






 本文详细介绍了客户端无法连接到Kafka集群的各种情况及其解决方案,包括同一机器、跨机器、Docker环境以及docker-compose搭建的场景。核心在于正确配置`advertised.listeners`和`listener.security.protocol.map`,确保客户端能够解析并连接到正确的hostname和端口。
本文详细介绍了客户端无法连接到Kafka集群的各种情况及其解决方案,包括同一机器、跨机器、Docker环境以及docker-compose搭建的场景。核心在于正确配置`advertised.listeners`和`listener.security.protocol.map`,确保客户端能够解析并连接到正确的hostname和端口。
客户端不能连接到kafka集群中主要是advertised.listeners和listener.security.protocol.map没配置好。下面分情景给出正确的配置。
client连接到kafka集群的步骤
-
客户端第一连接到broker上时,broker返回kafka集群的元数据,其中包括各个broker的hostname和端口
-
客户端获取到元数据信息后根据自身需求利用元数据中的主机端口信息连接到对应的broker上
连接的问题的多数是出现在第2步中。下面分情况给出正确配置。
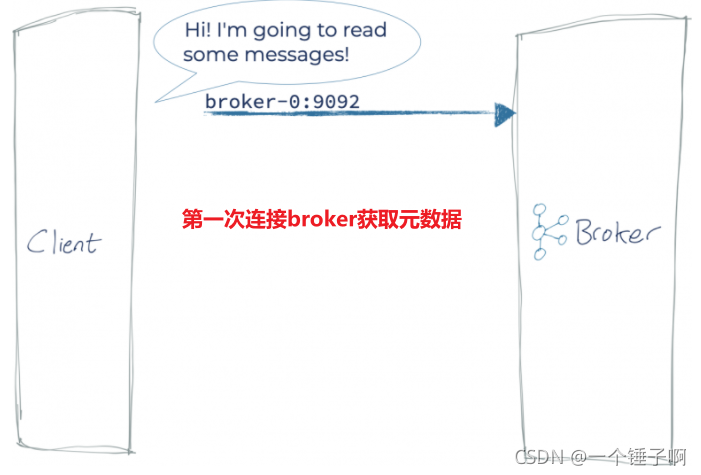
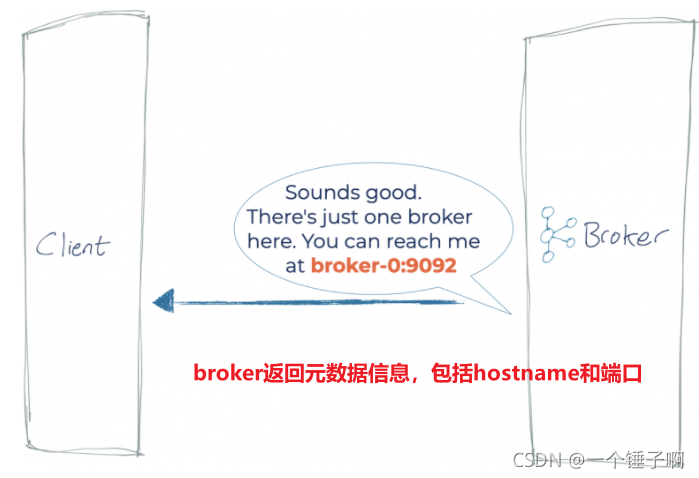
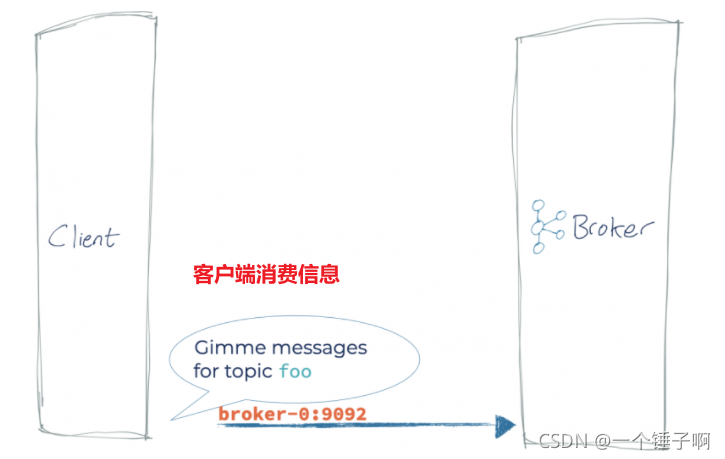
情况1:客户端和kafka运行在同一台机器上
这种情况如下如,运行良好
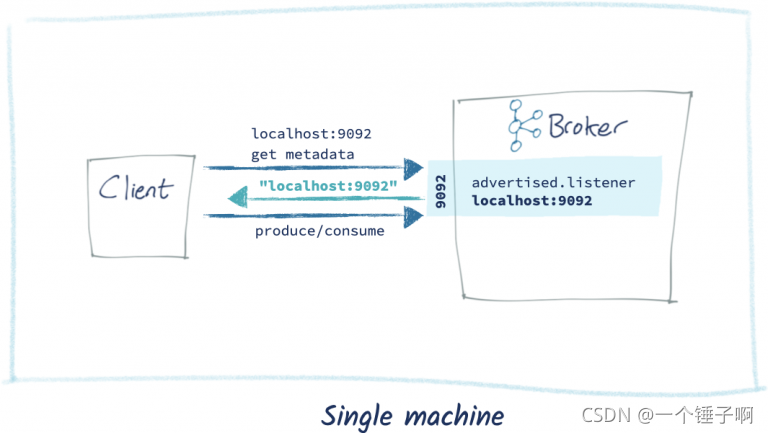
情况2:客户端和kafka在不同机器上
这种情况的连接timeout往往是应为第二步中返回的hostname在客户端机器上不能解析导致的
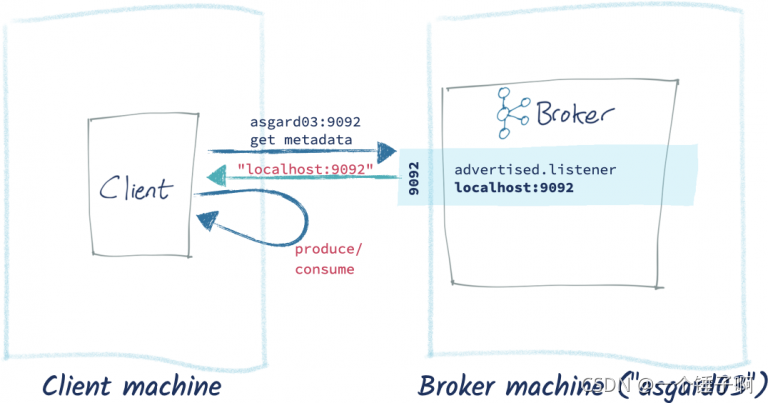
解决方法是修改broker上的server.properties配置
旧配置:
advertised.listeners=PLAINTEXT://localhost:9092
