ ./bin/kafka-topics.sh --topic iteblog --describe --zookeeper www.iteblog.com:2181
Topic:iteblog PartitionCount:7 ReplicationFactor:2 Configs:
Topic: iteblog Partition: 0 Leader: 1 Replicas: 1,2 Isr: 2,1
Topic: iteblog Partition: 1 Leader: 2 Replicas: 2,3 Isr: 3,2
Topic: iteblog Partition: 2 Leader: 3 Replicas: 3,4 Isr: 4,3
Topic: iteblog Partition: 3 Leader: 4 Replicas: 4,5 Isr: 5,4
Topic: iteblog Partition: 4 Leader: 5 Replicas: 5,1 Isr: 1,5
Topic: iteblog Partition: 5 Leader: 1 Replicas: 1,3 Isr: 3,1
Topic: iteblog Partition: 6 Leader: 2 Replicas: 2,4 Isr: 4,2
果然已经按照我们需求分布了。。
1、确定要重启分配分区的主题,新建topics-to-move.json json文件
{
"topics": [
{"topic": "foo1"},
{"topic": "foo2"}
],
"version":1
}
// foo1 foo2 为要重新分配的主题2、使用 bin/kafka-reassign-partitions.sh重新分配工具生成分配规则的json语句分配到 5,6机器
bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 \
--topics-to-move-json-file topics-to-move.json --broker-list "5,6" –generate3、有分配规则的json语句输出到控制台,复制到新建的json文件expand-cluster-reassignment.json中,例如:
{"version":1,
"partitions":[{"topic":"foo1","partition":0,"replicas":[5,6]},
{"topic":"foo1","partition":1,"replicas":[5,6]},
{"topic":"foo1","partition":2,"replicas":[5,6]},
{"topic":"foo2","partition":0,"replicas":[5,6]},
{"topic":"foo2","partition":1,"replicas":[5,6]},
{"topic":"foo2","partition":2,"replicas":[5,6]}]
}
//描述分配之后分区的分布情况4、执行命令,开始分区重新分配
bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 \
--reassignment-json-file expand-cluster-reassignment.json –execute
5、验证是否完成
bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 \
--reassignment-json-file expand-cluster-reassignment.json –verify
//当输出全部都是completed successfully表明移动已经完成.操作中三个小技巧:
1、可以不需要第一步和第二步,自己手动新建分配的json文件。
2、主题量很多的是就不要一个一个复制粘贴了,用excel的拼接函数,还是很方便
3、最后一步验证中,主题很多的时候,会有很多在为未完成的输出语句夹杂其中。在语句后面加上 | grep -c "progress"就知道有多少分区还没完成,输出为0的时候就是完成了。
总结和知识点理解
1、kafka新建主题时的分区分配策略:随机选取第一个分区节点,然后往后依次增加。例如第一个分区选取为1,第二个分区就是2,第三个分区就是3. 1,2,3是brokerid。不会负载均衡,所以要手动重新分配分区操作,尽量均衡。
2、在生产的同时进行数据迁移会出现重复数据。所以迁移的时候避免重复生产数据,应该停止迁移主题的生产。同时消费不会,同时消费之后出现短暂的leader报错,会自动恢复。
3、新增了broker节点,如果有主题的分区在新增加的节点上,生产和消费的客户端都应该在hosts配置文件中增加新增的broker节点,否则无法生产消费,但是也不报错。
一、SparkStreaming自适应上游kafka topic partition数目变化
问题背景
Spark Streaming 程序中使用 Kafka 的最原始方式为 KafkaUtils.createDirectStream 通过源码,我们找到调用链条大致是这样的
KafkaUtils.createDirectStream -> new DirectKafkaInputDStream -> 最终由 DirectKafkaInputDStream#compute(validTime : Time) 函数来生成 KafkaRDD。
而 KafkaRDD 的 partition 数和 作业开始运行时 topic 的 partition 数一致,topic 的 partition 数保存在 currentOffsets 变量中,currentOffsets 是一个 Map[TopicAndPartition, Long]类型的变量,保存每个 partition 当前消费的 offset 值,但是作业运行过程中 currentOffsets 不会增加 key,就是是不会增加 partition,这样导致每次生成 KafkaRDD 的时候都使用 开始运行作业时 topic 的 partition 数作为 KafkaRDD 的 partition 数,从而会造成数据的丢失。
Spark Streaming 作业在运行过程中,上游 topic 增加 partition 数目从 A 增加到 B,会造成作业丢失数据,因为该作业只从 topic 中读取了原来的 A 个 partition 的数据,新增的 B-A 个 partition 的数据会被忽略掉。
思考过程
为了作业能够长时间的运行,一开始遇到这种情况的时候,想到两种方案:
- 方案 1:感知上游 topic 的 partition 数目变化,然后发送报警,让用户重启
- 方案 2 :直接在作业内部自适应上游 topic partition 的变化,完全不影响作业
- 方案 1 是简单直接,第一反应的结果,但是效果不好,需要用户人工介入,而且可能需要删除 checkpoint 文件。
- 方案 2 从根本上解决问题,用户不需要关心上游 partition 数目的变化,但是第一眼会觉得较难实现。方案 1 很快被 pass 掉,因为人工介入的成本太高,而且实现起来很别扭。接下来考虑方案 2.
