








首先介绍一下我的作业要求和Hadoop开发环境:
- 作业目的:实现两表连接。
- 开发环境:IntelliJ IDEA
- JAVA环境:JDK 9
- Hadoop:2.8.1
- 依赖管理工具:Maven
作业描述:将Perons表和Order表根据id连接起来,类似于数据库中的join操作。Persons和Order表结构如下图:
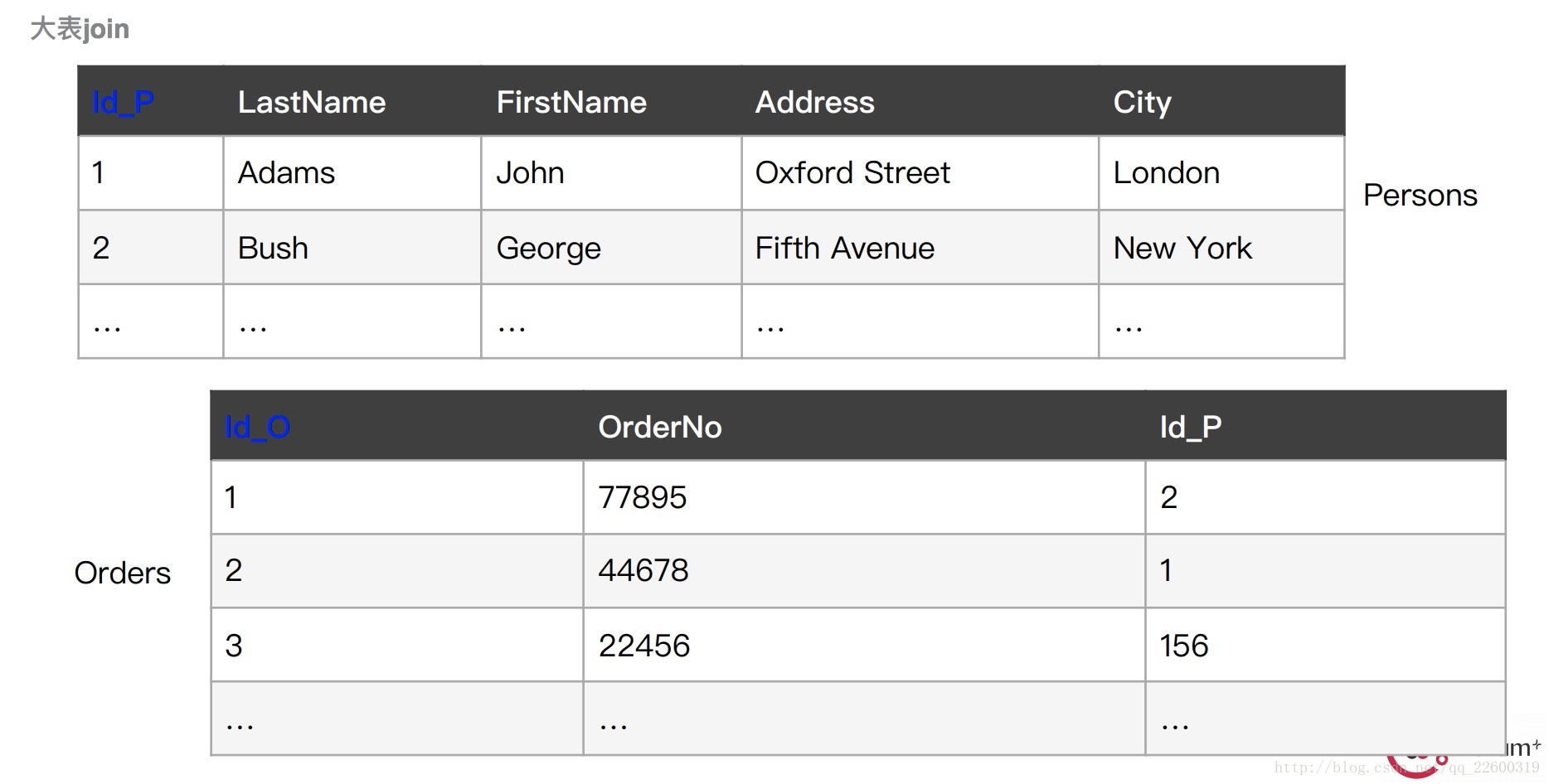
实际操作过程如下图:

代码实现如下:
pom.xml配置如下:
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-core</artifactId>
<version>1.2.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.2</version>
</dependency>
</dependencies>```
JoinTable.java文件如下:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.util.Iterator;
public class JoinTable {
public static class MapTable extends Mapper<Object, Text, Text, Text>{
private Text key = new Text();
private Text value = new Text();
private String[] keyValue = null;
public void map(Object key, Text value, Mapper.Context context) throws IOException, InterruptedException {
String line = value.toString();
keyValue = line.split(",",2);
//以用户id为key
this.key.set(keyValue[0]);
this.value.set(keyValue[1]);
context.write(this.key,this.value);
}
}
public static class ReduceTable extends Reducer<Text, Text, Text, Text> {
private Text value = new Text();
public void reduce(Text key, Iterable<Text> values,
Context context
) throws IOException, InterruptedException {
String valueStr ="";
String[] save = new String[2];
int i=0;
int j=2;
Iterator its =values.iterator();
while(its.hasNext())
{
save[i++] = its.next().toString();
j--;
}
String tableOne = save[0];
String tableTwo = save[1];
char flag = tableOne.charAt(1);
System.out.println("++++" + flag);
if(flag>='A'&&flag<='Z')
{
valueStr += tableOne;
valueStr += " ,";
String[] words = tableTwo.split(",");
tableTwo = words[1] + "," + words[0];
valueStr += tableTwo;
valueStr += " ";
}
else
{
valueStr += tableTwo;
valueStr += " ,";
String[] words = tableOne.split(",");
tableOne = words[1] + "," + words[0];
valueStr += tableOne;
valueStr += " ";
}
this.value.set(valueStr);
context.write(key,this.value);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "Join table");
job.setJarByClass(JoinTable.class);
job.setMapperClass(MapTable.class);
job.setReducerClass(ReduceTable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileInputFormat.addInputPath(job, new Path(args[1]));
FileOutputFormat.setOutputPath(job,new Path(args[2]));
// FileInputFormat.addInputPath(job, new Path("/Users/wangxiaofa/Desktop/Hadoop/src/input/Persons"));
// FileInputFormat.addInputPath(job, new Path("/Users/wangxiaofa/Desktop/Hadoop/src/input/Order"));
// FileOutputFormat.setOutputPath(job, new Path("/Users/wangxiaofa/Desktop/Hadoop/src/output"));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}















 703
703











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