listeners=PLAINTEXT://0.0.0.0:9092
正确配置:
advertised.listeners=PLAINTEXT://asgard03.moffatt.me:9092
listeners=PLAINTEXT://0.0.0.0:9092
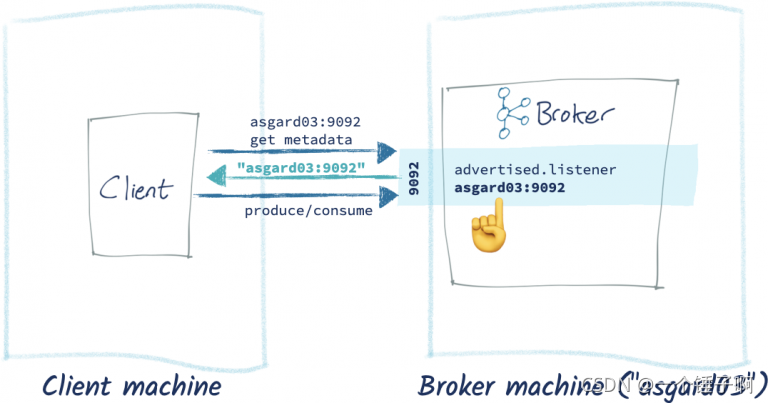
配置后的流程图如下:
返回的元数据中包含客户端机器客解析的hostname,故能正确消费
情况3:客户端和kafka运行在docker中
由于默认配置会返回localhost:9092这样的配置,众所周知,在docker中不同的container沟通是通过docker network,所以需要把返回的hostname改成kafka所在容器的容器名(默认的hostname和容器名一样,如果自定义了则改成自己指定的hostname)
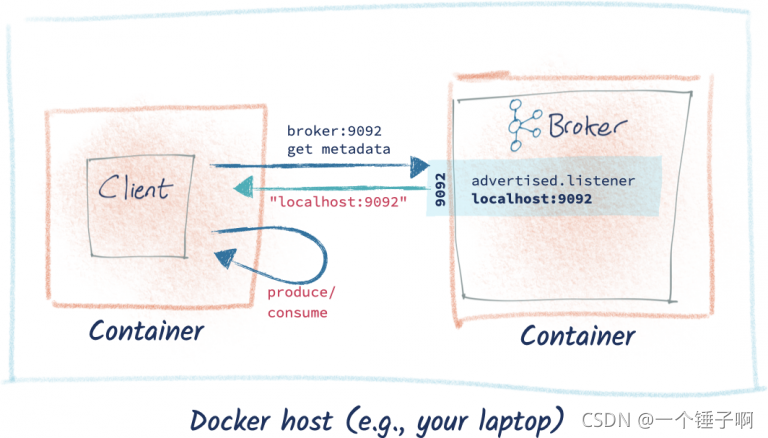
-e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://localhost:9092 \
