







1.Elasticsearch基本概念
(1)Cluster:代表一个集群,集群中有多个节点,其中有一个为主节点,这个主节点是可以通过选举产生的,主从节点是对于集群内部来说的。es的一个概念就是去中心化,字面上理解就是无中心节点,这是对于集群外部来说的,因为从外部来看es集群,在逻辑上是个整体,你与任何一个节点的通信和与整个es集群通信是等价的。
(2)shards:代表索引分片,es可以把一个完整的索引分成多个分片,这样的好处是可以把一个大的索引拆分成多个,分布到不同的节点上。构成分布式搜索。分片的数量只能在索引创建前指定,并且索引创建后不能更改。
(3)replicas:代表索引副本,es可以设置多个索引的副本,副本的作用一是提高系统的容错性,当某个节点某个分片损坏或丢失时可以从副本中恢复。二是提高es的查询效率,es会自动对搜索请求进行负载均衡。
(4)recovery:代表数据恢复或叫数据重新分布,es在有节点加入或退出时会根据机器的负载对索引分片进行重新分配,挂掉的节点重新启动时也会进行数据恢复。
(5)river:代表es的一个数据源,也是其它存储方式(如:数据库)同步数据到es的一个方法。它是以插件方式存在的一个es服务,通过读取river中的数据并把它索引到es中,官方的river有couchDB的,RabbitMQ的,Twitter的,Wikipedia的。
(6)gateway:代表es索引快照的存储方式,es默认是先把索引存放到内存中,当内存满了时再持久化到本地硬盘。gateway对索引快照进行存储,当这个es集群关闭再重新启动时就会从gateway中读取索引备份数据。es支持多种类型的gateway,有本地文件系统(默认),分布式文件系统,Hadoop的HDFS和amazon的s3云存储服务。
(7)discovery.zen:代表es的自动发现节点机制,es是一个基于p2p的系统,它先通过广播寻找存在的节点,再通过多播协议来进行节点之间的通信,同时也支持点对点的交互。
(8)Transport:代表es内部节点或集群与客户端的交互方式,默认内部是使用tcp协议进行交互,同时它支持http协议(json格式)、thrift、servlet、memcached、zeroMQ等的传输协议(通过插方式)
2.部署Elasticsearch集群
2.1.安装JDK
Elasticsearch是基于Java开发是一个Java程序,运行在Jvm中,所以第一步要安装JDK
yum install -y java-1.8.0-openjdk-devel
2.2.下载elasticsearch
https://artifacts.elastic.co/downloads/elasticsearch/ 是ELasticsearch的官方站点,如果需要下载最新的版本,进入官网下载即可。也可以直接在命令行中下载。
如果环境中没有wget可以用:
yum -y install wget
然后直接使用下面命令:
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.4.2.rpm
该文件在/root/目录下(对于集群环境最好每个节点都放elasticsearch的安装包):
2.3 命令行安装
cd /root/
rpm -i elasticsearch-6.4.2.rpm 会出现下面界面:

根据上图的安装提示:依次执行下面三条命令
sudo systemctl daemon-reload
sudo systemctl enable elasticsearch.service

启动elasticsearch 服务
sudo systemctl start elasticsearch.service
查看服务状态会出现下面报错:

配置java路径(根据自己的集群查找,可以使用vim /etc/profile 查看java的安装路径):
vim /etc/sysconfig/elasticsearch

集群环境的配置:
cd /etc/elasticsearch/
vim elasticsearch.yml
192.168.5.184:配置:
cluster.name: gouuse-application
node.name: node-184
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 0.0.0.0
discovery.zen.ping.unicast.hosts: ["192.168.5.184","192.168.5.185","192.168.5.186","192.168.5.187","192.168.5.188"]
http.cors.enabled: true
http.cors.allow-origin: "*"
同理192.168.5.185-192.168.5.188的配置和只需要修改node.name 其它保持不变。
systemctl restart elasticsearch.service(每个节点都要启动)
systemctl status elasticsearch.service
在谷歌服务器输入:192.168.5.184:9200,出现以下界面则配置成功(其它节点同理):

查看集群状态:
curl -XGET 'http://192.168.5.184:9200/_cluster/health?pretty'