解决方案
我们只需要在每次生成 KafkaRDD 的时候,将 currentOffsets 修正为正常的值(往里面增加对应的 partition 数,总共 B-A 个,以及每个增加的 partition 的当前 offset 从零开始)。
第一个问题出现了,我们不能修改 Spark 的源代码,重新进行编译,因为这不是我们自己维护的。想到的一种方案是继承 DirectKafkaInputDStream。我们发现不能继承 DirectKafkaInputDStream 该类,因为这个类是使用 private[streaming] 修饰的。
第二个问题出现了,怎么才能够继承 DirectKafkaInputDStream,这时我们只需要将希望继承 DirectKafkaInputDStream 的类放到一个单独的文件 F 中,文件 F 使用 package org.apache.spark.streaming 进行修饰即可,这样可以绕过不能继承 DirectKafkaInputDStream 的问题。这个问题解决后,我们还需要修改 Object KafkaUtils ,让该 Object 内部调用我们修改后的 DirectKafkaInputDStream(我命名为 MTDirectKafkaInputDStream)
第三个问题如何让 Spark 调用 HTDirectKafkaInputDStream,而不是 DirectKafkaInputDStream,这里我们使用简单粗暴的方式,将 KafkaUtils 的代码 copy 一份,然后将其中调用 DirectKafkaInputDStream 的部分都修改为 HTDirectKafkaInputDStream,这样就实现了我们的需要。当然该文件也需要使用 package org.apache.spark.streaming 进行修饰
总结下,我们需要做两件事
1、修改 DirectKafkaInputDStream#compute 使得能够自适应 topic 的 partition 变更
2、修改 KafkaUtils,使得我们能够调用修改过后的 DirectKafkaInputDStream
预置条件
compile (group: 'org.apache.spark', name: 'spark-core_2.10', version:'2.1.0')
compile (group: 'org.apache.spark', name: 'spark-streaming-kafka_2.10', version:'1.6.3'
代码
package org.apache.spark.streaming.kafka
class HTDirectKafkaInputDStream[
K: ClassTag,
V: ClassTag,
U <: Decoder[K]: ClassTag,
T <: Decoder[V]: ClassTag,
R: ClassTag](
@transient ssc_ : StreamingContext,
val HTkafkaParams: Map[String, String],
val HTfromOffsets: Map[TopicAndPartition, Long],
messageHandler: MessageAndMetadata[K, V] => R
) extends DirectKafkaInputDStream[K, V, U, T, R](ssc_, HTkafkaParams , HTfromOffsets, messageHandler) {
@transient private val logger = Logger.getLogger("HTDirectKafkaInputDStream")
logger.setLevel(Level.INFO)
private val kafkaBrokerList:String = HTkafkaParams.get("metadata.broker.list").get
override def compute(validTime: Time) : Option[KafkaRDD[K, V, U, T, R]] = {
/**
* 在这更新 currentOffsets 从而做到自适应上游 partition 数目变化
*/
updateCurrentOffsetForKafkaPartitionChange()
super.compute(validTime)
}
val topic:Set[String] = Set()
HTfromOffsets.keys.foreach(x=>{
topic += x.topic
})
private def updateCurrentOffsetForKafkaPartitionChange() : Unit = {
val parts = kc.getPartitions(topic.toSet).right.get
val newPartitions = parts.diff(currentOffsets.keySet)
if(!newPartitions.isEmpty) {
logger.info(s"Old partition number:${currentOffsets.keys.size}, and now is: ${parts.size} ,updating currentOffsets...")