改成
-e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://broker:9092 \
你看他们又可以快乐玩耍了
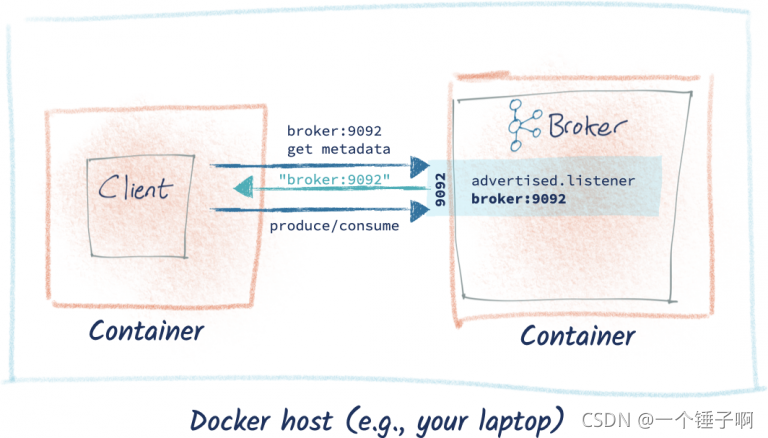
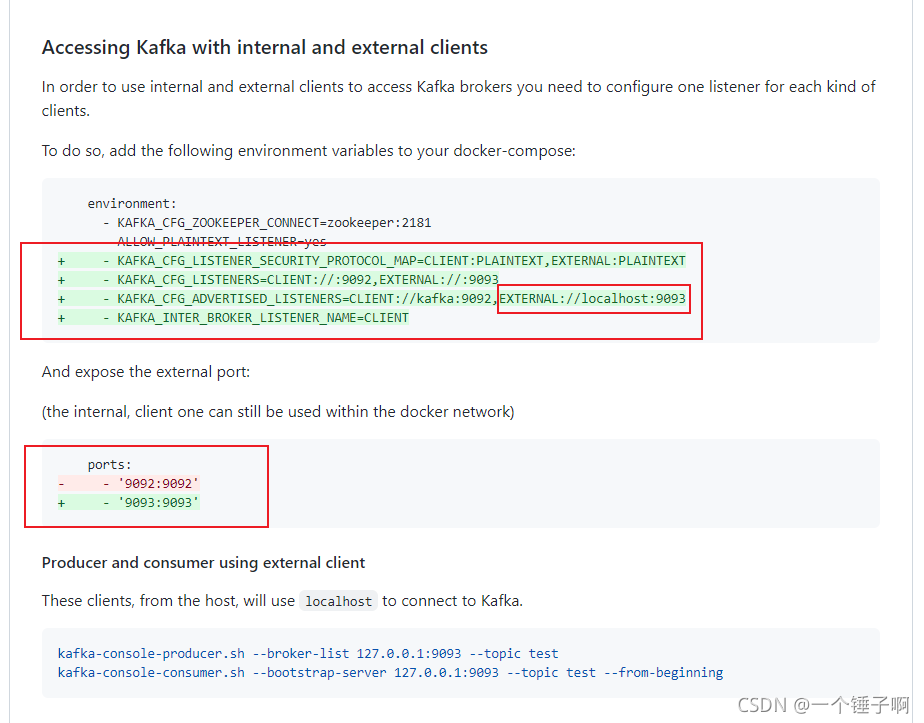
情况4:使用docker-compose构建kafka
参考dockerhub上的说明文档
关键如下,有两个listener,分别叫client和external,client用于内部,external用于外部客户端,外部的客户端连接9093端口即可
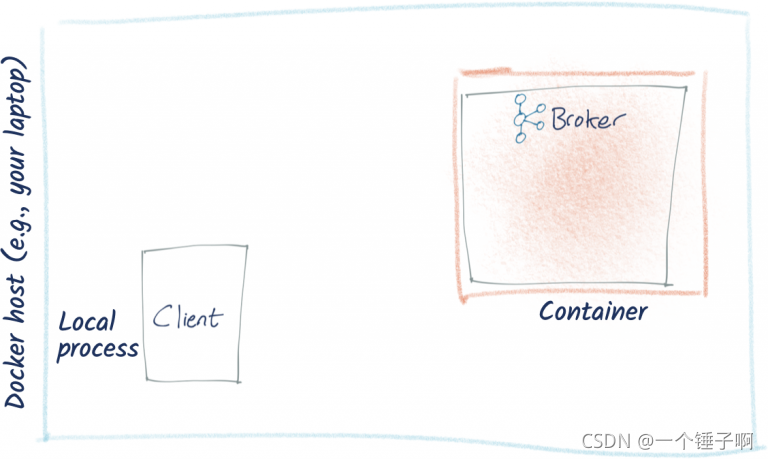
情况5:kafka在docker中,客户端在本地机器
kafka运行在docker中,有一个本地的客户端需要连接到docker中的broker,结构如下
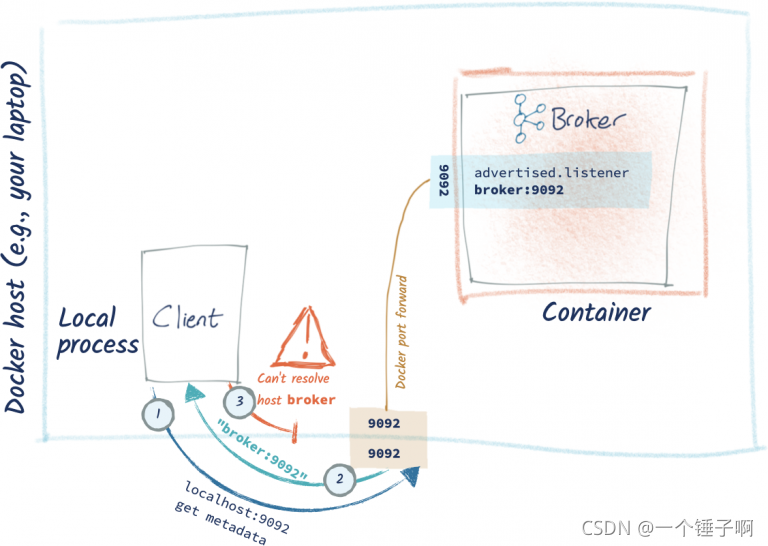
