







Python爬虫获取html中的文本方法多种多样,这里主要介绍一下string、strings、stripped_strings和get_text用法
string:用来获取目标路径下第一个非标签字符串,得到的是个字符串
strings:用来获取目标路径下所有的子孙非标签字符串,返回的是个生成器
stripped_strings:用来获取目标路径下所有的子孙非标签字符串,会自动去掉空白字符串,返回的是一个生成器
get_text:用来获取目标路径下的子孙字符串,返回的是字符串(包含HTML的格式内容)
text:用来获取目标路径下的子孙非标签字符串,返回的是字符串
这里补充说明一下,如果获取到的是生成器,一般都是把它转换成list,不然你看不出那是什么玩意
接下来举栗子说明。以某中介网站举例,目标是获取各个在售二手单元的信息
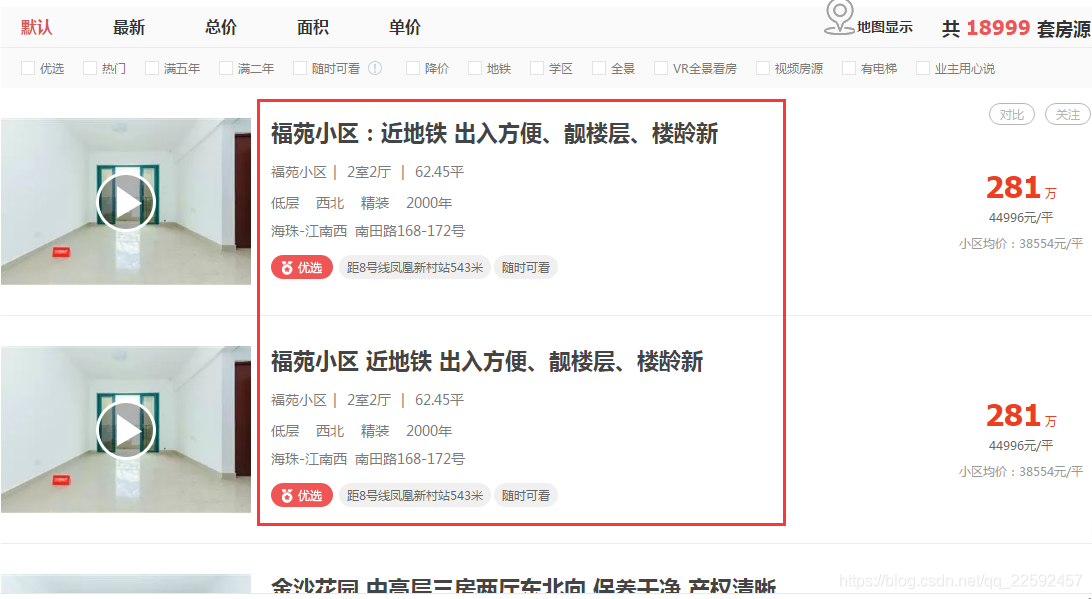
一、string
import requests
from bs4 import BeautifulSoup
url = 'https://gz.centanet.com/ershoufang/'
headers = {'User-Agent':"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36"}
respone = requests.get(url,headers=headers)
soup = BeautifulSoup(respone.text)
ps = soup.select('div[class="section"] div[class="house-item clearfix"] p[class="house-name"]')
for p in ps:
house = p.string
print(house)上面代码执行结果显示的是一堆None,这是因为string只会取第一个值,如下图,第一个值是空,所以最终获取到的是None

二、strings
import requests
from bs4 import BeautifulSoup
url = 'https://gz.centanet.com/ershoufang/'
headers = {'User-Agent':"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36"}
respone = requests.get(url,headers=headers)
soup = BeautifulSoup(respone.text)
ps = soup.select('div[class="section"] div[class="house-item clearfix"] p[class="house-name"]')
for p in ps:
house = list(p.strings)
print(house)如下图,每个list中都会有10个字段,这些字段如何来的参考上图我框红色的地方就知道了。

三、stripped_strings
import requests
from bs4 import BeautifulSoup
url = 'https://gz.centanet.com/ershoufang/'
headers = {'User-Agent':"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36"}
respone = requests.get(url,headers=headers)
soup = BeautifulSoup(respone.text)
houses = []
ps = soup.select('div[class="section"] div[class="house-item clearfix"] p[class="house-name"]')
for p in ps:
house = list(p.stripped_strings)#stripped_strings一下子能取出对应目录下的所有文本,并且自动把空白去掉
houses.append(house)
print(house)
四、get_text
import requests
from bs4 import BeautifulSoup
url = 'https://gz.centanet.com/ershoufang/'
headers = {'User-Agent':"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36"}
respone = requests.get(url,headers=headers)
soup = BeautifulSoup(respone.text)
ps = soup.select('div[class="section"] div[class="house-item clearfix"] p[class="house-name"]')
for p in ps:
house = p.get_text
print(house)
print("=="*40)如下图,红色框选中部分即为一个字符串

五、text
import requests
from bs4 import BeautifulSoup
url = 'https://gz.centanet.com/ershoufang/'
headers = {'User-Agent':"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36"}
respone = requests.get(url,headers=headers)
soup = BeautifulSoup(respone.text)
ps = soup.select('div[class="section"] div[class="house-item clearfix"] p[class="house-name"]')
for p in ps:
house = p.text
print(house)
print("=="*40)
















 1152
1152











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