currentOffsets = currentOffsets ++ newPartitions.map(tp => tp -> 0l).toMap
}
}
}在修改过后的 KafkaUtils 文件中,将所有的 DirectKafkaInputDStream 都替换为 HTDirectKafkaInputDStream 即可
问题

项目Spark版本为2.0.0版本,然而在spark 1.5.2版本之后 org/apache/spark/Logging 已经被移除了(被移到org/apache/spark/internal/Logging)。
由于spark-streaming-kafka 1.6.3版本中使用到了logging,所以会有找不到这个类的问题。
解决方法:copy spark-core包中org/apache/spark/internal/Logging修改类的修饰为package org.apache.spark
附:kafka Producer感知broker topic分区变化由topic.metadata.refresh.interval.ms参数决定的,默认10min
Spark Streaming 与 kafka 0.8 版本结合
override def compute(validTime: Time): Option[KafkaRDD[K, V, U, T, R]] = { // 改行代码会计算这个job,要消费的每个kafka分区的最大偏移
val untilOffsets = clamp(latestLeaderOffsets(maxRetries)) // 构建KafkaRDD,用指定的分区数和要消费的offset范围
val rdd = KafkaRDD[K, V, U, T, R](context.sparkContext,
kafkaParams, currentOffsets, untilOffsets,
messageHandler) // Report the record number and metadata of this batch interval to InputInfoTracker.
val offsetRanges = currentOffsets.map
{
case(tp, fo) => val uo = untilOffsets(tp) OffsetRange(
tp.topic, tp.partition, fo, uo.offset)
}
val description = offsetRanges.filter
{
offsetRange =>
// Don't display empty ranges.
offsetRange.fromOffset != offsetRange.untilOffset
}.map
{
offsetRange => s "topic: ${offsetRange.topic}\tpartition: ${offsetRange.partition}\t" +
s "offsets: ${offsetRange.fromOffset} to ${offsetRange.untilOffset}"
}.mkString("\n") // Copy offsetRanges to immutable.List to prevent from being modified by the user
val metadata = Map("offsets" - > offsetRanges.toList,
StreamInputInfo.METADATA_KEY_DESCRIPTION - >
description) val inputInfo = StreamInputInfo(id, rdd.count,
metadata)
ssc.scheduler.inputInfoTracker.reportInfo(validTime,
inputInfo)
currentOffsets = untilOffsets.map(kv => kv._1 - > kv._2.offset) Some(
rdd)
}中间没有检测 kafka 新增 topic 或者分区的代码,所以可以确认 Spark Streaming 与 kafka 0.8 的版本结合不支持动态分区检测。
Spark Streaming 与 kafka 0.10 版本结合
入口同样是 DirectKafkaInputDStream 的 compute 方法,捡主要的部分说,Compute 里第一行也是计算当前 job 生成 kafkardd 要消费的每个分区的最大 offset:
// 获取当前生成job,要用到的KafkaRDD每个分区最大消费偏移值
val untilOffsets = clamp(latestOffsets())
具体检测 kafka 新增 topic 或者分区的代码在 latestOffsets()
/**
* Returns the latest (highest) available offsets, taking new partitions into account. */
protected def latestOffsets(): Map[TopicPartition, Long] = {
val c = consumer
paranoidPoll(c) // 获取所有的分区信息
val parts = c.assignment().asScala // make sure new partitions are reflected in currentOffsets
// 做差获取新增的分区信息
val newPartitions = parts.diff(currentOffsets.keySet) // position for new partitions determined by auto.offset.reset if no commit
// 新分区消费位置,没有记录的化是由auto.offset.reset决定
currentOffsets = currentOffsets++
newPartitions.map(tp => tp - > c.position(tp)).toMap // don't want to consume messages, so pause
c.pause(newPartitions.asJava) // find latest available offsets
c.seekToEnd(currentOffsets.keySet.asJava)
parts.map(tp => tp - > c.position(tp)).toMap
}该方法内有获取 kafka 新增分区,并将其更新到 currentOffsets 的过程,所以可以验证 Spark Streaming 与 kafka 0.10 版本结合支持动态分区检测。















 836
836











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