{
"cluster_name" : "gouuse-application", //集群的名称
"status" : "green", //集群的状态红绿黄,绿:健康,黄:亚健康,红:病态
"timed_out" : false,
"number_of_nodes" : 5, //节点数
"number_of_data_nodes" : 5, //数据节点数
"active_primary_shards" : 13, //分片数
"active_shards" : 26,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 0,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 100.0
}
集群状态为green,说明集群状态良好.
3.Elasticsearch 与hive的集成
3.1环境搭建
http://jcenter.bintray.com/org/elasticsearch/elasticsearch-hadoop/ 下载elasticsearch-hadoop 对应的jar包,注意elasticsearch是什么版本就下载对应的版本的elasticsearch-hadoop(此安装elasticsearch 版本为6.4.2版本,因此下载elasticsearch-hadoop-6.4.2.jar),将下载的jar包传到Lunix系统上(位置自行确定)(user/gouuse/jars/elasticsearch-hadoop-6.4.2.jar)。
3.2数据插入(简单的举例)
(1)建立view 表
首先要加载elasticsearch-hadoop6.4.2.jar,在hive-shell里面执行
add jar hdfs:///user/gouuse/jars/elasticsearch-hadoop-6.4.2.jar;
CREATE EXTERNAL TABLE user
(id INT, name STRING)
STORED BY
'org.elasticsearch.hadoop.hive.EsStorageHandler'
TBLPROPERTIES
('es.resource' = 'radiott/artiststt', //表示索引/类型,可以理解为关系型数据库的 数据库/表
'es.index.auto.create' = 'true',
'es.nodes' = 'elastisticsearch.*.qunar.com',//配置es的url地址,可以设置多个
'es.port' = '9200'); //端口号
(2)建立数据表
CREATE TABLE user_source
(id INT,
name STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
(3)加载基础数据
数据示例,我放在/tmp/user_source.log
1,medcl
2,lcdem
3,tom
4,jack
加载数据到user_sourceb表中
LOAD DATA LOCAL INPATH '/tmp/user_source.log' OVERWRITE INTO TABLE user_source;
(4)加载到es
INSERT OVERWRITE TABLE user SELECT s.id, s.name FROM user_source s;
4.ES6.0版本安装head插件(windows 环境下安装)
安装教程转自:https://www.cnblogs.com/tanshaoxiaoji/p/elasticsearch_head_install.html
下载地址:https://github.com/mobz/elasticsearch-head;点击clone or download按钮,点击download zip进行下载。下载完毕后解压到任意路径上,别放在elasticsearch安装路径上。

4.1安装node.js
这个比较容易,下载后除路径自己填写外,其他直接next就OK了。下载地址https://nodejs.org/en/download/ 安装在具体的目录下:

3.2 安装grunt
运行head需要借助grunt命令,因此需要安装grunt,Windows+R,输入cmd,输入命令 cd D:\nodejs(安装nodejs的路径) 进入nodejs的根目录下,(注意:如果这条命令不能成功执行,那就先执行 D:,成功切换目录后再执行 cd D:\nodejs(安装nodejs的路径)。),然后执行指令 npm install -g grunt -cli 进行安装grunt。

3.3 安装pathomjs
输入命令 cd D:\head(你安装head的路径) 进入head的根目录下,然后执行命令:npm install 进行安装pathomjs(安装时间较长,可以吃几把鸡先,你应该吃不到...)。如果出现Error关键字,则有可能是网络不顺畅,下载失败,那就继续下一段文字。如果成功(我用公司网络试了三次都不行,祝你好运!),则跳过下一段文字。
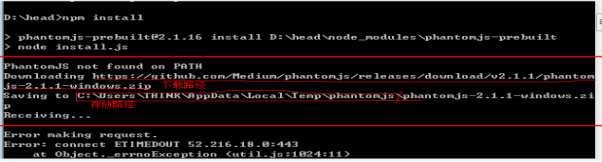
安装失败话,看上面的图片,安装失败时他会显示下载路径和存放路径。请你耐心点,你需要做的是,将相关信息复制下来,手动下载压缩包并放置在存放路径下,命令窗口再次执行安装命令npm install ,他们会去存放路径下检索文件并解压安装,只要提示文字没出现Error,则安装成功。(如果复制不到,可以这样试试,鼠标右键点击全选,然后在目标文本附近点击一下,然后拖动鼠标选上文本,按Ctrl+C,不要怀疑自己,试试在txt文本按Ctrl+V试试,是不是复制下来了?

3.4 运行head
最后,什么都别关,还没结束呢,在刚刚的命令窗口执行运行命令grunt server,启动head服务,如下所示则为启动成功。(可以到head根目录下修改Gruntfile.js文件的启动端口,默认是9100)

然后去修改elasticsearch的配置文件,elasticsearch安装目录etc/elasticsearch/elasticsearch.yml(根据自己的位置),打开文件后在末端另起一行分别顶格添加如下两行红色字体文本(之前配置集群时已经添加了该命令),保存后重启elasticsearch.
http.cors.enabled: true
http.cors.allow-origin: "*"
3.5 用head访问elasticsearch
浏览器访问 http://localhost:9100(head的服务端口),访问成功后,出现如下界面:

刚才表的信息就可以查看:















 1282
1282











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









