







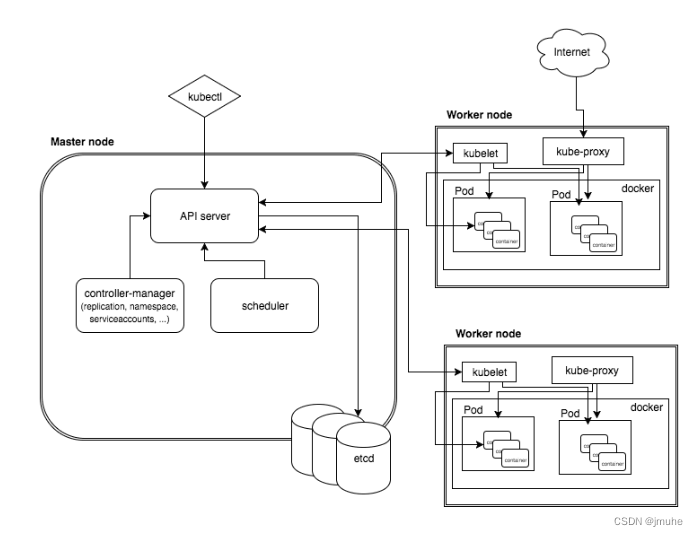
k8s集群主要包括控制平面和工作节点两个部分,控制平面控制并使得整个集群正常运转;工作节点运行pod并上报pod的状态。
1. 控制平面-etcd
etcd是k8s集群的分布式持久化存储,只和API服务器交互,控制平面的其他组件,以及kublet都不会和etcd直接交互,而是通过API服务器和etcd进行交互。这样的好处包括:
- 可以增强乐观锁系统、验证系统的健壮性。
- 可以把实际存储机制从其他组件抽离出来,方便未来对存储系统的替换
2. 控制平面-API服务器
它以RESTful API的形式提供了可以查询、修改集群状态的CRUD接口,将结果保存到etcd中。
一个请求到达API服务器后,会经历以下几个过程
- 通过认证插件认证客户端。主要是用于确定是谁发的请求。根据认证方式,用户信息可以从客户端证书或者从HTTP标头获取。插件抽取客户端的用户名、用户ID和归属组。
- 授权插件授权客户端。主要用于决定用户是否可以对请求的资源执行操作
- 通过准入控制插件验证和修改请求。AlwaysPullImages插件会重写imagePullPolicy为always;ServiceAccount会为未明确定义服务账户的使用默认账户。
API服务器也提供通知机制,用于通知资源的变更到订阅者。调度器,控制器和kublet都是通过通知机制感知资源的变更,并做相应的工作,通过通知机制,各组件很好的进行了解耦。
3. 控制平面-调度器
调度器不会让具体某个kublet运行pod。调度器做的就是通过API服务器更新pod的定义,将节点信息写入pod的manifest,然后API服务器会通知kublet。当目标节点上的kubelet发现pod被调度到本节点时,就会创建pod并运行。
调度器的工作分为两部分
- 过滤所有节点,列出可用列表。节点是否可用有很多因素决定,比如资源是否满足,pod的节点选择器,污点以及容忍度,亲缘性和非亲缘性规则等
- 为pod选择最佳节点
4. 控制平面-控制器
控制器有很多,包括Replication管理器,ReplicaSet、DaemonSet以及job控制器,Deployment控制器等。
总的来说,控制器执行一个“调和”循环,将实际状态调整为期望状态,将新的实际状态写入资源的status部分。控制器之间不会直接通信,而是通过API服务器的通知机制协调工作,形成一个事件链。
当创建Deployment时,整个事件链包括如下事件:
- 通过kubectl调用API服务器接口创建Deployment
- Deployment控制器监听到Deployment变更,通过API服务器接口创建ReplicaSet
- RelicaSet控制器监听到变更,通过API服务器接口创建pod
- 调度器监听到pod变更,为pod分配节点,并通过API服务器接口更新pod中的节点信息
- kubelet监听到pod已经分配给本节点,将运行容器
5. 工作节点-kublet
kublet是负责所有运行在工作节点上内容的组件。它首先会在API服务器中创建一个Node资源来注册该节点。然后持续监控分配给本节点的pod,通过容器运行时创建容器,并持续监控运行的容器,向API服务器报告它们的状态、事件和资源消耗。
6. 工作节点-kube proxy
kube-proxy用于确保客户端可以通过Kubernetes API连接到定义的服务。kube-proxy确保对服务IP和端口的连结最终能到达支持服务的某个pod。
kube-proxy最初实现为userspace,它会等待连接,对每个进来的连接,连接到一个pod。后来性能更好的iptables代理模式取代了它。
在介绍iptables模式前,需要先说下Service。每个Service有其自己稳定的IP地址和端口,但是IP地址是虚拟的,没有被分配给任何网络接口,所以是无法ping的。
当创建一个Service时,虚拟IP地址会分配给它。之后,API服务器会通知所有运行在工作节点上的kube-proxy有一个新的Service已经被创建。然后,每个kube-proxy都会让该服务在自己运行的节点上可寻址。原理是通过建立一些iptables规则,确保每个目的地为服务的IP/端口对的数据包被解析,目的地址被修改,这样数据包就会被重定向到支持服务的一个pod.
除了监听Service资源,kube-proxy也监听对Endpoint对象的更改。















 8367
8367











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