如果直接连接,结果如下,再返回的元数据中hostname是docker容器名,这样的host肯定不能解析,所以报错
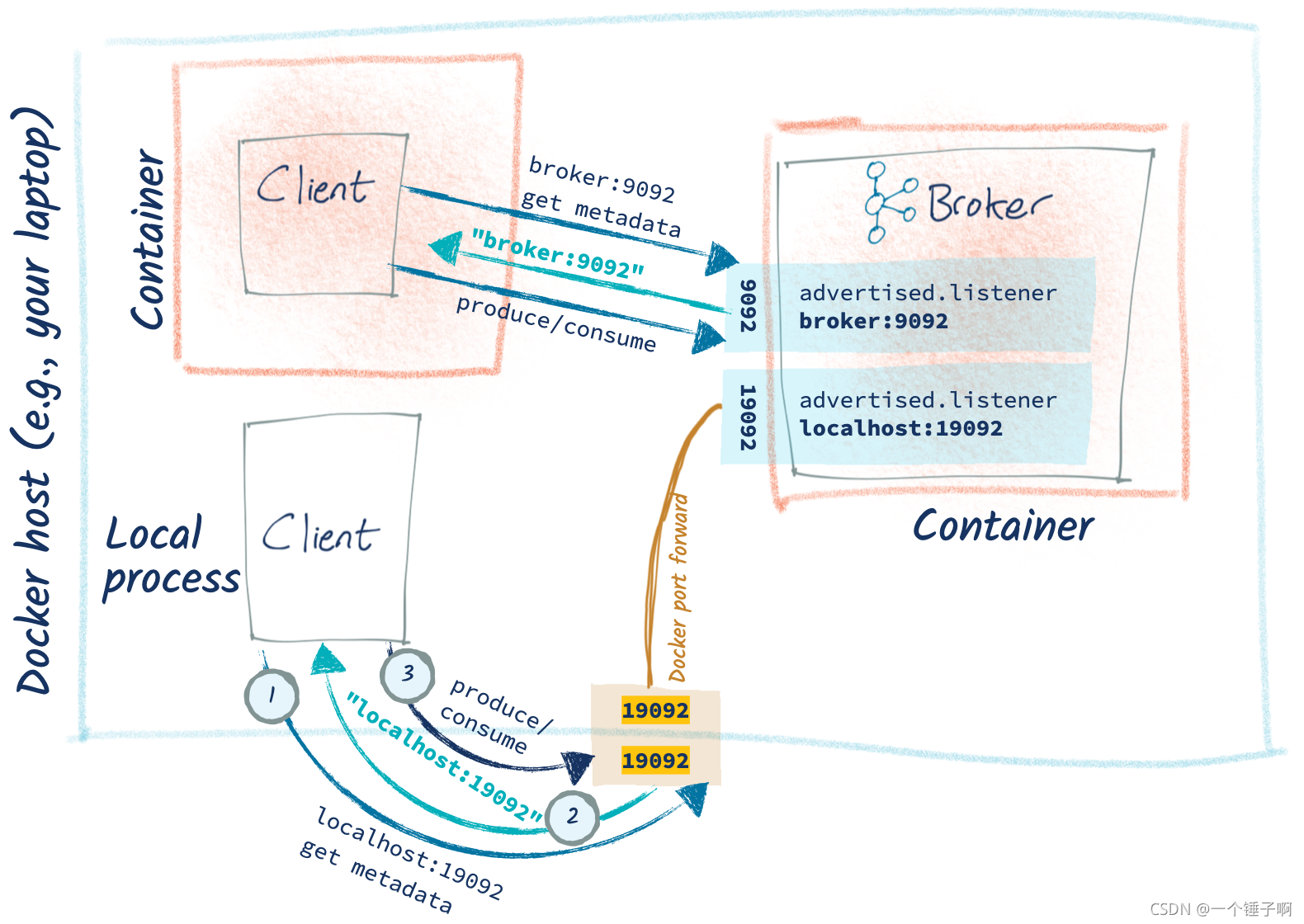
解决办法是增加一个listener
…
ports:
- "19092:19092"
environment:
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://broker:9092,CONNECTIONS_FROM_HOST://localhost:19092
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,CONNECTIONS_FROM_HOST:PLAINTEXT
…
注意客户端连接到新的端口上
情况6:kafka在本地主机上,客户端在docker中
不要这样干。解决办法移步原文。

















 2541
2541

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









